溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“IO底層原理的示例分析”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“IO底層原理的示例分析”這篇文章吧。
IO是Input和Output的縮寫,即輸入和輸出。廣義上的圍繞計算機的輸入輸出有很多:鼠標、鍵盤、掃描儀等等。而我們今天要探討的是在計算機里面,主要是作用在內存、網卡、硬盤等硬件設備上的輸入輸出操作。
談起IO的模型,大多數人腦子里肯定是一坨混亂的概念,“阻塞”、“非阻塞”,“同步”、“異步”有什么區別?很多同學傻傻分不清,有嘗試去搜索相關資料去探究真相,結果又被淹沒在茫茫的概念之中。
這里嘗試簡單地去解釋下為啥會出現這種現象,其中一個很重要的原因就是大家看到的資料對概念的解釋都站在了不同的角度,有的站在了底層內核的視角,有的直接在java層面或者Netty框架層面給大家介紹API,所以給大家造成了一定程度的困擾。
所以在開篇之前,還是要說下本文所站的視角,我們將會從底層內核的層面給大家講解下IO。因為萬變不離其宗,只有了解了底層原理,不管語言層面如何花里胡哨,我們都能以不變應萬變。
為了便于大家理解復雜的IO以及零拷貝相關的技術,我們還是得花點時間在回顧下操作系統相關的知識。這一節我們重點看下用戶空間和內核空間,基于此后面我們才能更好地聊聊多路復用和零拷貝。
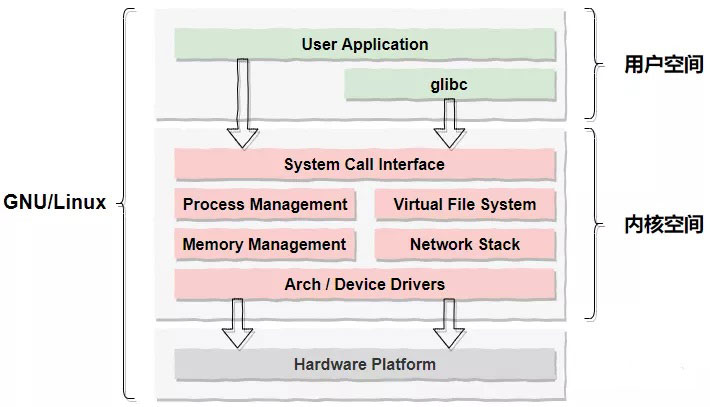
硬 件 層(Hardware)
包括和我們熟知的和IO相關的CPU、內存、磁盤和網卡幾個硬件;
內核空間(Kernel Space)
計算機開機后首先會運行內核程序,內核程序占用的一塊私有的空間就是內核空間,并且可支持訪問CPU所有的指令集(ring0 - ring3)以及所有的內存空間、IO及硬件設備;
用戶空間(User Space)
每個普通的用戶進程都有一個單獨的用戶空間,用戶空間只能訪問受限的資源(CPU的“保護模式”)也就是說用戶空間是無法直接操作像內存、網卡和磁盤等硬件的;
如上所述,那我們可能會有疑問,用戶空間的進程想要去訪問或操作磁盤和網卡該怎么辦呢?
為此,操作系統在內核中開辟了一塊唯一且合法的調用入口“System Call Interface”,也就是我們常說的系統調用,系統調用為上層用戶提供了一組能夠操作底層硬件的API。這樣一來,用戶進程就可以通過系統調用訪問到操作系統內核,進而就能夠間接地完成對底層硬件的操作。這個訪問的過程也即用戶態到內核態的切換。常見的系統調用有很多,比如:內存映射mmap()、文件操作類的open()、IO讀寫read()、write()等等。
我們先看一下大家都熟悉的BIO模型的 Java 偽代碼:
ServerSocket serverSocket = new ServerSocket(8080); // step1: 創建一個ServerSocket,并監聽8080端口
while(true) { // step2: 主線程進入死循環
Socket socket = serverSocket.accept(); // step3: 線程阻塞,開啟監聽
BufferedReader reader = new BufferedReader(nwe InputStreamReader(socket.getInputStream()));
System.out.println("read data: " + reader.readLine()); // step4: 數據讀取
PrintWriter print = new PrintWriter(socket.getOutputStream(), true);
print.println("write data"); // step5: socket數據寫入
}這段代碼可以簡單理解成一下幾個步驟:
創建ServerSocket,并監聽8080端口;
主線程進入死循環,用來阻塞監聽客戶端的連接,socket.accept();
數據讀取,socket.read();
寫入數據,socket.write();
問題:
以上三個步驟:accept(...)、read(...)、write(...)都會造成線程阻塞。上述這個代碼使用了單線程,會導致主線程會直接夯死在阻塞的地方。
優化:
我們要知道一點“進程的阻塞是不會消耗CPU資源的”,所以在多核的環境下,我們可以創建多線程,把接收到的請求拋給多線程去處理,這樣就有效地利用了計算機的多核資源。甚至為了避免創建大量的線程處理請求,我們還可以進一步做優化,創建一個線程池,利用池化技術,對暫時處理不了的請求做一個緩沖。
“C10K”即“client 10k”用來指代數量龐大的客戶端;
BIO看上去非常的簡單,事實上采用“BIO+線程池”來處理少量的并發請求還是比較合適的,也是最優的。但是面臨數量龐大的客戶端和請求,這時候使用多線程的弊端就逐漸凸顯出來了:
嚴重依賴線程,線程還是比較耗系統資源的(一個線程大約占用1M的空間);
頻繁地創建和銷毀代價很大,因為涉及到復雜的系統調用;
線程間上下文切換的成本很高,因為發生線程切換前,需要保留上一個任務的狀態,以便切回來的時候,可以再次加載這個任務的狀態。如果線程數量龐大,會造成線程做上下文切換的時間甚至大于線程執行的時間,CPU負載變高。
下面開始真正走向Java NIO或者Netty框架所描述的“非阻塞”,NIO叫Non-Blocking IO或者New IO,由于BIO可能會引入的大量線程,所以可以簡單地理解NIO處理問題的方式是通過單線程或者少量線程達到處理大量客戶端請求的目的。為了達成這個目的,首先要做的就是把阻塞的過程非阻塞化。要想做到非阻塞,那必須得要有內核的支持,同時需要對用戶空間的進程暴露系統調用函數。所以,這里的“非阻塞”可以理解成系統調用API級別的,而真正底層的IO操作都是阻塞的,我們后面會慢慢介紹。
事實上,內核已經對“非阻塞”做好了支持,舉個我們剛剛說的的accept()方法阻塞的例子(Tips:java中的accept方法對應的系統調用函數也叫accept),看下官方文檔對其非阻塞部分的描述。
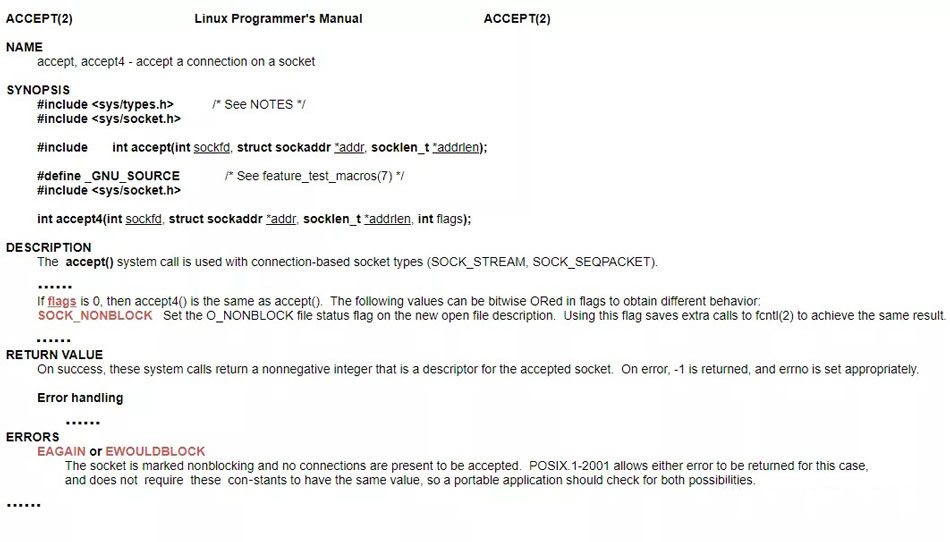
官方文檔對accetp()系統調用的描述是通過把"flags"參數設成"SOCK_NONBLOCK"就可以達到非阻塞的目的,非阻塞之后線程會一直處理輪詢調用,這時候可以通過每次返回特殊的異常碼“EAGAIN”或"EWOULDBLOCK"告訴主程序還沒有連接到達可以繼續輪詢。
我們可以很容易想象程序非阻塞之后的一個大致過程。所以,非阻塞模式有個最大的特點就是:用戶進程需要不斷去主動詢問內核數據準備好了沒有!
下面我們通過一段偽代碼,看下這個調用過程:
// 循環遍歷
while(1) {
// 遍歷fd集合
for (fdx in range(fd1, fdn)) {
// 如果fdx有數據
if (null != fdx.data) {
// 進行讀取和處理
read(fdx)&handle(fdx);
}
}
}這種調用方式也暴露出非阻塞模式的最大的弊端,就是需要讓用戶進程不斷切換到內核態,對連接狀態或讀寫數據做輪詢。有沒有一種方式來簡化用戶空間for循環輪詢的過程呢?那就是我們下面要重點介紹的IO多路復用模型。
非阻塞模型會讓用戶進程一直輪詢調用系統函數,頻繁地做內核態切換。想要做優化其實也比較簡單,我們假想個業務場景,A業務系統會調用B的基礎服務查詢單個用戶的信息。隨著業務的發展,A的邏輯變復雜了,需要查100個用戶的信息。很明顯,A希望B提供一個批量查詢的接口,用集合作為入參,一次性把數據傳遞過去就省去了頻繁的系統間調用。
多路復用實際也差不多就是這個實現思路,只不過入參這個“集合”需要你注冊/填寫感興趣的事件,讀fd、寫fd或者連接狀態的fd等,然后交給內核幫你進行處理。
那我們就具體來看看多路復用里面大家都可能聽過的幾個系統調用- select()、poll()、epoll()。
select()構造函數信息如下所示:
/** * select()系統調用 * * 參數列表: * nfds - 值為最大的文件描述符+1 * *readfds - 用戶檢查可讀性 * *writefds - 用戶檢查可寫性 * *exceptfds - 用于檢查外帶數據 * *timeout - 超時時間的結構體指針 */ int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
官方文檔對select()的描述:
DESCRIPTION
select() and pselect() allow a program to monitor multiple file descriptors, waiting until one or more of the file descriptors become "ready" for some class of I/O operation (e.g.,input possible). A file descriptor is considered ready if it is possible to perform the corresponding I/O operation (e.g., read(2)) without blocking.
select()允許程序監控多個fd,阻塞等待直到一個或多個fd到達"就緒"狀態。
內核使用select()為用戶進程提供了類似批量的接口,函數本身也會一直阻塞直到有fd為就緒狀態返回。下面我們來具體看下select()函數實現,以便我們更好地分析它有哪些優缺點。在select()函數的構造器里,我們很容易看到"fd_set"這個入參類型。它是用位圖算法bitmap實現的,使用了一個大小固定的數組(fd_set設置了FD_SETSIZE固定長度為1024),數組中的每個元素都是0和1這樣的二進制byte,0,1映射fd對應位置上是否有讀寫事件,舉例:如果fd == 5,那么fd_set = 000001000。
同時fd_set定義了四個宏來處理bitmap:
FD_ZERO(&set);// 初始化,清空的作用,使集合中不含任何fd
FD_SET(fd, &set);//將fd加入set集合,給某個位置賦值的操作
FD_CLR(fd, &set);//將fd從set集合中清除,去掉某個位置的值
FD_ISSET(fd, &set);//校驗某位置的fd是否在集合中
使用bitmap算法的好處非常明顯,運算效率高,占用內存少(使用了一個byte,8bit)。我們用偽代碼和圖片來描述下用戶進程調用select()的過程:
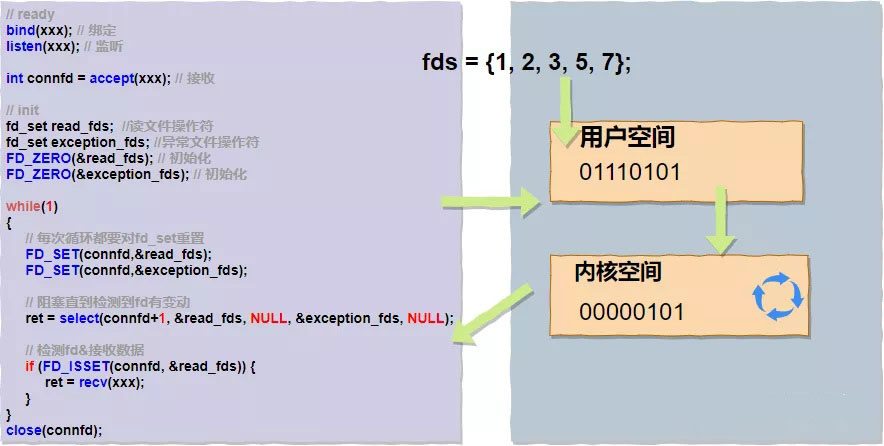
假設fds為{1, 2, 3, 5, 7}對應的bitmap為"01110101",拋給內核空間輪詢,當有讀寫事件時重新標記同時停止阻塞,然后整體返回用戶空間。由此我們可以看到select()系統調用的弊端也是比較明顯的:
復雜度O(n),輪詢的任務交給了內核來做,復雜度并沒有變化,數據取出后也需要輪詢哪個fd上發生了變動;
用戶態還是需要不斷切換到內核態,直到所有的fds數據讀取結束,整體開銷依然很大;
fd_set有大小的限制,目前被硬編碼成了1024;
fd_set不可重用,每次操作完都必須重置;
poll()構造函數信息如下所示:
/**
* poll()系統調用
*
* 參數列表:
* *fds - pollfd結構體
* nfds - 要監視的描述符的數量
* timeout - 等待時間
*/
int poll(struct pollfd *fds, nfds_t nfds, int *timeout);
### pollfd的結構體
struct pollfd{
int fd;// 文件描述符
short event;// 請求的事件
short revent;// 返回的事件
}官方文檔對poll()的描述:
DESCRIPTION
poll() performs a similar task to select(2): it waits for one of a set of file descriptors to become ready to perform I/O.
poll() 非常像select(),它也是阻塞等待直到一個或多個fd到達"就緒"狀態。
看官方文檔描述可以知道,poll()和select()是非常相似的,唯一的區別在于poll()摒棄掉了位圖算法,使用自定義的結構體pollfd,在pollfd內部封裝了fd,并通過event變量注冊感興趣的可讀可寫事件(POLLIN、POLLOUT),最后把pollfd交給內核。當有讀寫事件觸發的時候,我們可以通過輪詢pollfd,判斷revent確定該fd是否發生了可讀可寫事件。
老樣子我們用偽代碼來描述下用戶進程調用poll()的過程:

poll()相對于select(),主要的優勢是使用了pollfd的結構體:
沒有了bitmap大小1024的限制;
通過結構體中的revents置位;
但是用戶態到內核態切換及O(n)復雜度的問題依舊存在。
epoll()應該是目前最主流,使用范圍最廣的一組多路復用的函數調用,像我們熟知的Nginx、Redis都廣泛地使用了此種模式。接下來我們重點分析下,epoll()的實現采用了“三步走”策略,它們分別是epoll_create()、epoll_ctl()、epoll_wait()。
/** * 返回專用的文件描述符 */ int epoll_create(int size);
用戶進程通過epoll_create()函數在內核空間里面創建了一塊空間(為了便于理解,可以想象成創建了一塊白板),并返回了描述此空間的fd。
/** * epoll_ctl()系統調用 * * 參數列表: * epfd - 由epoll_create()返回的epoll專用的文件描述符 * op - 要進行的操作例如注冊事件,可能的取值:注冊-EPOLL_CTL_ADD、修改-EPOLL_CTL_MOD、刪除-EPOLL_CTL_DEL * fd - 關聯的文件描述符 * event - 指向epoll_event的指針 */ int epoll_ctl(int epfd, int op, int fd , struce epoll_event *event );
剛剛我們說通過epoll_create()可以創建一塊具體的空間“白板”,那么通過epoll_ctl()我們可以通過自定義的epoll_event結構體在這塊"白板上"注冊感興趣的事件了。
注冊 - EPOLL_CTL_ADD
修改 - EPOLL_CTL_MOD
刪除 - EPOLL_CTL_DEL
/** * epoll_wait()返回n個可讀可寫的fds * * 參數列表: * epfd - 由epoll_create()返回的epoll專用的文件描述符 * epoll_event - 要進行的操作例如注冊事件,可能的取值:注冊-EPOLL_CTL_ADD、修改-EPOLL_CTL_MOD、刪除-EPOLL_CTL_DEL * maxevents - 每次能處理的事件數 * timeout - 等待I/O事件發生的超時值;-1相當于阻塞,0相當于非阻塞。一般用-1即可 */ int epoll_wait(int epfd, struce epoll_event *event , int maxevents, int timeout);
epoll_wait()會一直阻塞等待,直到硬盤、網卡等硬件設備數據準備完成后發起硬中斷,中斷CPU,CPU會立即執行數據拷貝工作,數據從磁盤緩沖傳輸到內核緩沖,同時將準備完成的fd放到就緒隊列中供用戶態進行讀取。用戶態阻塞停止,接收到具體數量的可讀寫的fds,返回用戶態進行數據處理。
整體過程可以通過下面的偽代碼和圖示進一步了解:
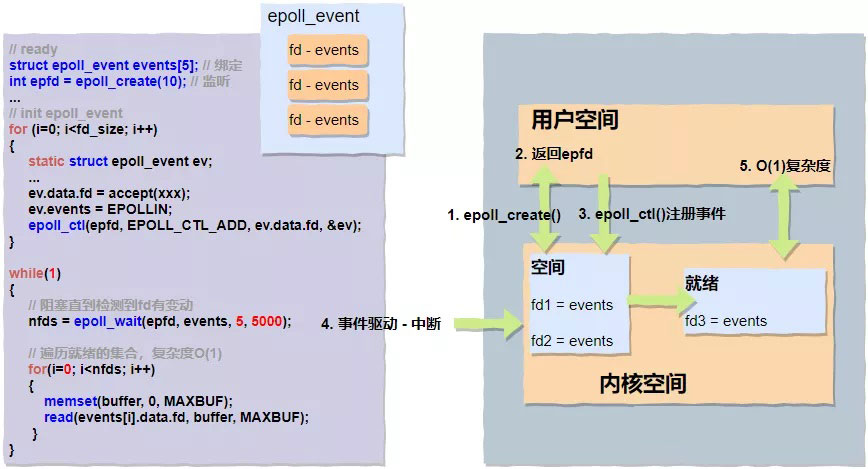
epoll()基本上完美地解決了poll()函數遺留的兩個問題:
沒有了頻繁的用戶態到內核態的切換;
O(1)復雜度,返回的"nfds"是一個確定的可讀寫的數量,相比于之前循環n次來確認,復雜度降低了不少;
細心的朋友可能會發現,本篇文章一直在解釋“阻塞”和“非阻塞”,“同步”、“異步”的概念沒有涉及,其實在很多場景下同步&異步和阻塞&非阻塞基本上是一個同義詞。阻塞和非阻塞適合從系統調用API層面來看,就像我們本文介紹的select()、poll()這樣的系統調用,同步和異步更適合站在應用程序的角度來看。應用程序在同步執行代碼片段的時候結果不會立即返回,這時候底層IO操作不一定是阻塞的,也完全有可能是非阻塞。所以說:
阻塞和非阻塞:讀寫沒有就緒或者讀寫沒有完成,函數是否要一直等待還是采用輪詢;
同步和異步:同步是讀寫由應用程序完成。異步是讀寫由操作系統來完成,并通過回調的機制通知應用程序。
這邊順便提兩種大家可能會經常聽到的模式:Reactor和Preactor。
Reactor 模式:主動模式。
Preactor 模式:被動模式。
以上是“IO底層原理的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





