溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Parquet性能測試調優及其優化建議
一、我們為什么選擇parquet
1、選擇parquet的外部因素
(1) 我們已經在使用spark集群,spark原本就支持parquet,并推薦其存儲格式(默認存儲為parquet);
(2) hive支持parquet格式存儲,使用HiveSql查詢也是完全兼容的。
2、選擇parquet的本身原因
(1) parquet由于每一列的成員都是同構的,可以針對不同的數據類型使用更高效的數據壓縮算法,進一步減小I/O。CSV格式一般不進行壓縮,通過parquet存儲數據有效的節約了空間,不考慮備份情況下,壓縮比將近27倍(parquet有四種壓縮方式lzo、gzip、snappy、uncompressed,其中默認gzip的壓縮方式,其壓縮率最高,壓縮解壓的速率最快);
(2) 查詢的時候不需要掃描全部的數據,而只需要讀取每次查詢涉及的列,這樣可以將I/O消耗降低N倍,另外可以保存每一列的統計信息(min、max、sum等);
(3) 分區過濾與列修剪中,parquet結合spark可以實現分區過濾(spark sql,rdd的filter和where關鍵字),列修剪即獲取所需要的列,列數越少查詢的速率也就也快;
由于每一列的成員的同構性,可以使用更加適合CPU pipeline的編碼方式,減小CPU的緩存失效。
parquet的列式存儲格式的解析(僅了解)
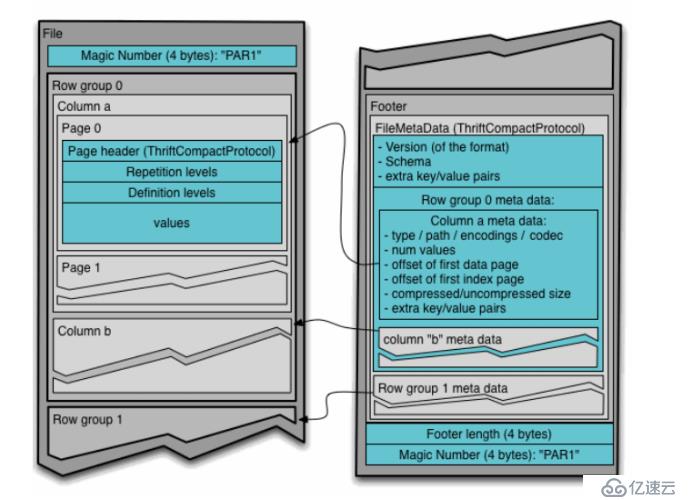
Parquet文件在磁盤上的分布情況如上圖,所有的數據被水平切分成Row group,一個Row group包含這個Row group對應的區間內的所有列的column chunk 。一個column chunk負責存儲某一列的數據,這些數據是這一列的Repetition level,Definition level和Values。一個column chunk是由Page組成的,Page是壓縮和編碼的單元,對數據模型來說是透明的。一個Parquet文件最后是Footer,存儲了文件的元數據信息和統計信息。Row group是數據讀寫時候的緩存單元,所以推薦設置較大的Row group從而帶來較大的并行度,當然也需要較大的內存空間作為代價。一般情況下推薦配置一個Row group大小1G,一個HDFS塊大小1G,一個HDFS文件只含有一個塊。
Parquet性能測試
(1)測試普通文件和parquet文件讀取列的性能
①測試環境:58.56機器、spark1.6、sts、hive等
②測試目的:驗證spark在讀取普通文件和parquet文件性能時,在讀取相同的列的速率上面,比普通的文件效率更高,隨著列的增加讀取的效率會降低。
③測試原理:
由于以下特性,使得列式存儲對于一些運算速率相對行式存儲運行速率更快:
(1)由于每一列的成員都是同構的,可以針對不同的數據類型使用更高效的數據壓縮算法,進一步減小I/O。
(2)由于每一列的成員的同構性,可以使用更加適合CPU pipeline的編碼方式,減小CPU的緩存失效。
④測試步驟
(1)使用C_PORT表建立hive表,同樣建立一個C_PORT_PARQUET,使用stored as parquet將表存儲為parquet格式;
(2)編寫spark讀取語句,對列數進行查詢讀取操作;
(3)增加讀取列數,在機器上spark提交任務運行記錄運行時間;
(4)對比運行時間,得出最終結論。
⑤測試結果
約27005w數據 普通hive表 request表 測試結果:
查詢列數 | 普通hive表耗時 | Parquet表耗時 |
1列 | 2分53秒 | 2分42秒 |
5列 | 3分53秒 | 1分27秒 |
20列 | 5分58秒 | 3分56秒 |
35列 | 9分16秒 | 9分36秒 |
50列 | 13分19秒 | 8分11秒 |
⑥總結結論
通過以上五組數據列的讀取得知,隨著列數的增加,讀取的時間增加,相對于parquet和普通hive的讀取速率相近,由此在列數較多時,讀取非全部列數據,建議使用parquet存儲可以增加讀取效率。
(2)測試parquet列式存儲在對多列數據進行列式計算的效率
①測試環境:58.56機器、spark1.6、sts、hive等
②測試目的:驗證spark在讀取普通文件和parquet文件性能時,針對某些列式運算列式存儲的性能更佳,即讀取計算速率更快。
③測試原理:
由于以下特性,使得列式存儲對于一些運算速率相對行式存儲運行速率更快:
(1)查詢的時候不需要掃描全部的數據,而只需要讀取每次查詢涉及的列,這樣可以將I/O消耗降低N倍,另外可以保存每一列的統計信息(min、max、sum等),實現部分的謂詞下推。
(2)由于每一列的成員都是同構的,可以針對不同的數據類型使用更高效的數據壓縮算法,進一步減小I/O。
(3)由于每一列的成員的同構性,可以使用更加適合CPU pipeline的編碼方式,減小CPU的緩存失效。
④測試步驟
(1)使用C_PORT表建立hive表,同樣建立一個C_PORT_PARQUET,使用stored as parquet將表存儲為parquet格式;
(2)編寫spark讀取語句,包含列式計算的sum,avg以及max,min語句;
(3)在機器上spark提交任務運行記錄運行時間;
(4)對比運行時間,得出最終結論。
⑤測試結果
第一組:
約27005w數據 普通hive表 request表 (按照每天小時分組,2個求和,3個求平均運算)
測試結果:
時間 | 普通hive表 | Parquet表 |
耗時 | 2分14秒 | 1分37秒 |
耗時 | 2分24秒 | 1分08秒 |
耗時 | 2分27秒 | 1分36秒 |
平均耗時 | 2分33秒 | 1分27秒 |
第二組:
約27005w數據 普通hive表 request表 (按照每天小時分組,2個求和,3個求平均運算,2求最大值,2個求最小值)
測試結果:
時間 | 普通hive表 | Parquet表 |
耗時 | 2分22秒 | 1分38秒 |
耗時 | 2分58秒 | 1分51秒 |
耗時 | 2分31秒 | 1分38秒 |
平均耗時 | 2分37秒 | 1分42秒 |
第三組:
約27005w數據 普通hive表 request表 (按照每天小時分組,4個求和,4個求平均運算,4求最大值,4個求最小值)
測試結果:
時間 | 普通hive表 | Parquet表 |
耗時 | 3分03秒 | 1分58秒 |
耗時 | 2分45秒 | 2分03秒 |
耗時 | 2分48秒 | 2分06秒 |
平均耗時 | 2分52秒 | 2分02秒 |
⑥總結結論
通過三組數值的比對計算,列式存儲格式parquet針對列式計算效率比普通的行式存儲有明顯的優勢,運算的效率提升在30%-40%左右,效率更高,執行效率更快。
測試普通文件和parquet文件的壓縮效率對比
①測試環境:58.56機器、spark1.6、sts、hive等
②測試目的:驗證測試普通文件和parquet文件的壓縮效率對比,在壓縮存儲相同數據時,存儲為parquet文件壓縮效率更高,占用的空間更小。
③測試原理:
(1)由于每一列的成員都是同構的,可以針對不同的數據類型使用更高效的數據壓縮算法,進一步減小I/O。
(2)由于每一列的成員的同構性,可以使用更加適合CPU pipeline的編碼方式,減小CPU的緩存失效。
④測試步驟
(1)同樣的SparkSql運行,存儲方式不同。生成相同數據量的parquet文件和普通文件存儲;
(2)分別查看生成的Parquet文件和普通文件的大小,對比結果。
⑤測試結果
結果如下圖:
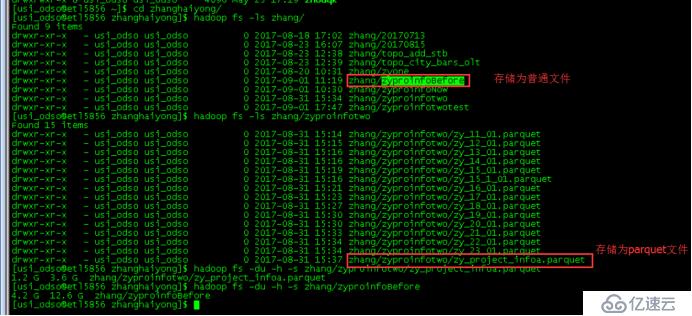
經過最終執行結果,存儲為普通文件的總大小為12.6G,存儲為parquet文件的大小為3.6G,存儲所占空間減少了近70%,因此存儲為parquet文件占用的空間更小。
四、Parquet在實際項目中的應用建議
(1)當讀取的列數并非全部列數,建議使用parquet格式存儲(建表時使用stored by parquet);
(2)在進行列式計算或者向量計算時,建議也使用parquet格式存儲,可以提高運算效率;
(3)如果有文件需要備份存儲,可以使用parquet文件進行壓縮,可以有效的節約空間,提高壓縮效率和速率。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





