溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹大數據系統架構怎么理解,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
大數據的應用開發過于偏向底層,具有學習難度大,涉及技術面廣的問題,這制約了大數據的普及。現在需要一種技術,把大數據開發中一些通用的,重復使用的基礎代碼、算法封裝為類庫,降低大數據的學習門檻,降低開發難度,提高大數據項目的開發效率。
大數據在工作中的應用有三種:與業務相關,比如用戶畫像、風險控制等;
與決策相關,數據科學的領域,了解統計學、算法,這是數據科學家的范疇;與工程相關,如何實施、如何實現、解決什么業務問題,這是數據工程師的工作。
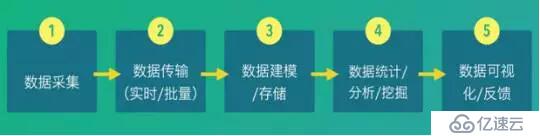
數據源的特點決定數據采集與數據存儲的技術選型,我根據數據源的特點將其分為四大類:
第一類:從來源來看分為內部數據和外部數據;
第二類:從結構來看分為非結構化數據和結構化數據;
第三類:從可變性來看分為不可變可添加數據和可修改刪除數據;
第四類,從規模來看分為大量數據和小量數據。
大數據平臺第一個要素就是數據源,我們要處理的數據源往往是在業務系統上,數據分析的時候可能不會直接對業務的數據源進行處理,而是先經過數據采集、數據存儲,之后才是數據分析和數據處理。
從整個大的生態圈可以看出,要完成數據工程需要大量的資源;數據量很大需要集群;要控制和協調這些資源需要監控和協調分派;面對大規模的數據怎樣部署更方便更容易;還牽扯到日志、安全、還可能要和云端結合起來,這些都是大數據圈的邊緣,同樣都很重要。
大快大數據平臺(DKH),是大快公司為了打通大數據生態系統與傳統非大數據公司之間的通道而設計的一站式搜索引擎級,大數據通用計算平臺。傳統公司通過使用DKH,可以輕松的跨越大數據的技術鴻溝,實現搜索引擎級的大數據平臺性能。
DKH,有效的集成了整個HADOOP生態系統的全部組件,并深度優化,重新編譯為一個完整的更高性能的大數據通用計算平臺,實現了各部件的有機協調。因此DKH相比開源的大數據平臺,在計算性能上有了高達5倍(最大)的性能提升。
DKH,更是通過大快獨有的中間件技術,將復雜的大數據集群配置簡化至三種節點(主節點、管理節點、計算節點),極大的簡化了集群的管理運維,增強了集群的高可用性、高可維護性、高穩定性。
DKH,雖然進行了高度的整合,但是仍然保持了開源系統的全部優點,并與開源系統100%兼容,基于開源平臺開發的大數據應用,無需經過任何改動,即可在DKH上高效運行,并且性能會有最高5倍的提升。
DKH,更是集成了大快的大數據一體化開發框架(FreeRCH), FreeRCH開發框架提供了大數據、搜索、自然語言處理和人工智能開發中常用的二十多個類,通過總計一百余種方法,實現了10倍以上的開發效率的提升。
DKH的SQL版本,還提供了分布式MySQL的集成,傳統的信息系統,可無縫的實現面向大數據和分布式的跨越。
DKH標準平臺技術構架圖
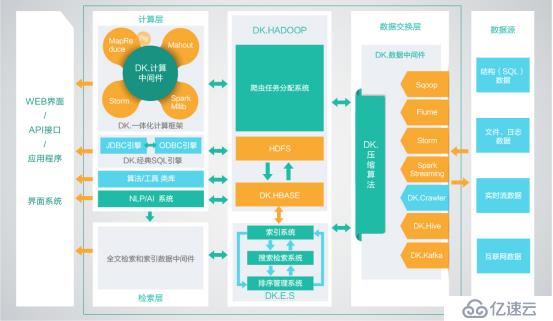
關于大數據系統架構怎么理解就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





