溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“怎么用java做emoji表情”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“怎么用java做emoji表情”吧!
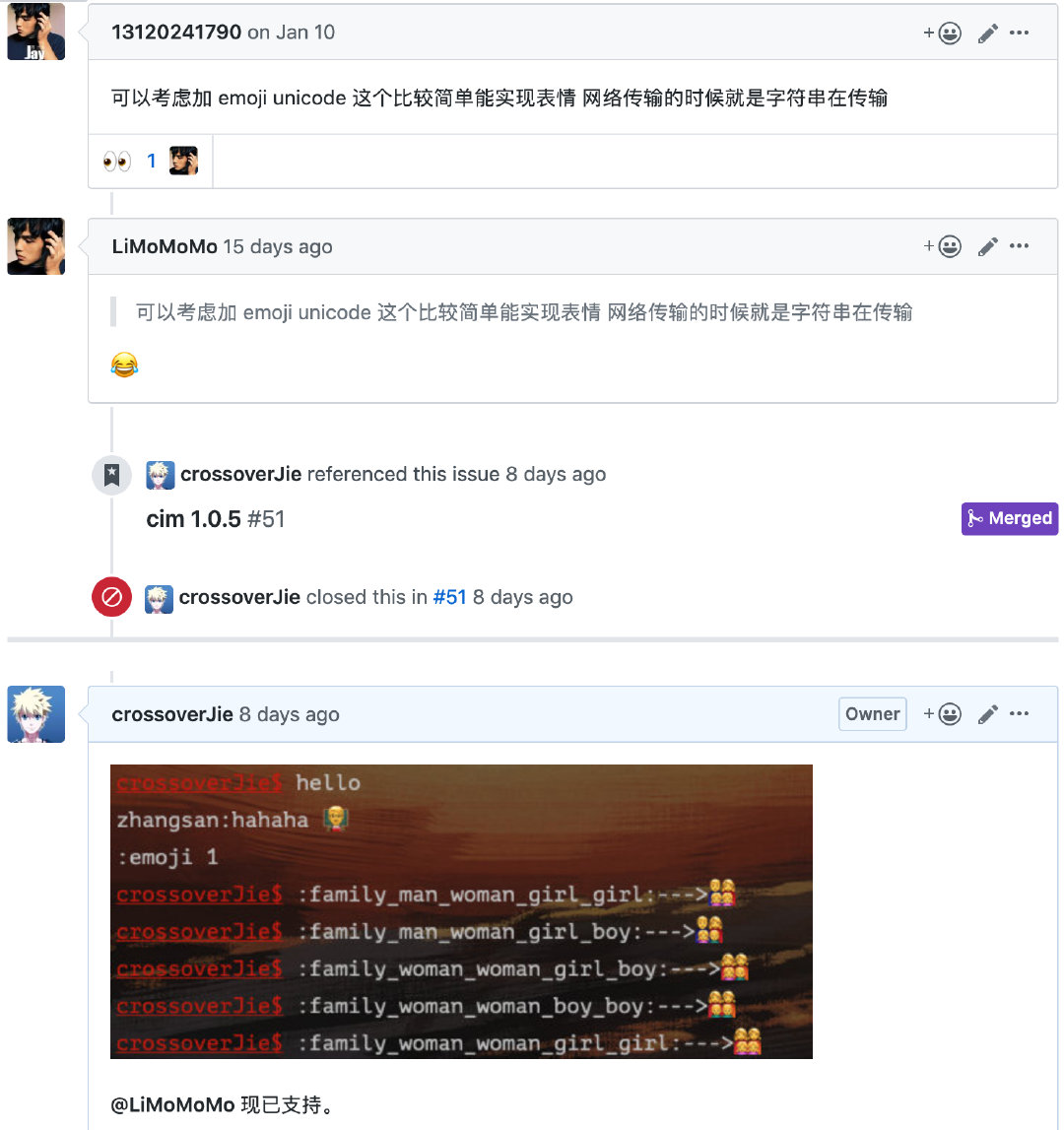
正好那段時間有空,加上這功能看著也比較簡單準備把它實現了。
<!--more-->
但在真正實現時卻發現沒那么簡單。
我首先嘗試將一個 emoji 表情存入數據庫看看:

果不其然的出錯了,導致這個異常的原因是目前數據庫所支持的編碼中并不能存放 emoji,那 emoji 表情到底是個什么東西呢。
本質上來說計算機所存儲的信息都是二進制 01,emoji 也不例外,只要存儲和讀取(編解碼)的方式一致那就可以準確的展示這個信息。
更多編解碼的內容后文再介紹,這里先想想如何快速解決問題。
雖說想要在 MySQL 中存儲 emoji 的方式也有好幾種,比如可以升級存儲字符集到可以存放 emoji ,但這種需要 MySQL 的版本支持。
所以更保險的方式還是在應用層解決,比如我們是否可以將 emoji 當做字符串存儲,只是顯示的時候要格式化為一個 emoji 表情,這樣對于所有的數據庫版本都可兼容。
于是我們這里的需求是一個 emoji 表情轉換為字符串,同時還得將這個字符串轉換為 emoji。
為此我在 GitHub 上找到了一個庫,它可以方便的將一個 emoji 轉換為字符串的別名,同時也支持將這個別名轉換為 emoji。
https://github.com/vdurmont/emoji-java
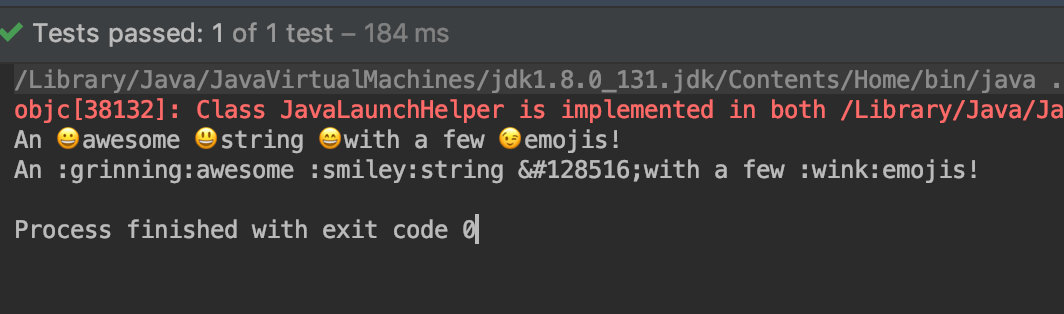
@Test
public void emoji() throws Exception{
String str = "An :grinning:awesome :smiley:string 😄with a few :wink:emojis!";
String result = EmojiParser.parseToUnicode(str);
System.out.println(result);
result = EmojiParser.parseToAliases(str);
System.out.println(result);
}
所以基于這個基礎庫最終實現了表情功能。
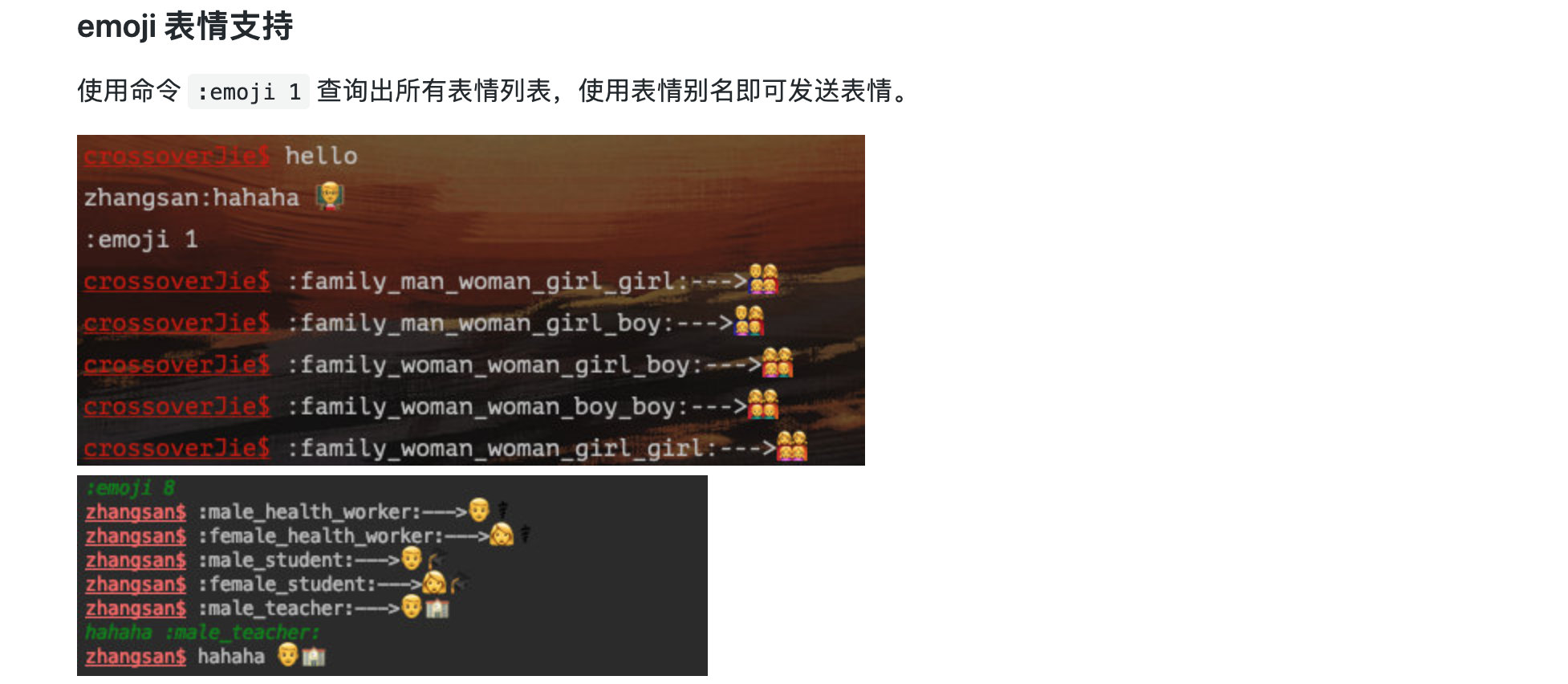
其實它本質上是自己維護了一個 emoji 的別名及它的 Unicode 編碼(本質上是 UTF-16)的映射關系,再每次格式化數據的時候都會從這個表中進行翻譯。
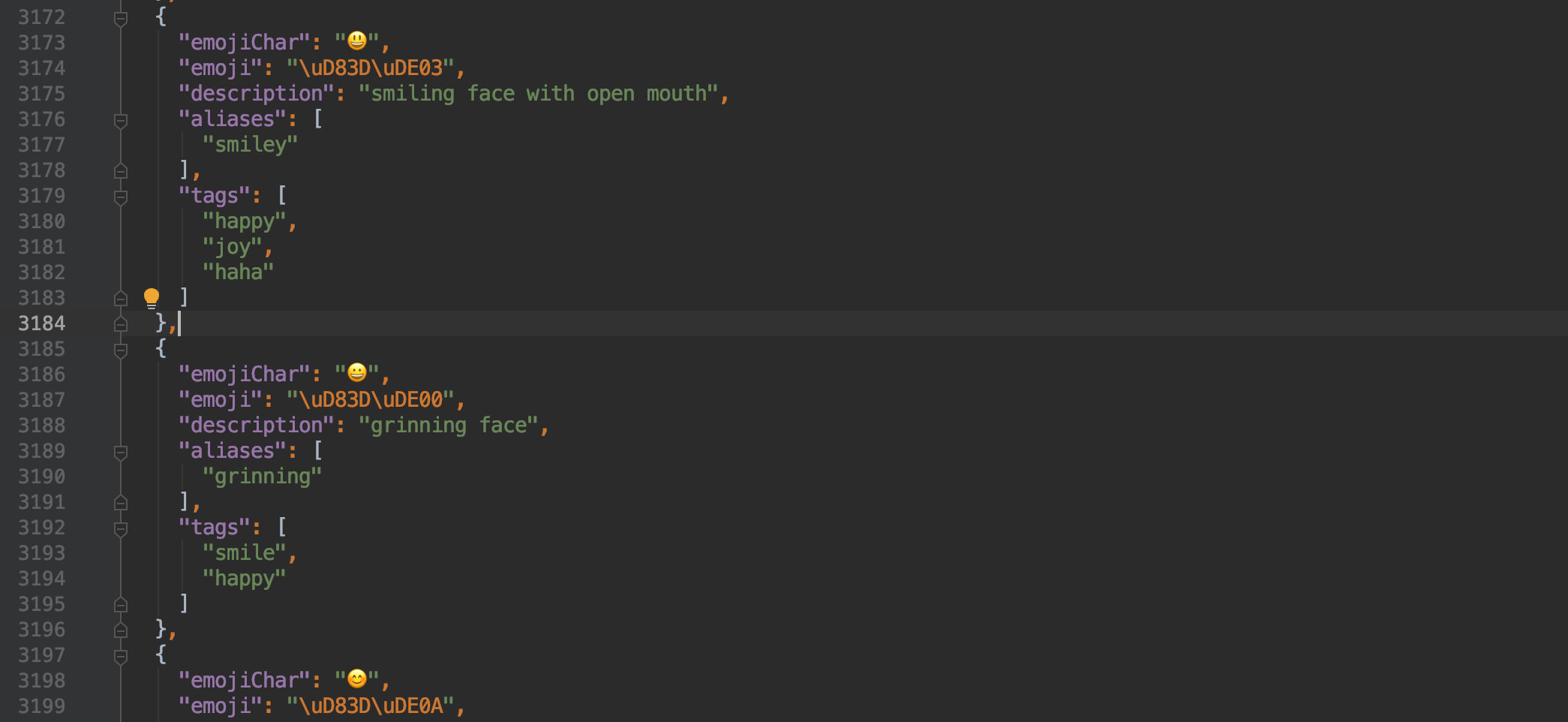
自此需求是完成了,但還有幾個問題待解決。
Java 中是如何存儲 emoji 的?
emoji 是如何進行編碼的?
在談 emoji 之前非常有必要了解下計算機編碼鼻祖的 ASCII 碼。
大家現在都知道在計算機內部存儲數據本質上都是二進制的 0/1,對于一個字節來說有 8 位;每一位可以表示兩種狀態,也就是 0 或 1,這樣排列組合下來,一個字節就可以表示 256(2∧8) 種不同的狀態。

對于美國來說他們日常使用的英語只需要 26 個英文字母,再加上一些標點符號就足夠用計算機來進行信息交流。
于是上個世紀 60年代定義了一套二進制與英文字符的映射關系,可以表明 128 個不同的英文字符,也就是現在的 ASCII 碼。
這樣我們就可以使用一個字節來表示現代英文,看起來非常不錯。
隨著計算機的發展,逐漸在歐洲、亞洲地區流行;再利用這套 ASCII 碼進行信息交流顯然是不行的,很多地區壓根就不使用英文,而且也遠超了 128 位字符(中文就更不用說了)。
雖說一個字節在 ASCII 碼中只用了 128 位,但剩下(258-128)的依然不足用用于描述其他語言。
這時如果能有一種包含了世界上所有的文字的字符集,每一個地區的文字都在這個字符集中有唯一的二進制表示,這樣便不會出現亂碼問題了。
Unicode 就是來做這個的,截止目前 Unicode 已經收錄了 10W+ 的字符,你所能使用的字符都包含進去了。
Unicode 雖說包含了幾乎所有的文字,但在我們日常使用好像很少看到他的身影,我們用的更多的還是 UTF-8 這樣的編碼規則。
這也有幾方面的原因,比如說除開英文,其他大部分的文字都需要用 2 個甚至更多的字節來表示;如果統一都用 Unicode 來表示,那必然需要以占用字節最多的字符長度為標準。
比如漢字需要 2 個字節來表示,而英文只需要一個字節;這時就得規定 2 個字節表示一個字符,不然漢字就沒法表示了。
但這樣也會帶來一個問題:用兩個字節表示英文會使得第一個字節完全是浪費的,如果一段信息全是英文那對內存的浪費是巨大的。
這時大家應該都能想到,我們需要一個可變的長度的字符編碼規則,當是英文時我們就用一個字節表示,甚至可以完全兼容 ASCII 碼。
UTF-8 便是實現這個需求的,它利用兩種規則可以表示一個字節以及多字節的字符。
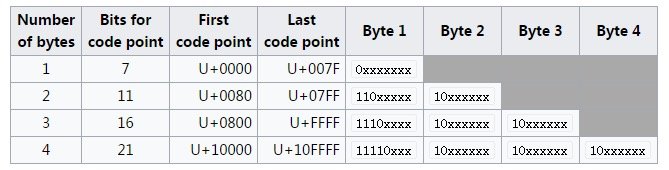
大致規則如下:
當第一個字節的第一位為 0 時便表示為單字節字符,此時和 ASCII 碼一致,完全兼容。
當第一個字節為 1 時,有幾個 1 便代表是幾個字節 Unicode 字符。
這樣便可根據字符的長度最大程度的節省存儲空間。
當然還有其他的編碼規則,比如 UTF-16、UTF-32,平時用的不多,但本質上都和 UTF-8 一樣,都是 Unicode 的不同實現,也是用于表示世界上大部分文字的字符集。
現在來回到本次的主題,emoji。
剛才說到 Unicode 包含了世界上大部分的字符,emoji 自然也不例外。
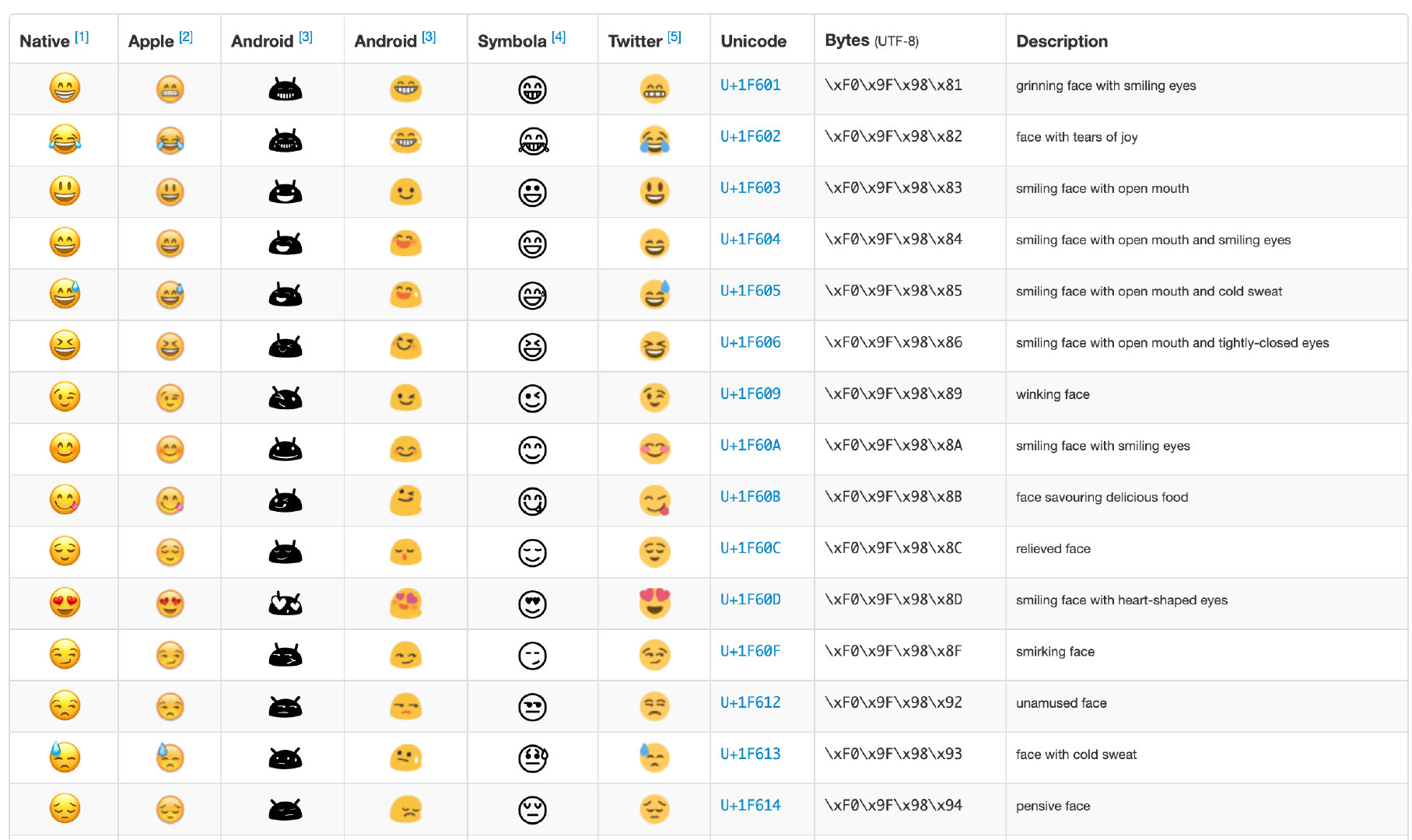
https://apps.timwhitlock.info/emoji/tables/unicode
這個表格中包含了所有的 emoji 以及它所對應的 Unicode 編碼,同時也有對應的 UTF-8 編碼的實現。
從圖中也可以看出 emoji 表情用 UTF-8 表示時會占用 4 個字節,那在 Java 中它會是怎么存儲的呢?
很簡單,debug 一下就知道了。
在 Java 中也是通過 char 來存儲 emoji 的,char 作為基本數據類型會占用 2 個字節;從剛才的圖中可以看出,emoji 使用 UTF-8 會占用四個字節,這樣很明顯 char 是沒法存儲的,所以在這里其實是使用 UTF-16 編碼進行存儲。
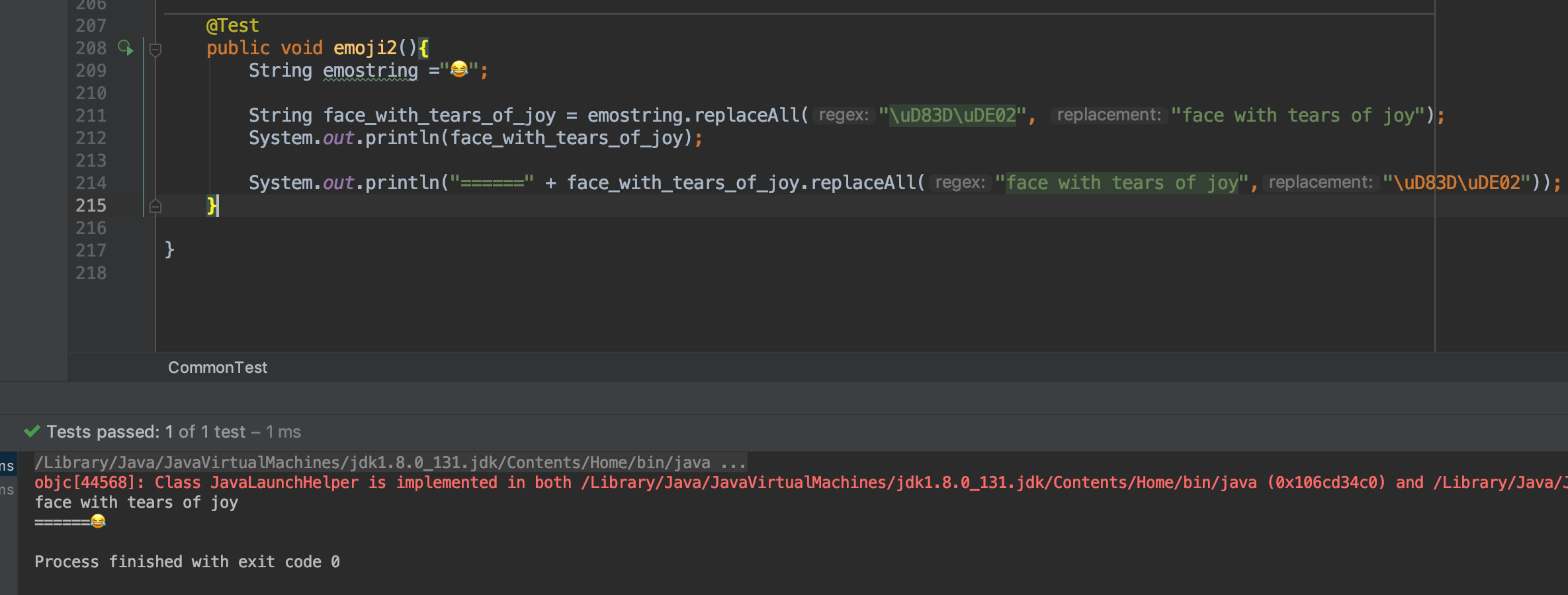
基于這個原理,我們也可以自己實現將一個 emoji 表情轉換為字符串,同時也可通過字符串轉換為 emoji。
感謝各位的閱讀,以上就是“怎么用java做emoji表情”的內容了,經過本文的學習后,相信大家對怎么用java做emoji表情這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





