溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Tomcat中的容器是怎么處理請求的,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
我們繼續跟著上篇文章Adapter的源碼,繼續分析,上篇文章結尾的源碼如下:
//源碼1.類: CoyoteAdapter implements Adapter
public void service(org.apache.coyote.Request req, org.apache.coyote.Response res)
throws Exception {
Request request = (Request) req.getNote(ADAPTER_NOTES);
Response response = (Response) res.getNote(ADAPTER_NOTES);
postParseSuccess = postParseRequest(req, request, res, response);
if (postParseSuccess) {
//check valves if we support async
request.setAsyncSupported(
connector.getService().getContainer().getPipeline().isAsyncSupported());
// Calling the container
connector.getService().getContainer().getPipeline().getFirst().invoke(
request, response);
}
}上面的源碼的主要作用就是獲取到容器,然后調用getPipeline()獲取Pipeline,最后去invoke調用,我們來看看這個Pipeline是做什么的。
//源碼2.Pipeline接口
public interface Pipeline extends Contained {
public Valve getBasic();
public void setBasic(Valve valve);
public void addValve(Valve valve);
public Valve[] getValves();
public void removeValve(Valve valve);
public Valve getFirst();
public boolean isAsyncSupported();
public void findNonAsyncValves(Set<String> result);
}
//源碼3. Valve接口
public interface Valve {
public Valve getNext();
public void setNext(Valve valve);
public void backgroundProcess();
public void invoke(Request request, Response response)
throws IOException, ServletException;
public boolean isAsyncSupported();我們從字面上可以理解Pipeline就是管道,而Valve就是閥門,實際上在Tomcat中的作用也是和字面意思差不多。每個容器都有一個管道,而管道中又有多個閥門。我們通過后面的分析來證明這一點。
我們看到上面的源碼是Pipeline和Valve的接口,Pipeline主要是設置Valve,而Valve是一個鏈表,然后可以進行invoke方法的調用。我們回顧下這段源碼:
//源碼4 connector.getService().getContainer().getPipeline().getFirst().invoke( request, response);
這里是直接獲取容器的管道,然后獲取第一個Valve進行調用。我們在之前提到過Valve是一個鏈表,這里只調用第一個,也就是可以通過Next去調用到最后一個。我們再回顧下我們第一篇文章《Tomcat在SpringBoot中是如何啟動的》中提到過,容器是分為4個子容器,分別為Engine、Host、Context、Wrapper,他們同時也是父級和子級的關系,Engine>Host>Context>Wrapper。
我之前提到過,每個容器都一個Pipeline,那么這個是怎么體現出來的呢?我們看容器的接口源碼就可以發現,Pipeline是容器接口定義的一個基本屬性:
//源碼5.
public interface Container extends Lifecycle {
//省略其他代碼
/**
* Return the Pipeline object that manages the Valves associated with
* this Container.
*
* @return The Pipeline
*/
public Pipeline getPipeline();
}我們知道了每個容器都有一個管道(Pipeline),管道中有許多閥門(Valve),Valve可以進行鏈式調用,那么問題來了,父容器管道中的Valve怎么調用到子容器中的Valve呢?在Pipeline的實現類StandardPipeline中,我們發現了如下源碼:
/**
// 源碼6.
* The basic Valve (if any) associated with this Pipeline.
*/
protected Valve basic = null;
/**
* The first valve associated with this Pipeline.
*/
protected Valve first = null;
public void addValve(Valve valve) {
//省略部分代碼
// Add this Valve to the set associated with this Pipeline
if (first == null) {
first = valve;
valve.setNext(basic);
} else {
Valve current = first;
while (current != null) {
//這里循環設置Valve,保證最后一個是basic
if (current.getNext() == basic) {
current.setNext(valve);
valve.setNext(basic);
break;
}
current = current.getNext();
}
}
container.fireContainerEvent(Container.ADD_VALVE_EVENT, valve);
}根據如上代碼,我們知道了basic是一個管道(Pipeline)中的最后一個閥門,按道理只要最后一個閥門是下一個容器的第一個閥門就可以完成全部的鏈式調用了。我們用一個請求debug下看看是不是和我們的猜測一樣,我們在CoyoteAdapter中的service方法中打個斷點,效果如下: 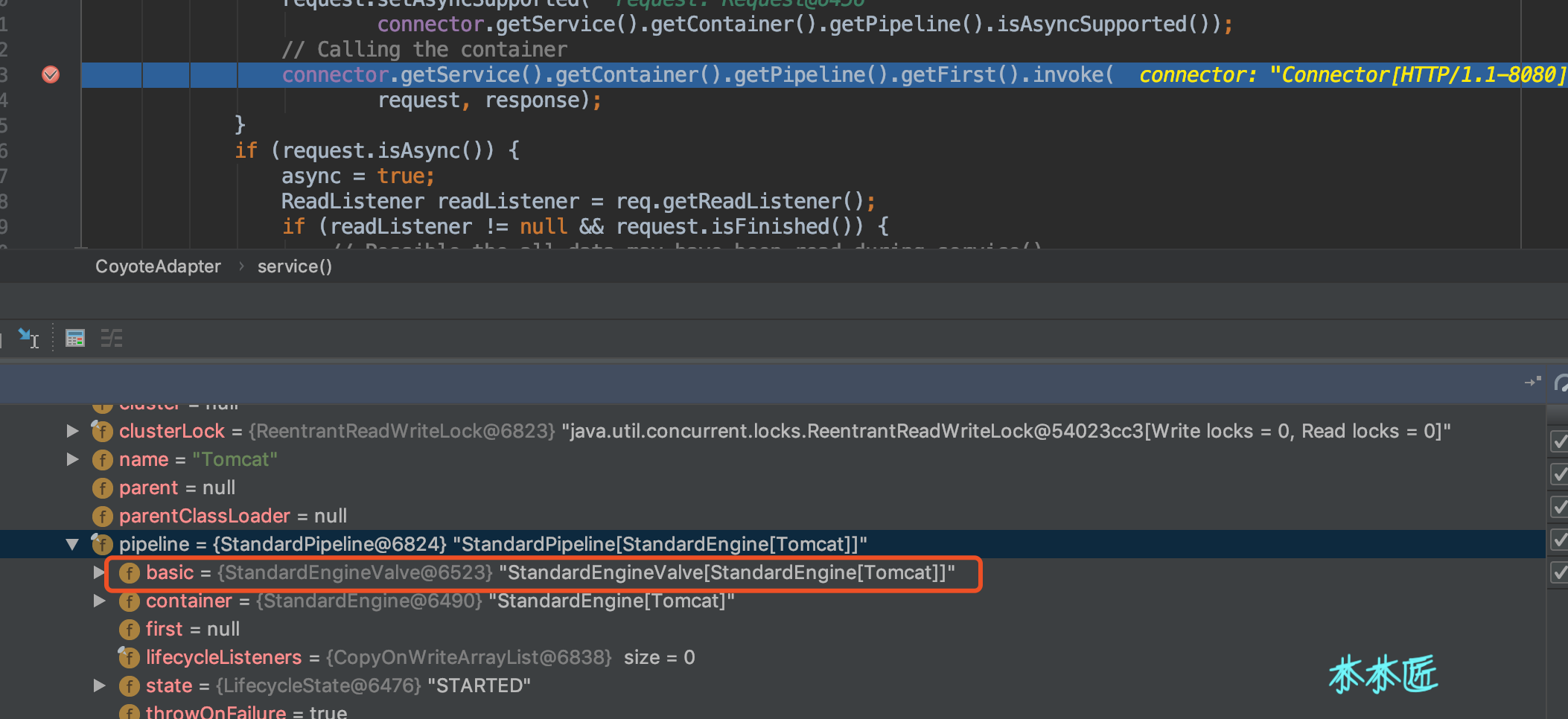
這里我們可以知道,在適配器調用容器的時候,也就是調用Engine的管道,只有一個閥門,也就是basic,值為StandardEngineValve。我們發現這個閥門的invoke方法如下:
//源碼7.
public final void invoke(Request request, Response response)
throws IOException, ServletException {
// Select the Host to be used for this Request
Host host = request.getHost();
if (host == null) {
// HTTP 0.9 or HTTP 1.0 request without a host when no default host
// is defined. This is handled by the CoyoteAdapter.
return;
}
if (request.isAsyncSupported()) {
request.setAsyncSupported(host.getPipeline().isAsyncSupported());
}
// Ask this Host to process this request
host.getPipeline().getFirst().invoke(request, response);
}我們繼續debug查看結果如下: 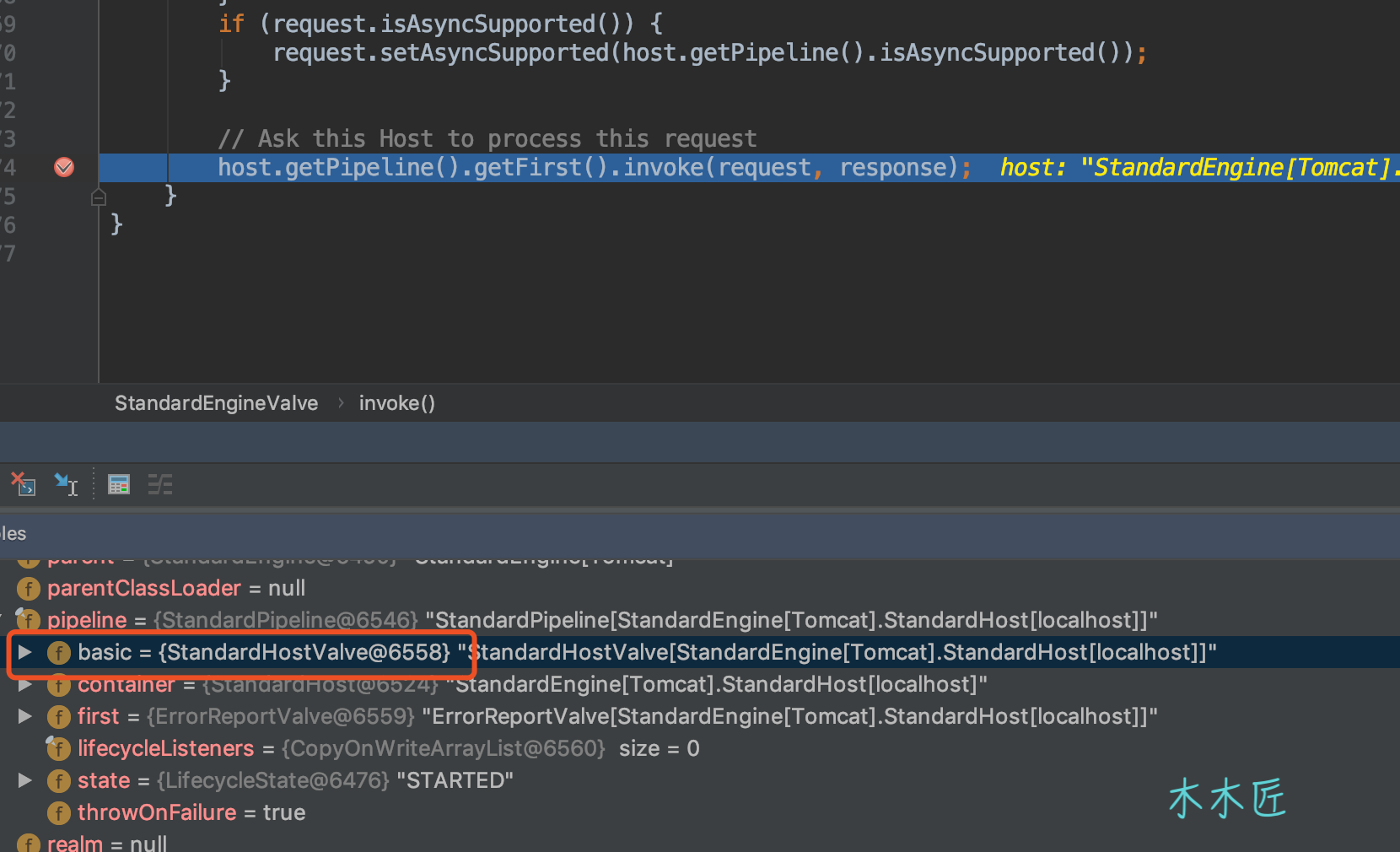
所以這里的basic實際上將會調用到Host容器的管道(Pipeline)和閥門(Valve),也就是說,每個容器管道中的basic是負責調用下一個子容器的閥門。我用一張圖來表示:
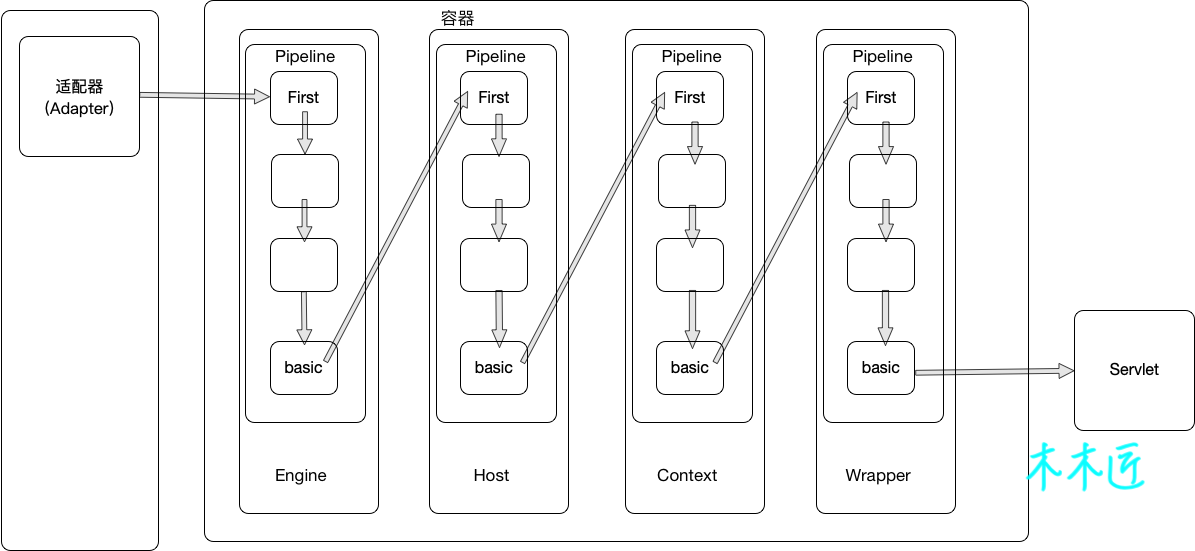
這張圖清晰的描述了,Tomcat內部的容器是如何流轉請求的,從連接器(Connector)過來的請求會進入Engine容器,Engine通過管道(Pieline)中的閥門(Valve)來進行鏈式調用,最后的basic閥門是負責調用下一個容器的第一個閥門的,一直調用到Wrapper,然后Wrapper再執行Servlet。
我們看看Wrapper源碼,是否真的如我們所說:
//源碼8.
public final void invoke(Request request, Response response)
throws IOException, ServletException {
//省略部分源碼
Servlet servlet = null;
if (!unavailable) {
servlet = wrapper.allocate();
}
// Create the filter chain for this request
ApplicationFilterChain filterChain =
ApplicationFilterFactory.createFilterChain(request, wrapper, servlet);
filterChain.doFilter(request.getRequest(),
response.getResponse());
}看到這里,你可能會說這里明明只是創建了過濾器(Filter)并且去調用而已,并沒有去調用Servlet ,沒錯,這里確實沒有去調用Servlet,但是我們知道,過濾器(Filter)是在Servlet之前執行的,也就是說,filterChain.doFilter執行完之后變會執行Servlet。我們看看ApplicationFilterChain的源碼是否如我們所說:
//源碼9.
public void doFilter(ServletRequest request, ServletResponse response)
throws IOException, ServletException {
//省略部分代碼
internalDoFilter(request,response);
}
//源碼10.
private void internalDoFilter(ServletRequest request,
ServletResponse response)
throws IOException, ServletException {
//省略部分代碼
// Call the next filter if there is one
if (pos < n) {
//省略部分代碼
ApplicationFilterConfig filterConfig = filters[pos++];
Filter filter = filterConfig.getFilter();
filter.doFilter(request, response, this);
return;
}
//調用servlet
// We fell off the end of the chain -- call the servlet instance
servlet.service(request, response);通過源碼我們發現,在調用完所有的過濾器(Filter)之后,servlet就開始調用service。我們看看servlet的實現類

這里我們熟悉的HttpServlet和GenericServlet是Tomcat包的類,實際上只有HttpServlet,因為GenericServlet是HttpServlet的父類。后面就是移交給了框架去處理了,Tomcat內部的請求已經到此是完成了。
我們知道,Tomcat是支持部署多個應用的,那么Tomcat是如何支持多應用的部署呢?是怎么保證多個應用之間不會混淆的呢?要想弄懂這個問題,我們還是要回到適配器去說起,回到service方法
//源碼11.類:CoyoteAdapter
public void service(org.apache.coyote.Request req, org.apache.coyote.Response res)
throws Exception {
//省略部分代碼
// Parse and set Catalina and configuration specific
// request parameters
//處理URL映射
postParseSuccess = postParseRequest(req, request, res, response);
if (postParseSuccess) {
//check valves if we support async
request.setAsyncSupported(
connector.getService().getContainer().getPipeline().isAsyncSupported());
// Calling the container
connector.getService().getContainer().getPipeline().getFirst().invoke(
request, response);
}
}我們在之前的源碼中只談到了connector.getService().getContainer().getPipeline().getFirst().invoke( request, response) 這段代碼,這部分代碼是調用容器,但是在調用容器之前有個postParseRequest方法是用來處理映射請求的,我們跟進看看源碼:
//源碼12.類:CoyoteAdapter
protected boolean postParseRequest(org.apache.coyote.Request req, Request request,
org.apache.coyote.Response res, Response response) throws IOException, ServletException {
省略部分代碼
boolean mapRequired = true;
while (mapRequired) {
// This will map the the latest version by default
connector.getService().getMapper().map(serverName, decodedURI,
version, request.getMappingData());
//沒有找到上下文就報404錯誤
if (request.getContext() == null) {
// Don't overwrite an existing error
if (!response.isError()) {
response.sendError(404, "Not found");
}
// Allow processing to continue.
// If present, the error reporting valve will provide a response
// body.
return true;
}
}這里就是循環去處理Url映射,如果Context沒有找到,就返回404錯誤,我們繼續看源碼:
//源碼13.類:Mapper
public void map(MessageBytes host, MessageBytes uri, String version,
MappingData mappingData) throws IOException {
if (host.isNull()) {
String defaultHostName = this.defaultHostName;
if (defaultHostName == null) {
return;
}
host.getCharChunk().append(defaultHostName);
}
host.toChars();
uri.toChars();
internalMap(host.getCharChunk(), uri.getCharChunk(), version, mappingData);
}
//源碼14.類:Mapper
private final void internalMap(CharChunk host, CharChunk uri,
String version, MappingData mappingData) throws IOException {
//省略部分代碼
// Virtual host mapping 處理Host映射
MappedHost[] hosts = this.hosts;
MappedHost mappedHost = exactFindIgnoreCase(hosts, host);
//省略部分代碼
if (mappedHost == null) {
mappedHost = defaultHost;
if (mappedHost == null) {
return;
}
}
mappingData.host = mappedHost.object;
// Context mapping 處理上下文映射
ContextList contextList = mappedHost.contextList;
MappedContext[] contexts = contextList.contexts;
//省略部分代碼
if (context == null) {
return;
}
mappingData.context = contextVersion.object;
mappingData.contextSlashCount = contextVersion.slashCount;
// Wrapper mapping 處理Servlet映射
if (!contextVersion.isPaused()) {
internalMapWrapper(contextVersion, uri, mappingData);
}
}由于上面的源碼比較多,我省略了很多代碼,保留了能理解主要邏輯的代碼,總的來說就是處理Url包括三部分,映射Host,映射Context和映射Servlet(為了節省篇幅,具體細節源碼請感興趣的同學自行研究)。
這里我們可以發現一個細節,就是三個處理邏輯都是緊密關聯的,只有Host不為空才會處理Context,對于Servlet也是同理。所以這里我們只要Host配置不同,那么后面所有的子容器都是不同的,也就完成了應用隔離的效果。但是對于SpringBoot內嵌Tomcat方式(使用jar包啟動)來說,并不具備實現多應用的模式,本身一個應用就是一個Tomcat。
為了便于理解,我也畫了一張多應用隔離的圖,這里我們假設有兩個域名admin.luozhou.com和web.luozhou.com 然后我每個域名下部署2個應用,分別是User,log,blog,shop。那么當我去想去添加用戶的時候,我就會請求admin.luozhou.com域名下的User的Context下面的add的Servlet(說明:這里例子設計不符合實際開發原則,add這種粒度應該是框架中的controller完成,而不是Servlet)。
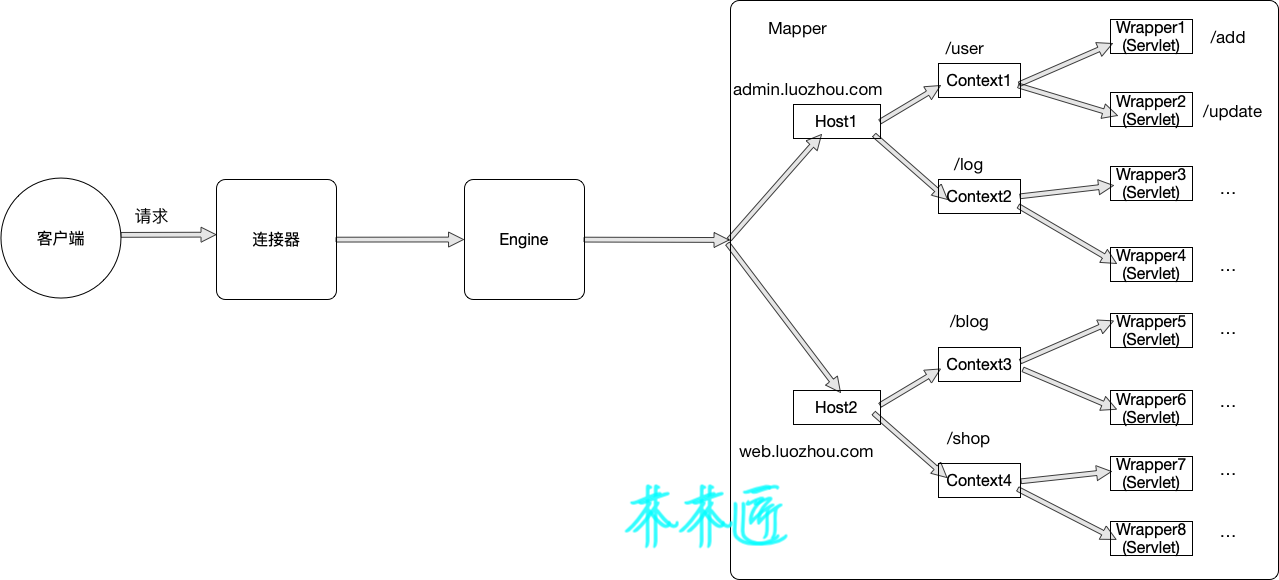
這篇文章我們研究了Tomcat中容器是如何處理請求的,我們來回顧下內容:
連接器把請求丟給適配器適配后調用容器(Engine)
容器內部是通過管道(Pieline)-閥門(Valve)模式完成容器的調用的,父容器調用子容器主要通過一個basic的閥門來完成的。
最后一個子容器wrapper完成調用后就會構建過濾器來進行過濾器調用,調用完成后就到了Tomcat內部的最后一步,調用servlet。也可以理解我們常用的HttpServlet,所有基于Servlet規范的框架在這里就進入了框架流程(包括SpringBoot)。
最后我們還分析了Tomcat是如何實現多應用隔離的,通過多應用的隔離分析,我們也明白了為什么Tomcat要設計如此多的子容器,多子容器可以根據需要完成不同粒度的隔離級別來實現不同的場景需求。
關于“Tomcat中的容器是怎么處理請求的”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





