溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
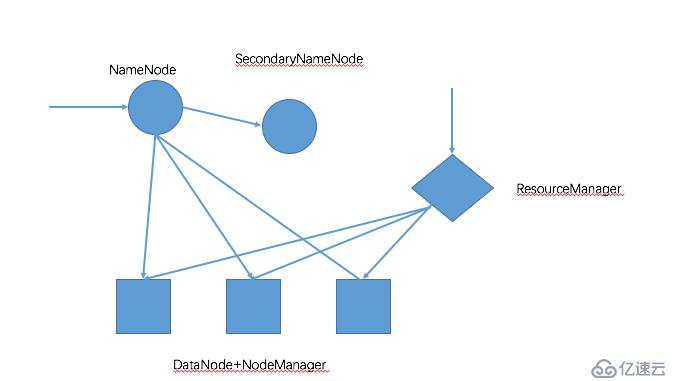
Hadoop Cluster中的角色:
HDFS:
NameNode,NN
SecondaryNameNode,SNN
DataNode,DN
YARN:
ResourceManager
NodeManager
生產環境中hadoop分布式部署注意事項:
HDFS集群:
NameNode和Secondary應該分開部署,避免NameNode和SecondaryNode同時出現故障,而無法恢復
DataNode數量至少為3個,因為數據至少要保存3份
YARN集群:
ResourceManager部署在獨立的節點上
NodeManager運行在DataNode上
Hadoop集群架構如下圖所示:
我在測試環境中進行分布式部署時,將NameNode、SecondaryNameNode和ResourceManager三個角色部署在同一服務器Master節點上,
三個從節點部署DataNode和NodeManager
1、配置hosts文件
node1、node2、node3、node4上的/etc/hosts文件中追加以下內容
172.16.2.3 node1.hadooptest.com node1 master 172.16.2.14 node2.hadooptest.com node2 172.16.2.60 node3.hadooptest.com node3 172.16.2.61 node4.hadooptest.com node4
2、創建hadoop用戶和組
如果需要通過master節點啟動或者停止整個集群,還需要在master節點上配置用于運行服務的用戶(如hdfs和yarn)能以密鑰的方式通過ssh遠程連接到各個從節點
node1、node2、node3、node4上分別執行
useradd hadoop echo 'p@ssw0rd' | passwd --stdin hadoop
登錄node1,創建密鑰
su - hadoop ssh-keygen -t rsa
將公鑰從node1分別上傳到node2、node3、node4
ssh-copy-id -i .ssh/id_rsa.pub hadoop@node2 ssh-copy-id -i .ssh/id_rsa.pub hadoop@node3 ssh-copy-id -i .ssh/id_rsa.pub hadoop@node4
注意:master節點也要將公鑰傳到自己的hadoop賬戶下,否則啟動secondarynamenode時,要輸入密碼
[hadoop@node1 hadoop]$ node1ssh-copy-id -i .ssh/id_rsa.pub hadoop@0.0.0.0
測試從node1登錄到node2、node3、node4
[hadoop@OPS01-LINTEST01 ~]$ ssh node2 'date' Tue Mar 27 14:26:10 CST 2018 [hadoop@OPS01-LINTEST01 ~]$ ssh node3 'date' Tue Mar 27 14:26:13 CST 2018 [hadoop@OPS01-LINTEST01 ~]$ ssh node4 'date' Tue Mar 27 14:26:17 CST 2018
3、配置hadoop環境
node1、node2、node3、node4上都需要執行
vim /etc/profile.d/hadoop.sh
export HADOOP_PREFIX=/bdapps/hadoop
export PATH=$PATH:${HADOOP_PREFIX}/bin:${HADOOP_PREFIX}/sbin
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}node1配置
創建目錄
[root@OPS01-LINTEST01 ~]# mkdir -pv /bdapps /data//hadoop/hdfs/{nn,snn,dn}
mkdir: created directory `/bdapps'
mkdir: created directory `/data//hadoop'
mkdir: created directory `/data//hadoop/hdfs'
mkdir: created directory `/data//hadoop/hdfs/nn'
mkdir: created directory `/data//hadoop/hdfs/snn'
mkdir: created directory `/data//hadoop/hdfs/dn'配置權限
chown -R hadoop:hadoop /data/hadoop/hdfs/ cd /bdapps/ [root@OPS01-LINTEST01 bdapps]# ls hadoop-2.7.5 [root@OPS01-LINTEST01 bdapps]# ln -sv hadoop-2.7.5 hadoop [root@OPS01-LINTEST01 bdapps]# cd hadoop [root@OPS01-LINTEST01 hadoop]# mkdir logs
修改hadoop目錄下所有文件的屬主屬組為hadoop,并給logs目錄添加寫入權限
[root@OPS01-LINTEST01 hadoop]# chown -R hadoop:hadoop ./* [root@OPS01-LINTEST01 hadoop]# ll total 140 drwxr-xr-x 2 hadoop hadoop 4096 Dec 16 09:12 bin drwxr-xr-x 3 hadoop hadoop 4096 Dec 16 09:12 etc drwxr-xr-x 2 hadoop hadoop 4096 Dec 16 09:12 include drwxr-xr-x 3 hadoop hadoop 4096 Dec 16 09:12 lib drwxr-xr-x 2 hadoop hadoop 4096 Dec 16 09:12 libexec -rw-r--r-- 1 hadoop hadoop 86424 Dec 16 09:12 LICENSE.txt drwxr-xr-x 2 hadoop hadoop 4096 Mar 27 14:51 logs -rw-r--r-- 1 hadoop hadoop 14978 Dec 16 09:12 NOTICE.txt -rw-r--r-- 1 hadoop hadoop 1366 Dec 16 09:12 README.txt drwxr-xr-x 2 hadoop hadoop 4096 Dec 16 09:12 sbin drwxr-xr-x 4 hadoop hadoop 4096 Dec 16 09:12 share [root@OPS01-LINTEST01 hadoop]# chmod g+w logs
core-site.xml文件配置
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> <final>true</final> </property> </configuration>
yarm-site.xml文件配置
注意:yarn-site.xml是ResourceManager角色相關配置。生產環境下該角色和NameNode是應該分開部署的,所以該文件中的master和core-site.xml中的master不是同一臺機器。由于我這里是在測試環境中模擬分布式部署,
將NameNode和ResourceManager部署在一臺機器上了,所以才會需要在NameNode服務器上配置該文件。
<configuration> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> </configuration>
hdfs-site.xml文件配置
修改 dfs.replication 副本保留數量
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///data/hadoop/hdfs/nn</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///data/hadoop/hdfs/dn</value> </property> <property> <name>fs.checkpoint.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> <property> <name>fs.checkpoint.edits.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> </configuration>
mapred-site.xml文件配置
cp mapred-site.xml.template mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
slaves文件配置
node2 node3 node4
hadoop-env.sh文件配置
export JAVA_HOME=/usr/java/jdk1.8.0_151
配置node2、node3、node4節點
###創建hadoop安裝目錄,和數據目錄以及logs目錄,并修改權限
mkdir -pv /bdapps /data/hadoop/hdfs/{nn,snn,dn}
chown -R hadoop.hadoop /data/hadoop/hdfs/
tar zxf hadoop-2.7.5.tar.gz -C /bdapps/
cd /bdapps
ln -sv hadoop-2.7.5 hadoop
cd hadoop
mkdir logs
chmod g+w logs
chown -R hadoop:hadoop ./*配置文件修改
由于我們前面在master節點(node1)已經修改了hadoop相關配置文件,所以可以直接從master節點同步到node2、node3、node4節點上
scp /bdapps/hadoop/etc/hadoop/* node2:/bdapps/hadoop/etc/hadoop/ scp /bdapps/hadoop/etc/hadoop/* node3:/bdapps/hadoop/etc/hadoop/ scp /bdapps/hadoop/etc/hadoop/* node4:/bdapps/hadoop/etc/hadoop/
啟動hadoop相關服務
master節點
與偽分布式模式相同,在HDFS集群的NN啟動之前需要先初始化其用于處處數據的目錄,如果hdfs-site.xml中 dfs.namenode.name.dir屬性指定的目錄不存在,
格式化命令會自動創建之,如果事先存在,請確保其權限設置正確,此時格式操作會清除其內部的所有數據并重新建立一個新的文件系統。需要以hdfs用戶的身份在master節點執行如下命令
hdfs namenode -format
啟動集群節點有兩種方式:
1、登錄到各個節點手動啟動服務
2、在master節點控制啟動整個集群
集群規模較大時,分別啟動各個節點的各個服務會比較繁瑣,所以hadoop提供了start-dfs.sh和stop-dfs.sh來啟動及停止整個hdfs集群,以及start-yarn.sh和stop-yarn.sh來啟動和停止整個yarn集群
[hadoop@node1 hadoop]$start-dfs.sh Starting namenodes on [master] hadoop@master's password: master: starting namenode, logging to /bdapps/hadoop/logs/hadoop-hadoop-namenode-node1.out node4: starting datanode, logging to /bdapps/hadoop/logs/hadoop-hadoop-datanode-node4.out node2: starting datanode, logging to /bdapps/hadoop/logs/hadoop-hadoop-datanode-node2.out node3: starting datanode, logging to /bdapps/hadoop/logs/hadoop-hadoop-datanode-node3.out Starting secondary namenodes [0.0.0.0] hadoop@0.0.0.0's password: 0.0.0.0: starting secondarynamenode, logging to /bdapps/hadoop/logs/hadoop-hadoop-secondarynamenode-node1.out [hadoop@node1 hadoop]$ jps 69127 NameNode 69691 Jps 69566 SecondaryNameNode
登錄到datanode節點查看進程
[root@node2 ~]# jps 66968 DataNode 67436 Jps [root@node3 ~]# jps 109281 DataNode 109991 Jps [root@node4 ~]# jps 108753 DataNode 109674 Jps
停止整個集群的服務
[hadoop@node1 hadoop]$ stop-dfs.sh Stopping namenodes on [master] master: stopping namenode node4: stopping datanode node2: stopping datanode node3: stopping datanode Stopping secondary namenodes [0.0.0.0] 0.0.0.0: stopping secondarynamenode
測試
在master節點上,上傳一個文件
[hadoop@node1 ~]$ hdfs dfs -mkdir /test [hadoop@node1 ~]$ hdfs dfs -put /etc/fstab /test/fstab [hadoop@node1 ~]$ hdfs dfs -ls -R /test -rw-r--r-- 2 hadoop supergroup 223 2018-03-27 16:48 /test/fstab
登錄node2
[hadoop@node2 ~]$ ls /data/hadoop/hdfs/dn/current/BP-1194588190-172.16.2.3-1522138946011/current/finalized/ [hadoop@node2 ~]$
沒有fstab文件
登錄node3,可以看到fstab文件
[hadoop@node3 ~]$ cat /data/hadoop/hdfs/dn/current/BP-1194588190-172.16.2.3-1522138946011/current/finalized/subdir0/subdir0/blk_1073741825 UUID=dbcbab6c-2836-4ecd-8d1b-2da8fd160694 / ext4 defaults 1 1 tmpfs /dev/shm tmpfs defaults 0 0 devpts /dev/pts devpts gid=5,mode=620 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0 dev/vdb1 none swap sw 0 0
登錄node4,也可以看到fstab文件
[hadoop@node4 root]$ cat /data/hadoop/hdfs/dn/current/BP-1194588190-172.16.2.3-1522138946011/current/finalized/subdir0/subdir0/blk_1073741825 UUID=dbcbab6c-2836-4ecd-8d1b-2da8fd160694 / ext4 defaults 1 1 tmpfs /dev/shm tmpfs defaults 0 0 devpts /dev/pts devpts gid=5,mode=620 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0 dev/vdb1 none swap sw 0 0
結論:由于我們數據保存2份,所以只在node3,node4上有文件副本,node2上沒有
啟動yarn集群
登錄node1(master),執行start-yarn.sh
[hadoop@node1 ~]$ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-resourcemanager-node1.out node4: starting nodemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-nodemanager-node4.out node2: starting nodemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-nodemanager-node2.out node3: starting nodemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-nodemanager-node3.out [hadoop@node1 ~]$ jps 78115 ResourceManager 71574 NameNode 71820 SecondaryNameNode 78382 Jps
登錄node2,執行jps命令,可以看到NodeManager服務已經啟動了
[ansible@node2 ~]$ sudo su - hadoop [hadoop@node2 ~]$ jps 68800 DataNode 75400 Jps 74856 NodeManager
查看Web UI控制臺
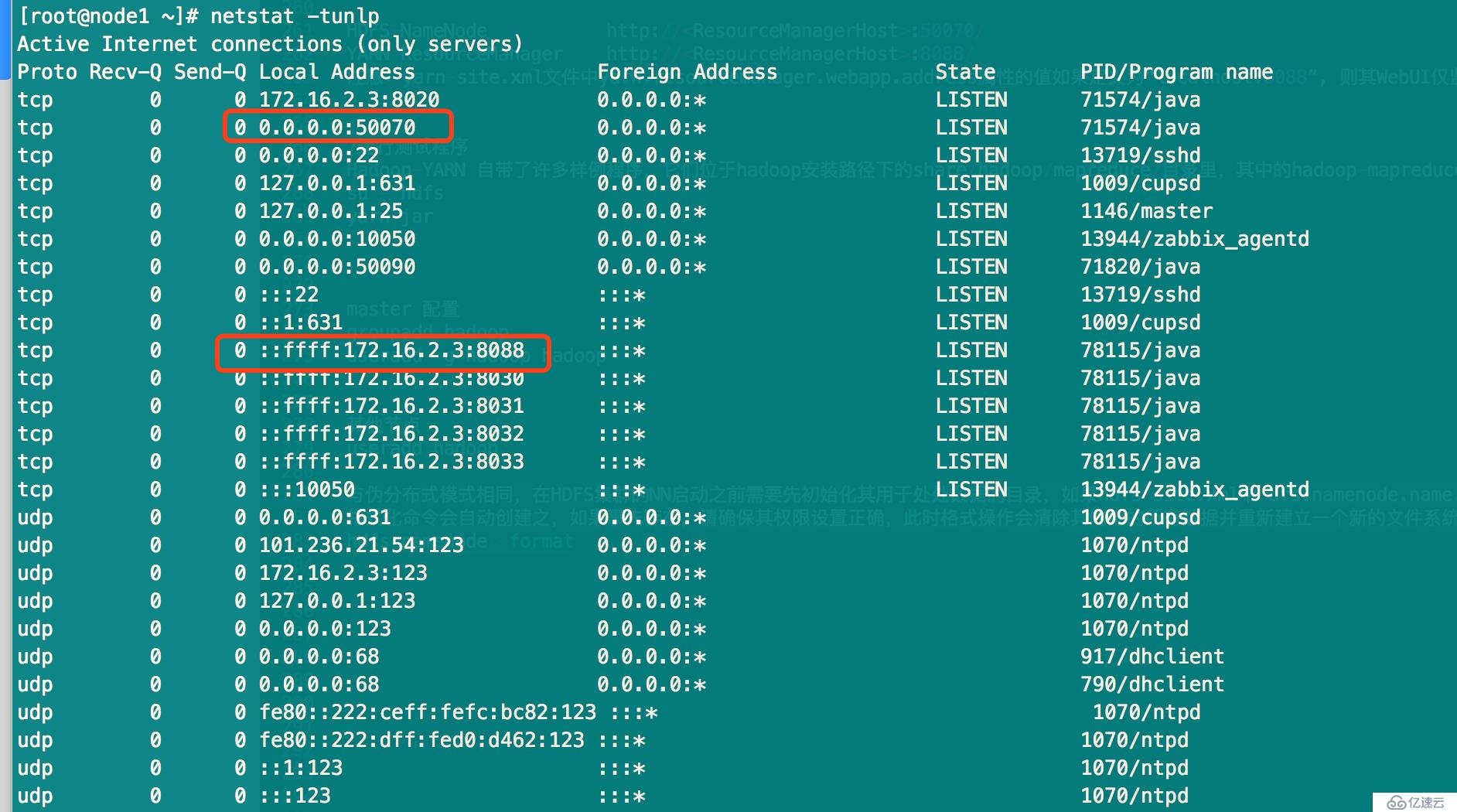
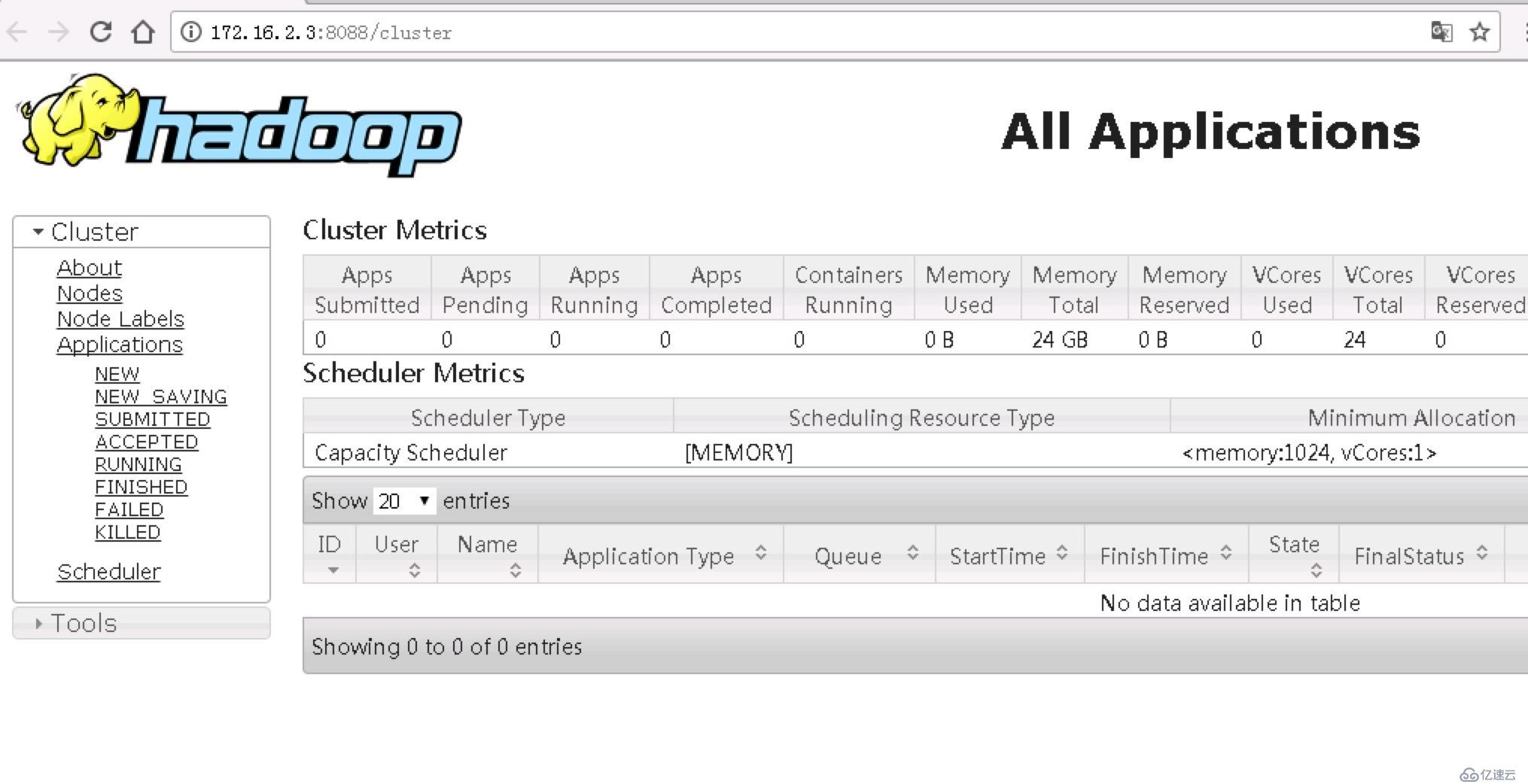
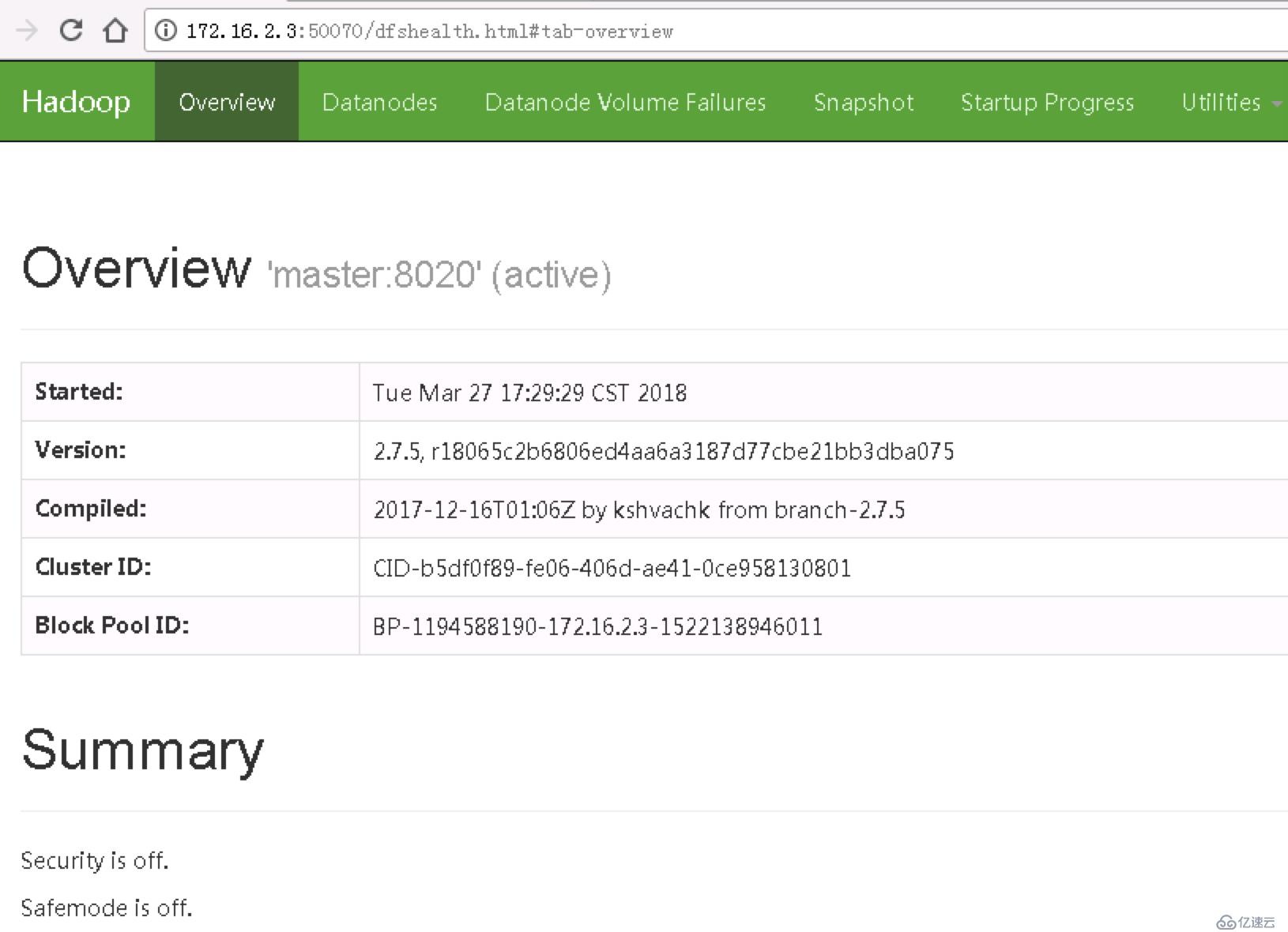
其他參考文檔:
http://www.codeceo.com/understand-hadoop-hbase-hive-spark-distributed-system-architecture.html
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





