溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何用Cassandra每天存儲上億條線上數據”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Discord 語音聊天軟件及我們的 UGC 內容的增長速度比想象中要快得多。隨著越來越多用戶的加入,帶來了更多聊天消息。
2016 年 7 月,每天大約有 4 千萬條消息;
2016 年 12 月,每天超過億條。
當寫這篇文章時(2017 年 1 月),每天已經超過 1.2 億條了。
我們早期決定永久保存所有用戶的聊天歷史記錄,這樣用戶可以隨時在任何設備查找他們的數據。這是一個持續增長的高并發訪問的海量數據,而且需要保持高可用。
如何才能搞定這一切?我們的經驗是選擇 Cassandra 作為數據庫!
Discord 語音聊天軟件的最初版本在 2015 年只用了兩個月就開發出來。在那個階段,MongoDB 是支持快速迭代最好的數據庫之一。所有 Discord 數據都保存在同一個 MongoDB 集群中,但在設計上我們也支持將所有數據很容易地遷移到一種新的數據庫(我們不打算使用 MongoDB 數據庫的分片,因為它使用起來復雜以及穩定性不好)。
實際上這是我們企業文化的一部分:快速搭建來驗證產品的特性,但也預留方法來支持將它升級到一個更強大的版本。
消息保存在 MongoDB 中,使用 channel_id 和 created_at 的單一復合索引。到 2015 年 11 月,存儲的消息達到了 1 億條,這時,原來預期的問題開始出現:內存中再也放不下所有索引及數據,延遲開始變得不可控,是時候遷移到一個更適合這個項目的數據庫了。
在選擇一個新的數據庫之前,我們必須了解當前的讀/寫模式,以及我們目前的解決方案為什么會出現問題。
很顯然,我們的讀取是非常隨機的,我們的讀/寫比為 50 / 50。
語音聊天服務器:它只處理很少的消息,每隔幾天才發幾條信息。在一年內,這種服務器不太可能達到 1000 條消息。它面臨的問題是,即使請求量很小,它也很難高效,單返回 50 條消息給一個用戶,就會導致磁盤中的許多次隨機查找,并導致磁盤緩存淘汰。
私信聊天服務器:發送相當數量的消息,一年下來很容易達到 10 萬到 100 萬條消息。他們請求的數據通常只是最近的。它們的問題是,數據由于訪問得不多且分散,因此不太可能被緩存在磁盤中。
大型公共聊天服務器:發送大量的消息。他們每天有成千上萬的成員發送數以千計的消息,每年可以輕松地發送數以百萬計的消息。他們幾乎總是在頻繁請求最近一小時的消息,因此數據可以很容易地被磁盤緩存命中。
我們預計在未來的一年,將會給用戶提供更多隨機讀取數據的功能:查看 30 天內別人提及到你的消息,然后點擊到某條歷史記錄消息,查閱標記(pinned)的消息以及全文搜索等功能。 這一切導致更多的隨機讀取!!
接下來我們來定義一下需求:
線性可擴展性 – ?我們不想等幾個月又要重新考慮新的擴展方案,或者是重新拆分數據。
自動故障轉移?(failover) – ?我們不希望晚上的休息被打擾,當系統出現問題我們希望它盡可能的能自動修復。
低維護成本 – ?一配置完它就能開始工作,隨著數據的增長時,我們要需要簡單增加機器就能解決。
已經被驗證過的技術 – ?我們喜歡嘗試新的技術,但不要太新。
可預測的性能 – ?當 API 的響應時間 95% 超過 80ms 時也無需警示。我們也不想重復在 Redis 或 Memcached 增加緩存機制。
非二進制存儲 – 由于數據量大,我們不太希望寫數據之前做一些讀出二進制并反序列化的工作。
開源 – ?我們希望能掌控自己的命運,不想依靠第三方公司。
Cassandra 是唯一能滿足我們上述所有需求的數據庫。
我們可以添加節點來擴展它,添加過程不會對應用程序產生任何影響,也可以容忍節點的故障。 一些大公司如 Netflix 和蘋果,已經部署有數千個 Cassandra 節點。 數據連續存儲在磁盤上,這樣減少了數據訪問尋址成本,且數據可以很方便地分布在集群上。它依賴 DataStax,但依舊是開源和社區驅動的。
做出選擇后,我們需要證明它實際上是可行的。
向一個新手描述 Cassandra 數據庫最好的辦法,是將它描述為 KKV 存儲,兩個 K 構成了主鍵。
第一個 K 是分區鍵(partition key),用于確定數據存儲在哪個節點上,以及在磁盤上的位置。一個分區包含很多行數據,行的位置由第二個 K 確定,這是聚類鍵(clustering key),聚類鍵充當分區內的主鍵,以及決定了數據行如何排序。可以將分區視為有序字典。這些屬性相結合,可以支持非常強大的數據建模。
前面提到過,消息在 MongoDB 中的索引用的是 channel_id 和 created_at,由于經常查詢一個 channel 中的消息,因此 channel_id 被設計成為分區鍵,但 created_at 不作為一個大的聚類鍵,原因是系統內多個消息可能具有相同的創建時間。
幸運的是,Discord 系統的 ID 使用了類似 Twitter Snowflake [1] 的發號器(按時間粗略有序),因此我們可以使用這個 ID。主鍵就變成( channel_id, message_id), message_id 是 Snowflake 發號器產生。當加載一個 channel 時,我們可以準確地告訴 Cassandra 掃描數據的范圍。
下面是我們的消息表的簡化模式。
assandra 的 schema 與關系數據庫模式有很大區別,調整 schema 非常方便,不會帶來任何臨時性的性能影響。因此我們獲得了最好的二進制存儲和關系型存儲。
當我們開始向 Cassandra 數據庫導入現有的消息時,馬上看見出現在日志上的警告,提示分區的大小超過 100MB。發生了什么?! Cassandra 可是宣稱單個分區可以支持 2GB! 顯然,支持那么大并不意味著它應該設成那么大。
大的分區在進行壓縮、集群擴容等操作時會對 Cassandra 帶來較大的 GC 壓力。大分區也意味著它的數據不能分布在集群中。很明顯,我們必須限制分區的大小,因為一個單一的 channel 可以存在多年,且大小不斷增長。
我們決定按時間來歸并我們的消息并放在一個 bucket 中。通過分析最大的 channel,我們來確定 10 天的消息放在一個 bucket 中是否會超過 100mb。Bucket 必須從 message_id 或時間戳來歸并。
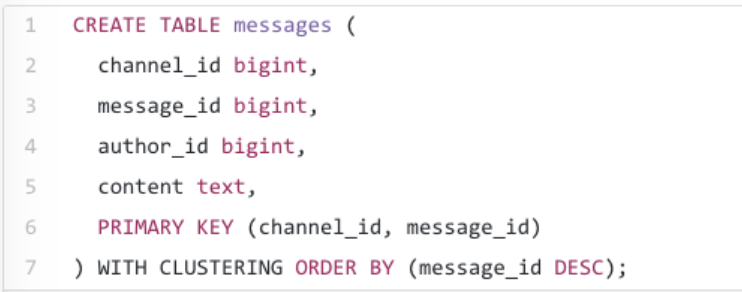
Cassandra 數據庫的分區鍵可以復合,所以我們新的主鍵成為 (( channel_id, bucket), message_id)。

為了方便查詢最近的消息,我們生成了一個從當前時間到 channel_id(也是 Snowflake 發號器生成,要比第一個消息舊)的 bucket。然后我們依次查詢分區直到收集到足夠的消息。這種方法的缺點是,不活躍的 channel 需要遍歷多個 bucket 從而收集到足夠返回的消息。在實踐中,這已被證明還行得通,因為對于活躍的 channel,查詢第一個 bucket 就可以返回足夠多的數據。
將消息導入到 Cassandra 數據庫十分順利,我們準備嘗試遷移到生產環境。
在生產環境引入新系統總是可怕的,因此最好在不影響用戶的前提下先進行測試。我們將代碼設置成雙讀/寫到 MongoDB 和 Cassandra。
一啟動系統我們就收到 bug 追蹤器發來的錯誤信息,錯誤提示 author_id 為 null。怎么會是 null ?這是一個必需的字段!在解釋這個問題之前,先介紹一下問題的背景。
Cassandra 是一個 AP 數據庫,這意味著它犧牲了強一致性(C)來換取可用性(A) ,這也正是我們所需要的。在 Cassandra 中讀寫是一個反模式(讀比寫的代價更昂貴),即使你只訪問某些列,本質上也會變成一個更新插入操作(upsert)。
你也可以寫入任何節點,在 column 的范圍,它將使用“last write wins”的策略自動解決寫入沖突,這個策略對我們有何影響?

編輯/刪除 race condition 的例子
在例子中,一個用戶編輯消息時,另一個用戶刪除相同的消息,當 Cassandra 執行 upsert 之后,我們只留下了主鍵和另外一個正在更新文本的列。
有兩個可能的解決方案來處理這個問題:
編輯消息時,將整個消息寫回。這有可能找回被刪除的消息,但是也增加了更多數據列沖突的可能。
能夠判斷消息已經損壞時,將其從數據庫中刪除。
我們選擇第二個選項,我們按要求選擇一列(在這種情況下, author_id),如果消息是空的就刪除。
在解決這個問題時,我們也注意到我們的寫入效率很低。由于 Cassandra 被設計為最終一致性,因此執行刪除操作時不會立即刪除數據,它必須復制刪除到其他節點,即使其他節點暫時不可用,它也照做。
Cassandra 為了方便處理,將刪除處理成一種叫“墓碑”的寫入形式。在處理過程中,它只是簡單跳過它遇到的墓碑。墓碑通過一個可配置的時間而存在(默認 10 天),在逾期后,會在壓縮過程中被永久刪除。
刪除列以及將 null 寫入列是完全相同的事情。他們都產生墓碑。因為所有在 Cassandra 數據庫中的寫入都是更新插入(upsert),這意味著哪怕第一次插入 null 都會生成一個墓碑。
實際上,我們整個消息數據包含 16 個列,但平均消息長度可能只有了 4 個值。這導致新插入一行數據沒緣由地將 12 個新的墓碑寫入至 Cassandra 中。
解決這個問題的方法很簡單:只給 Cassandra 數據庫寫入非空值。
Cassandra 以寫入速度比讀取速度要快著稱,我們觀察的結果也確實如此。寫入速度通常低于 1 毫秒而讀取低于 5 毫秒。
我們觀察了數據訪問的情況,性能在測試的一周內保持了良好的穩定性。沒什么意外,我們得到了我們所期望的數據庫。
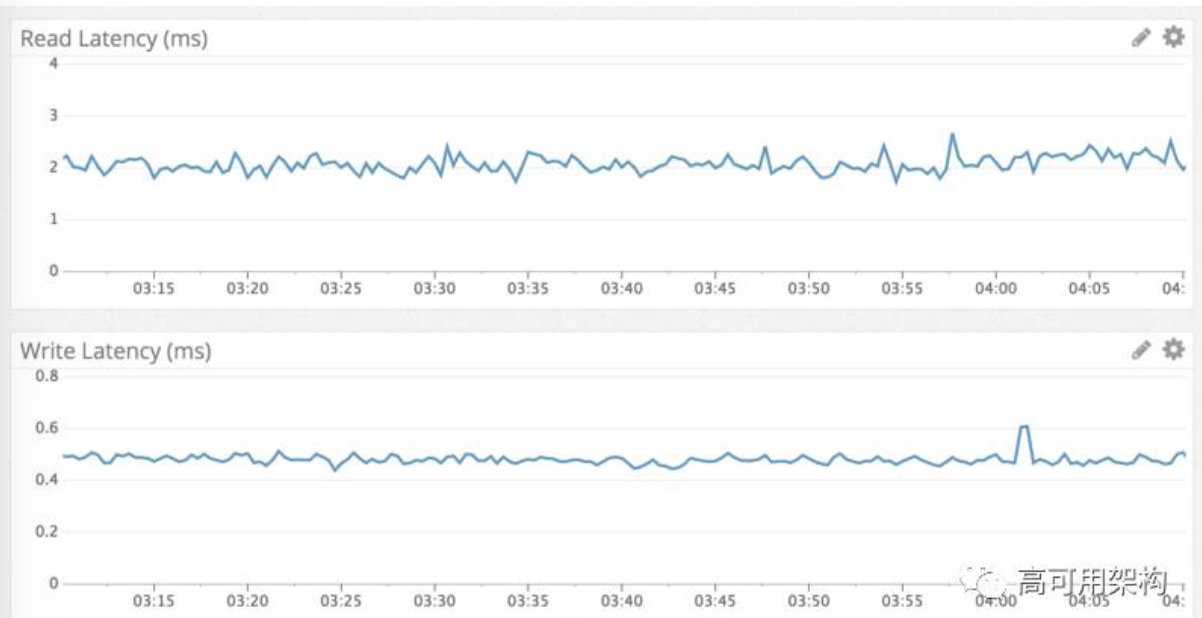
通過 Datadog 監控讀/寫延遲
說到快速、一致的讀取性能,這里有一個例子,跳轉到某個上百萬條消息的 channel 的一年前的某條消息。

跳轉到一年前的聊天記錄的性能
一切都很順利,因此我們將它切換成我們的主數據庫,然后在一周內淘汰掉 MongoDB。Cassandra 工作一切正常,直到 6 個月后有一天,Cassandra 突然變得反應遲鈍。我們注意到 Cassandra 開始出現 10 秒鐘的 GC 全停頓(Stop-the-world) ,但是我們不知道原因。
我們開始定位分析,發現加載某個 channel 需要 20 秒。一個叫 “Puzzles & Dragons Subreddit” 的公共 channel 是罪魁禍首。因為它是一個開放的 channel,因此我們也跑進去探個究竟。
令我們驚訝的是,channel 里只有 1 條消息。我們也了解到他們用我們的 API 刪除了數百萬條消息,只在 channel 中留下了 1 條消息。
上文提到 Cassandra 是如何用墓碑(在最終一致性中提及過)來處理刪除動作的。當一個用戶載入這個 channel,雖然只有 1 條的消息,Cassandra 不得不掃描百萬條墓碑(產生垃圾的速度比虛擬機收集的速度更快)。
我們通過如下措施解決:
因為我們每晚都會運行 Cassandra 數據庫修復(一個反熵進程),我們將墓碑的生命周期從 10 天降低至 2 天。
我們修改了查詢代碼,用來跟蹤空的 buckets,并避免他們在未來的 channel 中加載。這意味著,如果一個用戶再次觸發這個查詢,最壞的情況,Cassandra 數據庫只在最近的 bucket 中進行掃描。
我們目前在運行著一個復制因子是 3 的 12 節點集群,并根據業務需要持續增加新的節點,我相信這種模式可以支撐很長一段時間。但隨著 Discord 軟件的發展,相信有一天我們可能需要每天存儲數十億條消息。
Netflix 和蘋果都維護了運行著數千個節點的集群,所以我們知道目前這個階段不太需要顧慮太多。當然我們也希望有一些點子可以未雨綢繆。
近期工作
將我們的消息集群從 Cassandra 2 升級到 Cassandra 3。Cassandra 3 有一個新的存儲格式,可以將存儲大小減少 50% 以上。
新版 Cassandra 單節點可以處理更多數據。目前,我們在每個節點存儲了將近 1TB 的壓縮數據。我們相信我們可以安全地擴展到 2TB,以減少集群中節點的數量。
長期工作
嘗試下 Scylla [4],它是一款用 C++ 編寫與 Cassandra 兼容的數據庫。在正常操作期間,我們 Cassandra 節點實際上是沒有占用太多的 CPU,然而在非高峰時間,當我們運行修復(一個反熵進程)變得相當占用 CPU,同時,繼上次修復后,修復持續時間和寫入的數據量也增大了許多。 Scylla 宣稱有著極短的修復時間。
將沒使用的 Channel 備份成谷歌云存儲上的文件,并且在有需要時可以加載回來。我們其實也不太想做這件事,所以這個計劃未必會執行。
Ref-01: http://ju.outofmemory.cn/entry/311011
“如何用Cassandra每天存儲上億條線上數據”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





