溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“dubbo接口調用過程中,部分字段值丟失怎么辦”,在日常操作中,相信很多人在dubbo接口調用過程中,部分字段值丟失怎么辦問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”dubbo接口調用過程中,部分字段值丟失怎么辦”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
在工作中,遇到了調用遠程dubbo接口,字段值丟失的情況。排查后,發現調用前后的代碼無誤,主要原因是在接口調用時使用hessian序列化,出現了子類與父類重復字段,導致字段值丟失。
解決辦法:將父類重復字段刪除即可。<dubbo關于序列化丟失字段的問題>
先看下序列化和反序列化的概念:
序列化:把對象轉換為字節序列的過程稱為對象的序列化。
反序列化:把字節序列恢復為對象的過程稱為對象的反序列化。
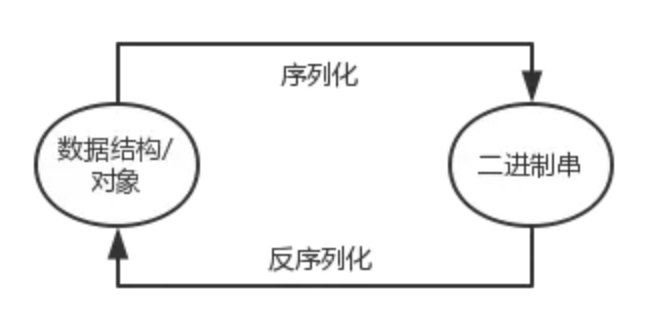
為什么要序列化?
序列化模塊主要為dubbo協議提供服務提供者和服務消費者之間的數據序列化功能。
dubbo是一種適合于高并發、小數據量的互聯網應用場景的框架,
而序列化對于遠程調用的響應速度,吞吐量,網絡帶寬消耗也其中至關重要的作用,是提高分布式系統性能的最關鍵因素之一。
dubbo框架原生支持四種序列化類型,且與協議一一對應,性能依次下降,分別為:
dubbo序列化:dubbo框架自身實現的一種Java序列化方案,但是不夠成熟,不建議在生產環境使用。(二進制序列化)
hessian2序列化(默認):hessian是一種跨語言的高效二進制序列化方式。(二進制序列化),后來新出了一些其他的跨語言序列化方式:Protostuff,ProtoBuf,Thrift,Avro,MsgPack等等
json序列化:目前有兩種實現,一種是采用的阿里的fastjson庫,另一種是采用dubbo中自己實現的簡單json庫,但其實現都不是特別成熟,而且json這種文本序列化性能一般不如上面兩種二進制序列化。(文本序列化)
jdk序列化:主要是采用JDK自帶的Java序列化實現,性能很不理想。專門針對java語言的序列化方式:Kryo,FST
使用Kryo和FST非常簡單,只需要在dubbo RPC的XML配置中添加一個屬性即可:
<dubbo:protocol name="dubbo" serialization="kryo"/>
在成為Apache孵化項目之后,對序列化方式進行了優化,支持的類型,分別為:fastjson,fst,hessian2,jdk和kryo。
其中fst為完全兼容JDK序列化協議的序列化框架,序列化速度是JDK的4到10倍,大小是JDK的1/3左右。
kryo序列化速度也比JDK的要快,并且大小是JDK的1/10左右。fst和kryo性能普通好于其他序列化方案,生產環境比較推薦使用。
常問面試題
1、dubbo 協議
默認就是走 dubbo 協議,單一長連接,進行的是 NIO 異步通信,基于 hessian 作為序列化協議。使用的場景是:傳輸數據量小(每次請求在 100kb 以內),但是并發量很高。
為了要支持高并發場景,一般是服務提供者就幾臺機器,但是服務消費者有上百臺,可能每天調用量達到上億次!此時用長連接是最合適的,就是跟每個服務消費者維持一個長連接就可以,可能總共就 100 個連接。然后后面直接基于長連接 NIO 異步通信,可以支撐高并發請求。
長連接,通俗點說,就是建立連接過后可以持續發送請求,無須再建立連接。
dubbo-keep-connection
而短連接,每次要發送請求之前,需要先重新建立一次連接。
dubbo-not-keep-connection
2、rmi 協議:走 Java 二進制序列化,多個短連接,適合消費者和提供者數量差不多的情況,適用于文件的傳輸,一般較少用。
3、hessian 協議:走 hessian 序列化協議,多個短連接,適用于提供者數量比消費者數量還多的情況,適用于文件的傳輸,一般較少用。
4、http 協議:走 json 序列化。
5、webservice:走 SOAP 文本序列化。
dubbo 支持 hession、Java 二進制序列化、json、SOAP 文本序列化多種序列化協議。但是 hessian 是其默認的序列化協議。
Hessian 的對象序列化機制有 8 種原始類型:
原始二進制數據
boolean
64-bit date(64 位毫秒值的日期)
64-bit double
32-bit int
64-bit long
null
UTF-8 編碼的 string
另外還包括 3 種遞歸類型:
list for lists and arrays
map for maps and dictionaries
object for objects
還有一種特殊的類型:
ref:用來表示對共享對象的引用。
其實 PB 之所以性能如此好,主要由于以下兩個原因:
1、使用 proto 編譯器,自動進行序列化和反序列化,速度非常快,應該比 XML 和 JSON 快上了 20~100 倍;
2、它的數據壓縮效果好,就是說它序列化后的數據量體積小。因為體積小,傳輸起來帶寬和速度上會有優化。
到此,關于“dubbo接口調用過程中,部分字段值丟失怎么辦”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





