溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何解析SOFARegistry,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
SOFAStack(Scalable Open Financial Architecture Stack) 是螞蟻金服自主研發的金融級分布式架構,包含了構建金融級云原生架構所需的各個組件,是在金融場景里錘煉出來的最佳實踐。
SOFARegistry 是螞蟻金服開源的具有承載海量服務注冊和訂閱能力的、高可用的服務注冊中心,在支付寶/螞蟻金服的業務發展驅動下,近十年間已經演進至第五代。
在前面的章節中我們已經提到,SOFARegistry 與其他服務發現領域的產品相比,最大的不同點在于支持海量數據。本章即將講述 SOFARegistry 在支撐海量數據上的一些特性。
本文將從如下幾個方面進行講解:
DataServer 總體架構:對 SOFARegistry 中支持海量數據的總體架構做一個簡述,講解數據分片和同步方案中所涉及到的關鍵技術點;
DataServer 啟動:講解 DataServer 啟動的服務,從而為接下來更直觀地理解數據分片、數據同步的觸發時機以及觸發方式等做一個鋪墊;
數據分片:講解 SOFARegistry 中采用的一致性 Hash 算法進行數據分片的緣由以及具體實現方法;
數據同步方案:講解 SOFARegistry 采用的數據同步方案;
在大部分的服務注冊中心系統中,每臺服務器都存儲著全量的服務注冊數據,服務器之間通過一致性協議(paxos、Raft 等)實現數據的復制,或者采用只保障最終一致性的算法,來實現異步數據復制。這樣的設計對于一般業務規模的系統來說沒有問題,而當應用于有著海量服務的龐大的業務系統來說,就會遇到性能瓶頸。
為解決這一問題,SOFARegistry 采用了數據分片的方法。全量服務注冊數據不再保存在單機里,而是分布于每個節點中,每臺服務器保存一定量的服務注冊數據,同時進行多副本備份,從理論上實現了服務無限擴容,且實現了高可用,最終達到支撐海量數據的目的。
在各種數據分片算法中,SOFARegistry 采用了業界主流的一致性 Hash 算法做數據分片,當節點動態擴縮容時,數據仍能均勻分布,維持數據的平衡。
在數據同步時,沒有采用與 Dynamo、Casandra、Tair、Codis、Redis cluster 等項目中類似的預分片機制,而是在 DataServer 內存里以 dataInfoId 為粒度進行操作日志記錄,這種實現方式在某種程度上也實現了“預分片”,從而保障了數據同步的有效性。
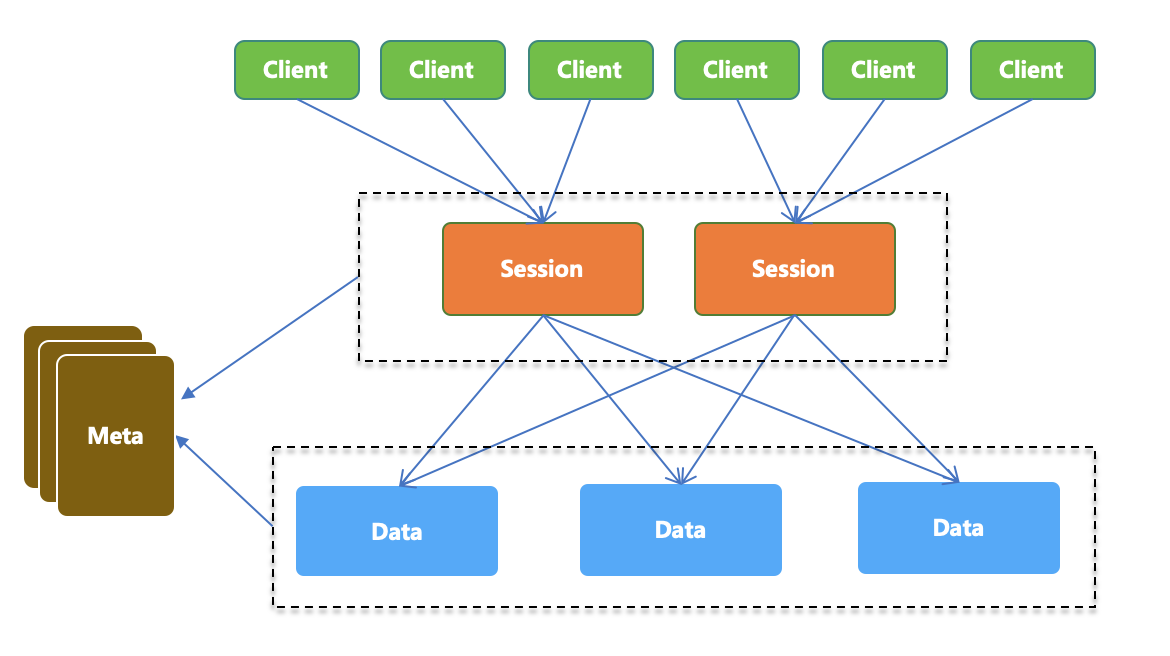
圖 1 SOFARegistry 總體架構圖
DataServer 模塊的各個 bean 在 JavaConfig 中統一配置,JavaConfig 類為 DataServerBeanConfiguration, 啟動入口類為 DataServerInitializer,該類不由 JavaConfig 管理配置,而是繼承了 SmartLifecycle 接口,在啟動時由 Spring 框架調用其 start 方法。
該方法中調用了 DataServerBootstrap#start 方法(圖 2),用于啟動一系列的初始化服務。
從代碼中可以看出,DataServer 服務在啟動時,會啟動 DataServer、DataSyncServer、HttpServer 三個 bolt 服務。在啟動這些 Server 之時,DataServer 注冊了一系列 Handler 來處理各類消息。
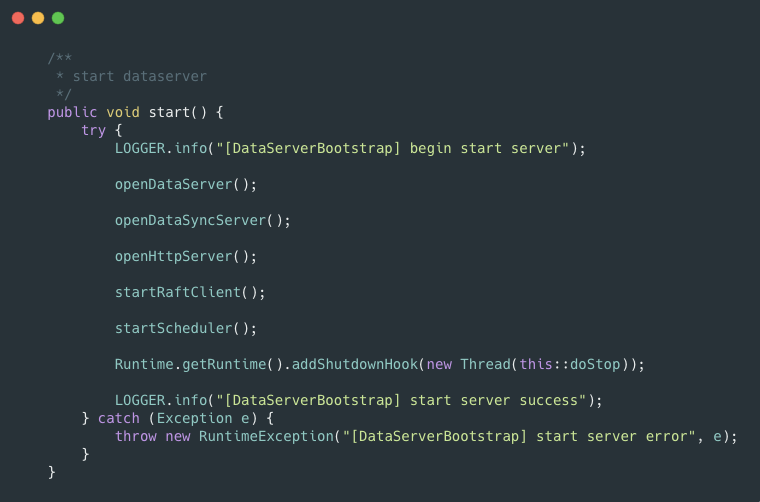
圖2 DataServerBootstrap 中的 start 方法
這幾個 Server 的作用如下:
DataServer:數據服務,獲取數據的推送,服務上下線通知等;
DataSyncServer:數據同步服務;
HttpServer:提供一系列 REST 接口,用于 dashboard 管理、數據查詢等;
各 Handler 具體作用如圖 3 所示:

圖 3 各 Handler 作用
同時啟動了 RaftClient 用于保障 DataServer 節點之間的分布式一致性,啟動了各項啟動任務,具體內容如圖 4 所示:

圖 4 DataServer 各項啟動任務
各個服務的啟動監聽端口如圖 5 所示:
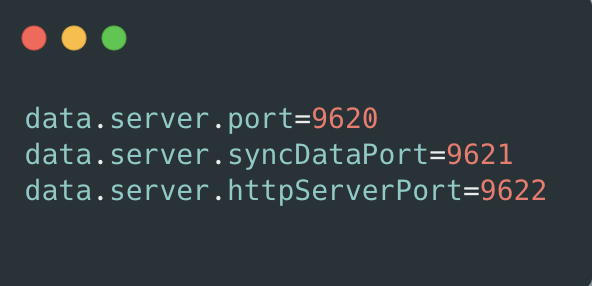
圖5 監聽端口
除上述的啟動服務之外,還有一些 bean 在模塊啟動時被初始化, 系統初始化時的 bean 都在 DataServerBeanConfiguration 里面通過 JavaConfig 來注冊,主要以如下幾個配置類體現(配置類會有變更,具體內容可以參照源碼實現):
DataServerBootstrapConfigConfiguration:該配置類主要作用是提供一些 DataServer 服務啟動時基本的 Bean,比如 DataServerConfig 基礎配置 Bean、DataNodeStatus 節點狀態 Bean、DatumCache 緩存 Bean 等;
LogTaskConfigConfiguration:該配置類主要用于提供一些日志處理相關的 Bean;
SessionRemotingConfiguration:該配置類主要作用是提供一些與 SessionServer 相互通信的 Bean,以及連接過程中的一些請求處理 Bean。比如 BoltExchange、JerseyExchange 等用于啟動服務的 Bean,還有節點上下線、數據發布等的 Bean,為關鍵配置類;
DataServerNotifyBeanConfiguration:該配置類中配置的 Bean 主要用于進行事件通知,如用于處理數據變更的 DataChangeHandler 等;
DataServerSyncBeanConfiguration:該配置類中配置的 Bean 主要用于數據同步操作;
DataServerEventBeanConfiguration:該配置類中配置的 Bean 主要用于處理與數據節點相關的事件,如事件中心 EventCenter、數據變化事件中心 DataChangeEventCenter 等;
DataServerRemotingBeanConfiguration:該配置類中配置的 Bean 主要用于 DataServer 的連接管理;
ResourceConfiguration:該配置類中配置的 Bean 主要用于提供一些 Rest 接口資源;
AfterWorkingProcessConfiguration:該配置類中配置一些后處理 Handler Bean,用于處理一些業務邏輯結束后的后處理動作;
ExecutorConfiguration:該配置類主要配置一些線程池 Bean,用于執行不同的任務;
數據分片機制是 SOFARegistry 支撐海量數據的核心所在,DataServer 負責存儲具體的服務數據,數據按照 dataInfoId 進行一致性 Hash 分片存儲,支持多副本備份,保證數據的高可用。
(對一致性 Hash 算法感興趣想深入了解的同學可以閱讀該算法的提出者 Karger 及其合作者的原始論文:Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web。)
在講解 SOFARegistry 的數據分片之前,我們先看下最簡單的傳統數據分片 Hash 算法。
在傳統的數據分片算法中,先對每個節點的 ID 進行 1 到 K 的標號,然后再對每個要存儲到節點上的數據使用 Hash 算法,計算之后的值對 K 取模,所得結果就是要落在的節點 ID。
該算法簡單且常用,很多場景中都使用該算法進行數據分片。
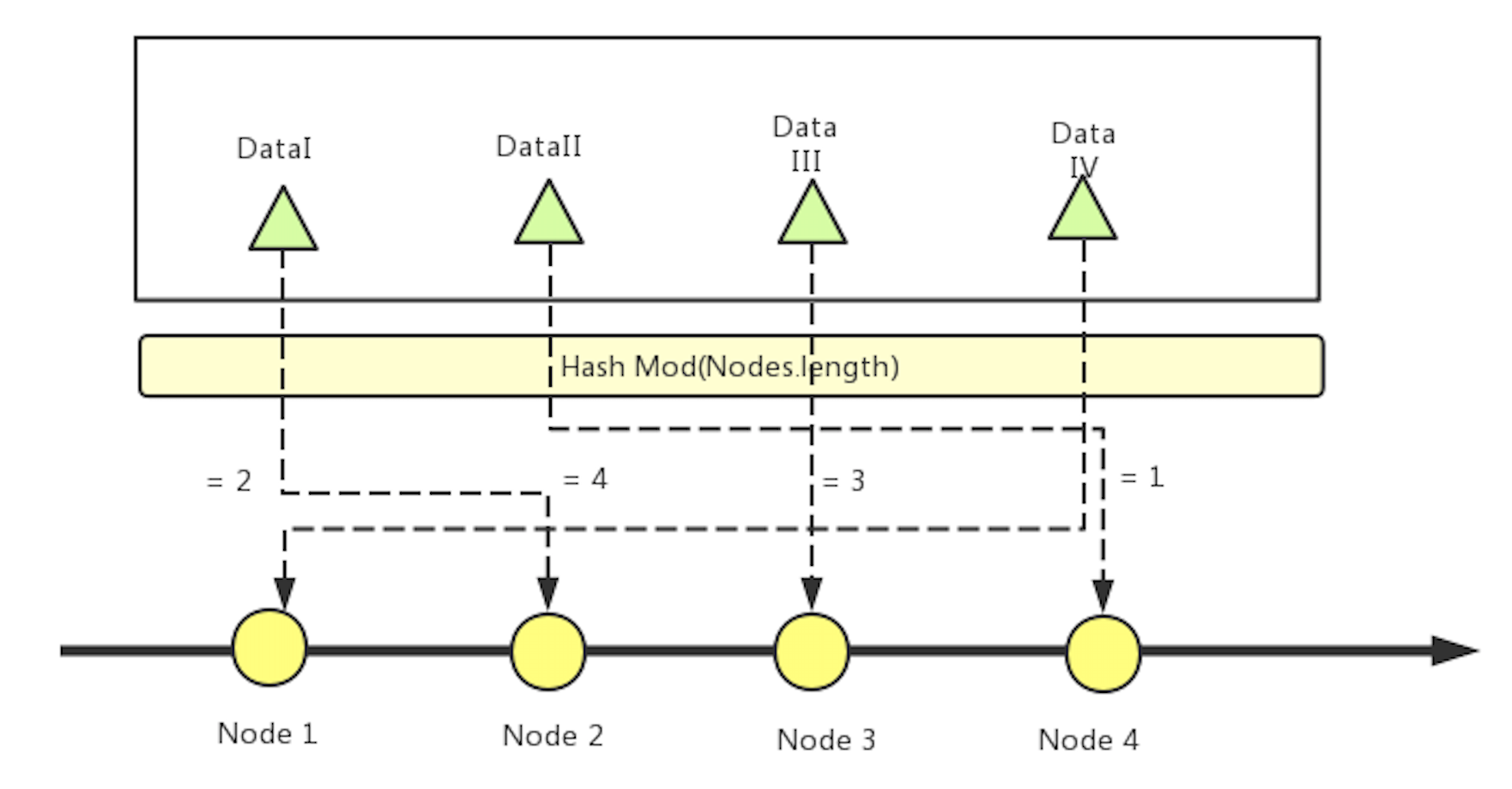 圖 6 傳統 Hash 分片算法
圖 6 傳統 Hash 分片算法
在這種算法下,當某個節點下線(如圖 6 中的 Node 2),該節點之后的所有節點需要重新標號。所有數據要重新求 Hash 值取模,再重新存儲到相應節點中。(圖 7)
在海量數據場景下,該方式將會帶來很大的性能開銷。
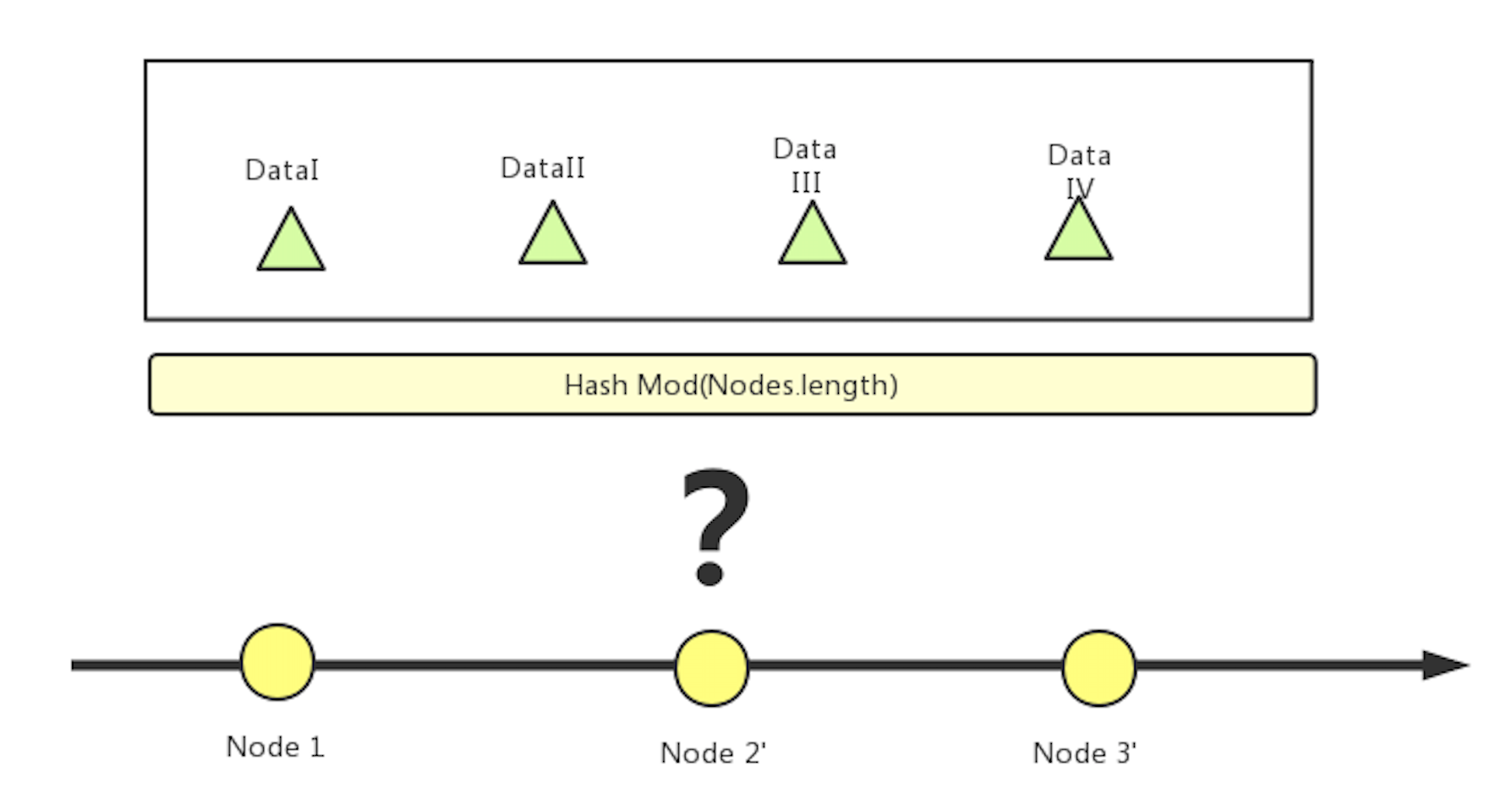
圖 7 傳統 Hash 分片算法,某個節點下線后將影響全局數據分布
為了使服務節點上下線不會影響到全局數據的分布,在實際的生產環境中,很多系統使用的是一致性 Hash 算法進行數據分片。業界使用一致性 Hash 的代表項目有 Memcached、Twemproxy 等。
一致性 Hash 算法采用了 $$2^{32}$$ 個桶來存儲所有的 Hash 值,0 ~ $$2^{32}-1$$ 作為取值范圍,并且形成一個環。
在圖 8 中,NodeA#1、NodeB#1、NodeC#1 分別為 A、B、C 三個節點的 ID 經過一致性 Hash 算法的計算后落在環上的位置。
三角形為不同的數據經過一致性 Hash 算法之后落在環上的位置。每個數據經過順時針,找尋最近的一個節點,作為數據存儲的節點。
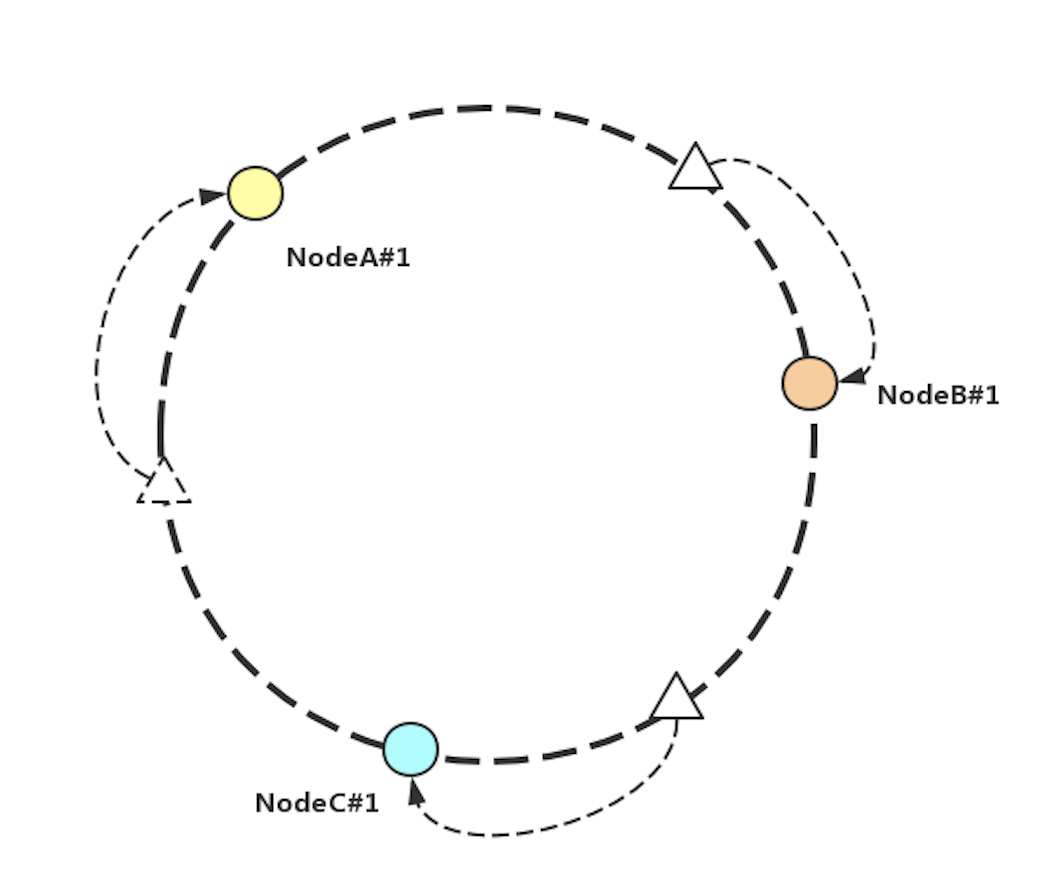
圖 8 一致性 Hash 算法
從圖 8 中不難想到,當有節點上下線時,僅僅影響到上下線節點與該節點逆時針方向最近的一個節點之間的數據分布。此時,只需要對掉落到這個區間內的數據重排即可。(如圖 9)
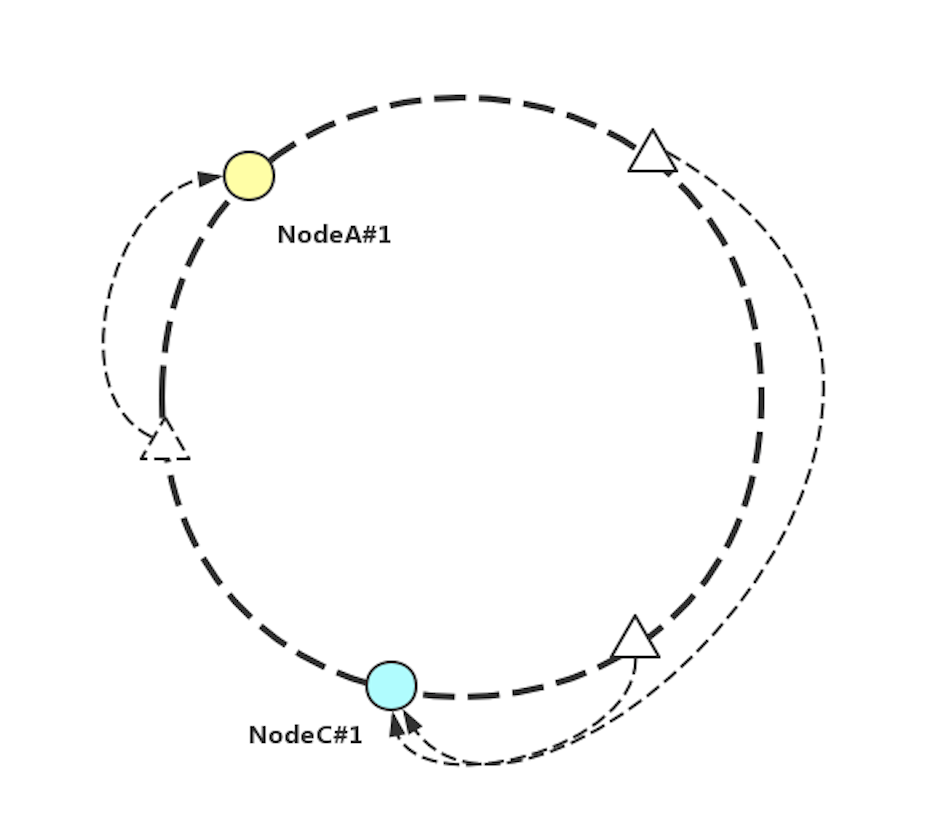
圖 9 一致性 Hash 算法中 NodeB#1 下線
該算法中,每個節點的 ID 需要通過一致性 Hash 算法計算后映射到圓環上,以此帶來了一致性 Hash 算法的兩個特點:
當節點總量較少時,可以虛擬多個虛擬節點(如圖 10,實際中可能會交叉排布,在這里方便描述則放在一起),當虛擬節點足夠多時,可以保障數據在真實節點上面能夠均勻分散分布,這是一致性 Hash 算法的優點;
采用一致性 Hash 之后,數據在節點環中的分布范圍不固定。當節點動態擴縮容之后,部分數據要重新分布,在數據同步時會帶來一定的問題;
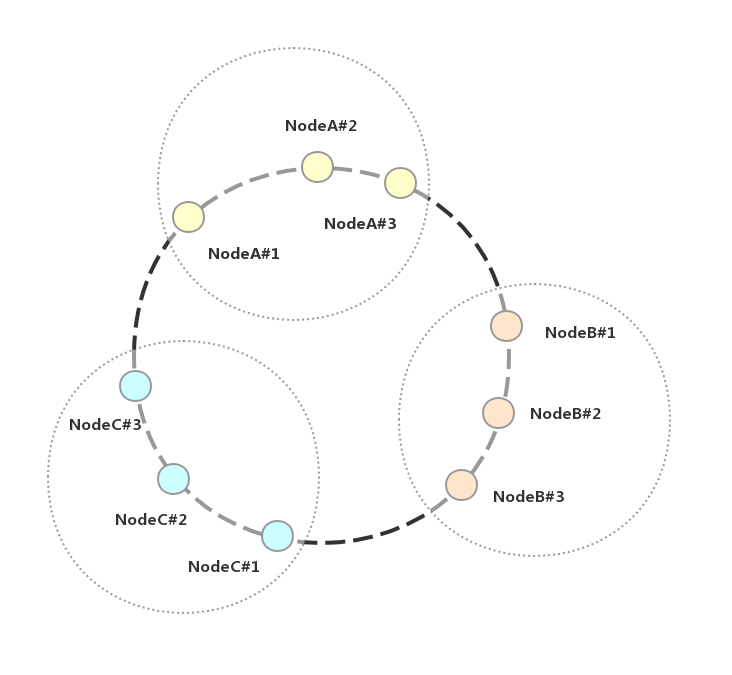
圖 10 虛擬節點排布
在 SOFARegistry 中,由 ConsistentHash 類來實現一致性 Hash 類圖,如圖 11 所示:

圖 11 SOFARegistry 的一致性 Hash 類圖
在該類中,SIGN 為 ID 的分隔符,numberOfReplicas 則是每個節點的虛擬節點數,realNodes 為節點列表,hashFunction 為采用的 Hash 算法,circle 為預分片機制中的 Hash 環。
ConsistentHash 默認采用了 MD5 摘要算法來進行 hash,同時構造函數支持 hash 函數定制化,用戶可以定制自己的 Hash 算法。同時,該類中 circle 的實現為 TreeMap,巧妙地使用了 TreeMap 的 tailMap() 方法來實現一致性 Hash 的節點查找能力,數據最近的節點 hash 值計算代碼如圖 12 所示:

圖 12 數據最近節點 hash 值計算方法
傳統的一致性 Hash 算法有數據分布范圍不固定的特性,該特性使得服務注冊數據在服務器節點宕機、下線、擴容之后,需要重新存儲排布,這為數據的同步帶來了困難。大多數的數據同步操作是利用操作日志記錄的內容來進行的,傳統的一致性 Hash 算法中,數據的操作日志是以節點分片來劃分的,節點變化導致數據分布范圍的變化。
在計算機領域,大多數難題都可以通過增加一個中間層來解決,那么對于數據分布范圍不固定所導致的數據同步難題,也可以通過同樣的思路來解決。
這里的問題在于,當節點下線后,若再以當前存活節點 ID 一致性 Hash 值去同步數據,就會導致已失效節點的數據操作日志無法獲取到,既然數據存儲在會變化的地方無法進行數據同步,那么如果把數據存儲在不會變化的地方是否就能保證數據同步的可行性呢?答案是肯定的,這個中間層就是預分片層,通過把數據與預分片這個不會變化的層相互對應就能解決這個數據同步的難題。
目前業界主要代表項目如 Dynamo、Casandra、Tair、Codis、Redis cluster 等,都采用了預分片機制來實現這個不會變化的層。
事先將數據存儲范圍等分為 N 個 slot 槽位,數據直接與 slot 相對應,數據的操作日志與相應的 solt 對應,slot 的數目不會因為節點的上下線而產生變化,由此保證了數據同步的可行性。除此之外,還需要引進“路由表”的概念,如圖 13,“路由表”負責存放每個節點和 N 個 slot 的映射關系,并保證盡量把所有 slot 均勻地分配給每個節點。這樣,當節點上下線時,只需要修改路由表內容即可。保持 slot 不變,即保證了彈性擴縮容,也大大降低了數據同步的難度。
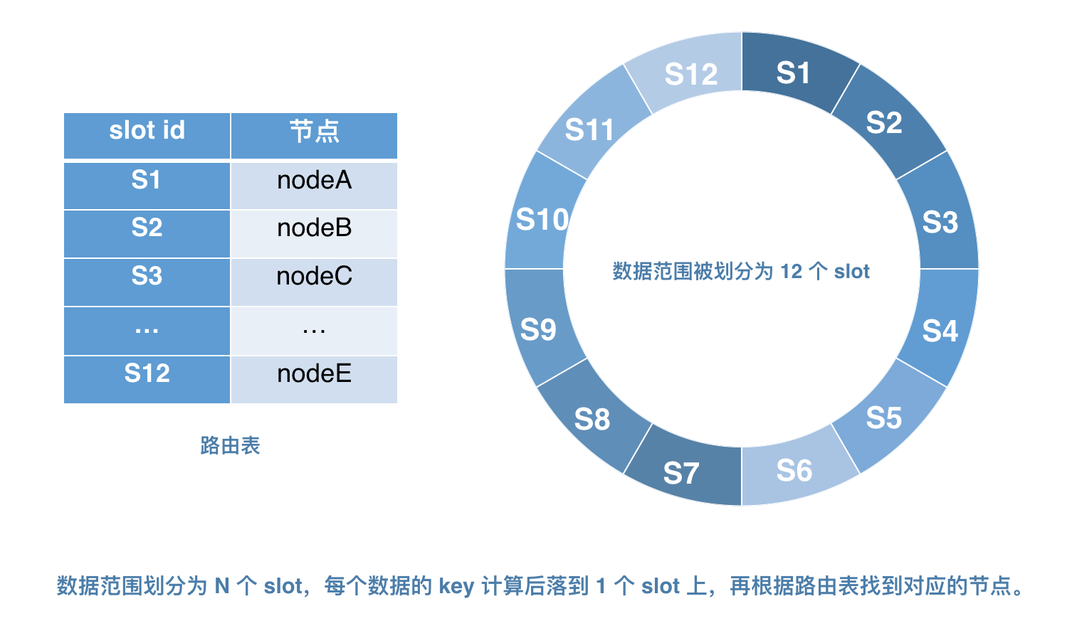
圖 13 預分片機制
SOFARegistry 為了實現服務注冊數據的分布式存儲,采用了基于一致性 Hash 的數據分片。而由于歷史原因,為了實現數據在節點間的同步,則采用了在 DataServer 之間以 dataInfoId 為粒度進行數據同步。
當 DataServer 節點初始化成功后,會啟動任務自動去連接 MetaServer。該任務會往事件中心 EventCenter 注冊一個 DataServerChangeEvent 事件,該事件注冊后會被觸發,之后將對新增節點計算 Hash 值,同時進行納管分片。
DataServerChangeEvent 事件被觸發后,由 DataServerChangeEventHandler 來進行相應的處理,分別分為如下一些步驟:
初始化當前數據節點的一致性 Hash 值,把當前節點添加進一致性的 Hash 環中。(圖 14)

圖 14 初始化一致性 Hash 環
獲取變更了的 DataServer 節點,這些節點在啟動 DataServer 服務的時候從 MetaServer 中獲取到的,并且通過 DataServerChangeEvent 事件中的 DataServerChangeItem 傳入。(圖 15)

圖 15 獲取變更了的 DataServer 節點
獲取了當前的 DataServer 節點之后,若節點列表非空,則遍歷每個節點,建立當前節點與其余數據節點之間的連接,同時刪除本地維護的不在節點列表中的節點數據。同時,若當前節點是 DataCenter 節點,則觸發 LocalDataServerChangeEvent 事件。
至此,節點初始化以及分片入 Hash 環的工作已經完成。
數據節點相關數據,儲存在 Map 中,相關的數據結構如圖 16 所示。

圖 16 DataServer 節點一致性 Hash 存儲結構
當服務上線時,會計算新增服務的 dataInfoId Hash 值,從而對該服務進行分片,最后尋找最近的一個節點,存儲到相應的節點上。
前文已經說過,DataServer 服務在啟動時添加了 publishDataProcessor 來處理相應的服務發布者數據發布請求,該 publishDataProcessor 就是 PublishDataHandler。當有新的服務發布者上線,DataServer 的 PublishDataHandler 將會被觸發。
該 Handler 首先會判斷當前節點的狀態,若是非工作狀態則返回請求失敗。若是工作狀態,則觸發數據變化事件中心 DataChangeEventCenter 的 onChange 方法。
DataChangeEventQueue 中維護著一個 DataChangeEventQueue 隊列數組,數組中的每個元素是一個事件隊列。當上文中的 onChange 方法被觸發時,會計算該變化服務的 dataInfoId 的 Hash 值,從而進一步確定出該服務注冊數據所在的隊列編號,進而把該變化的數據封裝成一個數據變化對象,傳入到隊列中。
DataChangeEventQueue#start 方法在 DataChangeEventCenter 初始化的時候被一個新的線程調用,該方法會源源不斷地從隊列中獲取新增事件,并且進行分發。新增數據會由此添加進節點內,實現分片。
SOFARegistry 是 Client、SessionServer、DataServer 三層架構,同時通過 MetaServer 管理 Session 和 Data 集群,在服務注冊的過程中,數據既有層間的數據同步,也有層內的節點間同步。
Client 端在本地內存內已經存儲了需要訂閱和發布的服務數據,在連接上 Session 后會回放訂閱和發布數據給 Session,最終再發布到 Data。同時,Session 存儲著客戶端發布的所有 Pub 數據,定期通過數據比對保持和 Data 一致性。當數據發生變更時,持有數據一方的 Data 發起變更通知,需要同步的 SessionServer 進行版本對比,在判斷出數據需要更新時,將拉取最新的數據操作日志。
操作日志存儲采用堆棧方式,獲取日志是通過當前版本號在堆棧內所處位置,把所有版本之后的操作日志同步過來執行。
為保障 Data 層數據的可用性,SOFARegistry 做了 Data 層的多副本機制。當有 Data 節點縮容、宕機發生時,備份節點可以立即通過備份數據生效成為主節點,對外提供服務,并且把相應的備份數據再按照新列表計算備份給新的節點。
當有 Data 節點擴容時,新增節點進入初始化狀態,期間禁止新數據寫入,對于讀取請求會轉發到后續可用的 Data 節點獲取數據。在其他節點的備份數據按照新節點信息同步完成后,新擴容的 Data 節點狀態變成 Working,開始對外提供服務。
在海量服務注冊場景下,為保障 DataServer 能否無限擴容面對海量數據的業務場景,與其他服務注冊中心不同的是,SOFARegistry 采用了一致性 Hash 算法進行數據分片,保障了數據的可擴展性。同時,通過在 DataServer 內存里以 dataInfoId 的粒度記錄操作日志,并且在 DataServer 之間也是以 dataInfoId 的粒度去做數據同步,保障了數據的一致性。
關于如何解析SOFARegistry就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





