溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這段時間一直在接觸學習hadoop方面的知識,所以說對自然語言處理技術也是做了一些了解。網絡上關于自然語言處理技術的分享文章很多,今天就給大家分享一下HanLP方面的內容。
自然語言處理技術其實是所有與自然語言的計算機處理相關聯的技術的統稱,自然語言處理技術應用的目的是為了能夠讓計算機理解和接收我們用自然語言輸入的指令,實現從將我們人類的語言翻譯成計算機能夠理解的并且不會產生歧義的一種語言。接合目前的大數據以及人工智能,自然語言處理技術的快速發展能夠很好的助力人工智能的發展。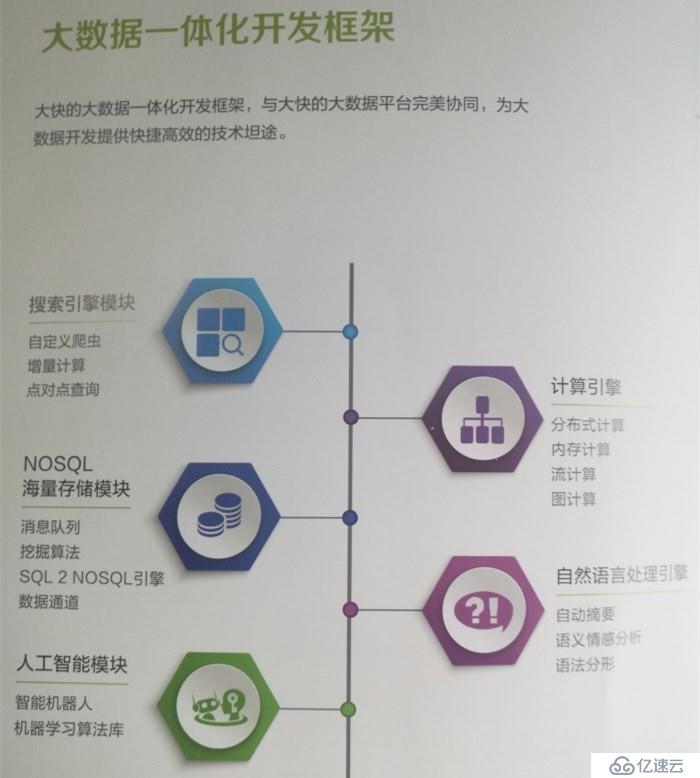
(大快DKhadoop一體化開發框架)
這里要分享的HanLP是我在學習使用大快DKhadoop大數據一體化平臺時使用到的自然語言處理技術,使用這個組建可以很高效的進行自然語言的處理工作,比如進行文章摘要,語義判別以及提高內容檢索的精確度和有效性等。
本想找個通俗的案例來介紹一下HanLP,一時間也沒想到什么好的案例,索性就從HanLp數據結構HE 分詞簡單介紹下吧。
首先我們來看了解下HanLP的數據結構:
二分tire樹:Tire樹是一種前綴壓縮結構,可以壓縮存大量字符串,并提供速度高于Map的get操作。HanLP中的trie樹采用有序數組儲存子節點,通過二分搜索算法檢索,可以提供比TreeMap更快的查詢速度。
不同于父節點儲存子節點引用的普通trie樹,雙數組trie樹將節點的從屬關系轉化為字符內碼的加法與校驗操作
對于一個接收字符c從狀態s移動到t的轉移,需滿足條件是:
base[s] + c = t
check[t] = s比如:base[一號] + 店 = 一號店
check[一號店] = 一號
相較于trie樹的前綴壓縮(success表),AC自動機還實現了后綴壓縮(output表)
在匹配失敗時,AC自動機會跳轉到最可能成功的狀態(fail指針)
關于HanLP分詞
1、詞典分詞
基于雙數組trie樹或ACDAT的詞典最長分詞(即從詞典中找出所有可能的詞,順序選擇最長的詞語)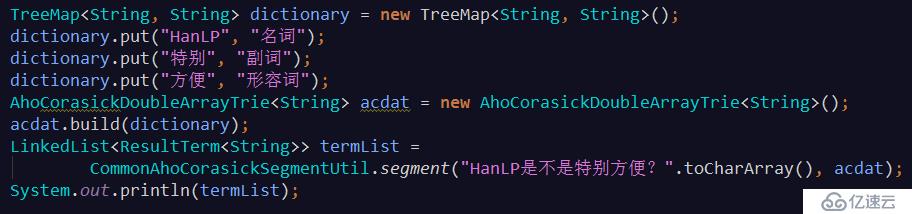
輸出:[HanLP/名詞, 是不是/null, 特別/副詞, 方便/形容詞, ?/null]
2、NGram分詞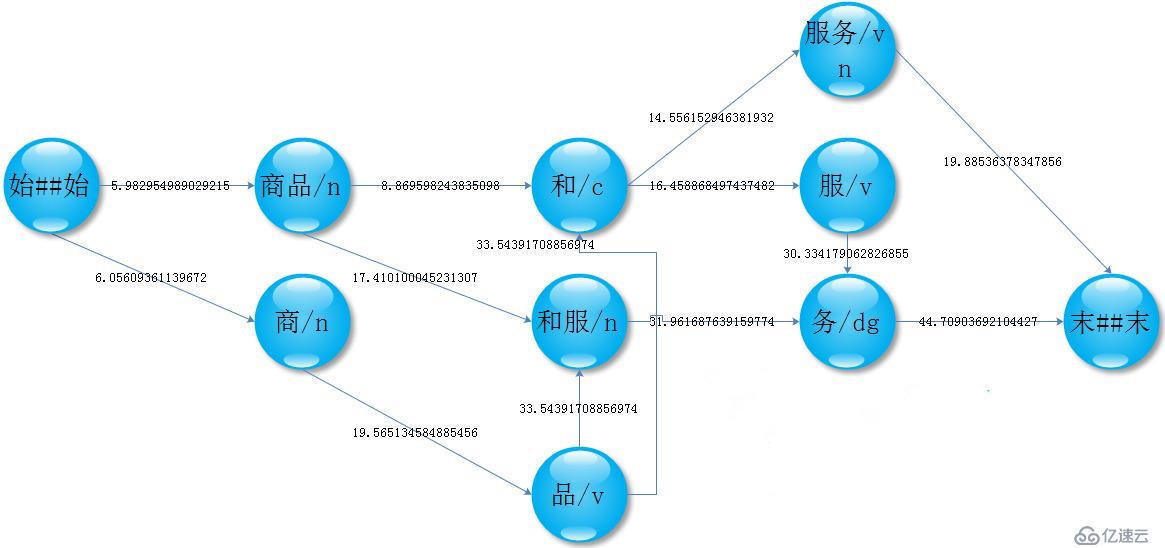
統計語料庫中的BiGram,根據轉移概率,選出最可能的句子,達到排除歧義的目的
3、HMM2分詞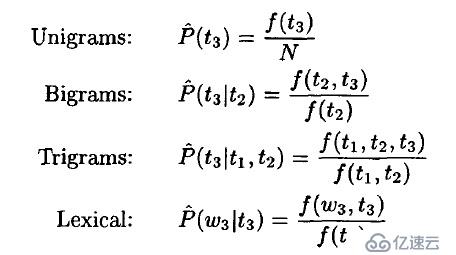
這是一種由字構詞的生成式模型,由二階隱馬模型提供序列標注
被稱為TnT Tagger,特點是利用低階事件平滑高階事件,彌補高階模型的數據稀疏問題
4、CRF分詞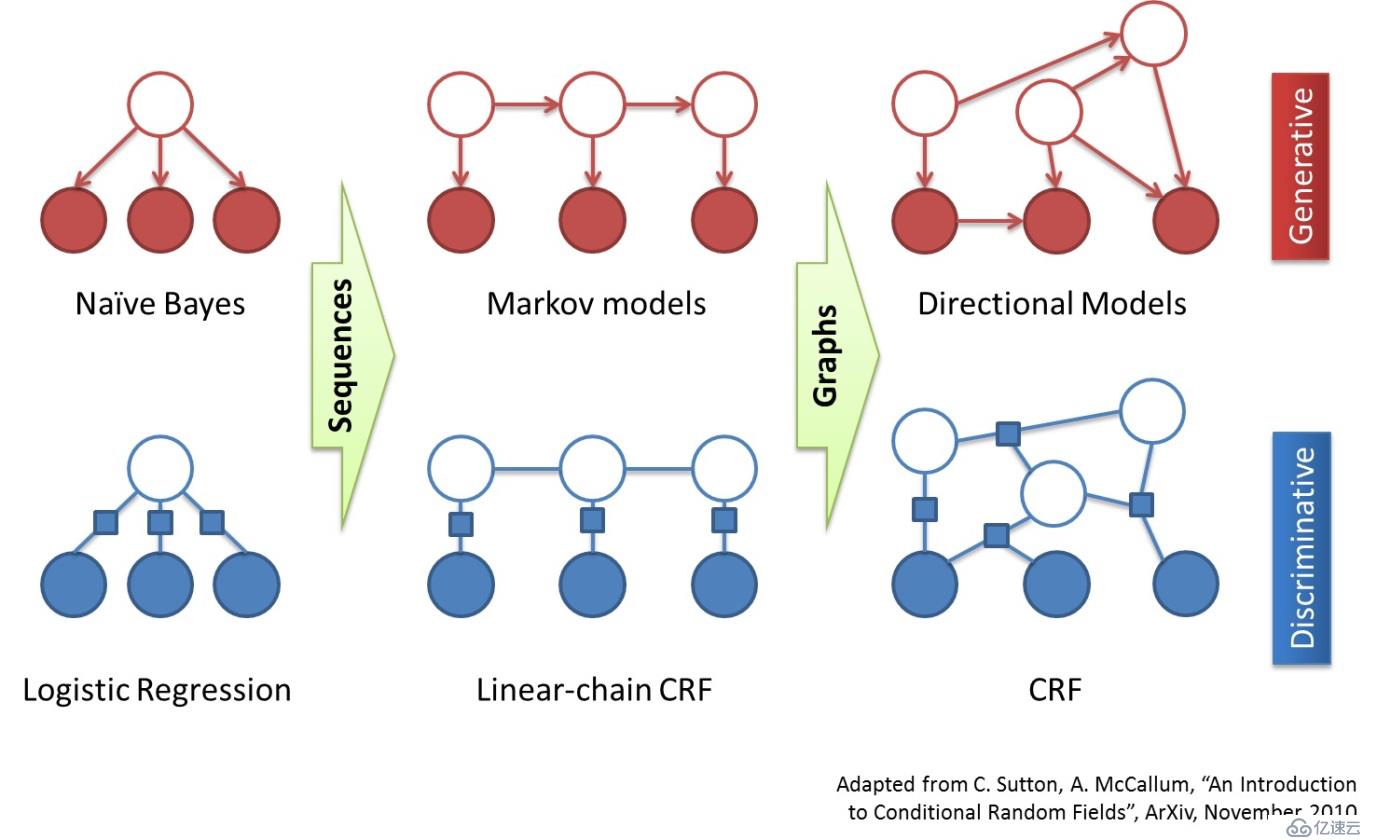
這是一種由字構詞的生成式模型,由CRF提供序列標注
相較于HMM,CRF的優點是能夠利用更多特征、對OOV分詞效果好,缺點是占內存大、解碼慢。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





