溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“java分布式鎖的原理以及實現方法”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“java分布式鎖的原理以及實現方法”吧!
學過Java多線程的應該都知道什么是鎖,沒學過的也不用擔心,Java中的鎖可以簡單的理解為多線程情況下訪問臨界資源的一種線程同步機制。
在學習或者使用Java的過程中進程會遇到各種各樣的鎖的概念:公平鎖、非公平鎖、自旋鎖、可重入鎖、偏向鎖、輕量級鎖、重量級鎖、讀寫鎖、互斥鎖等。文獻參考《Java多線程核心技術》
一、為什么要使用分布式鎖
我們在開發應用的時候,如果需要對某一個共享變量進行多線程同步訪問的時候,可以使用我們學到的Java多線程的18般武藝進行處理,并且可以完美的運行,毫無Bug!
注意這是單機應用,也就是所有的請求都會分配到當前服務器的JVM內部,然后映射為操作系統的線程進行處理!而這個共享變量只是在這個JVM內部的一塊內存空間!
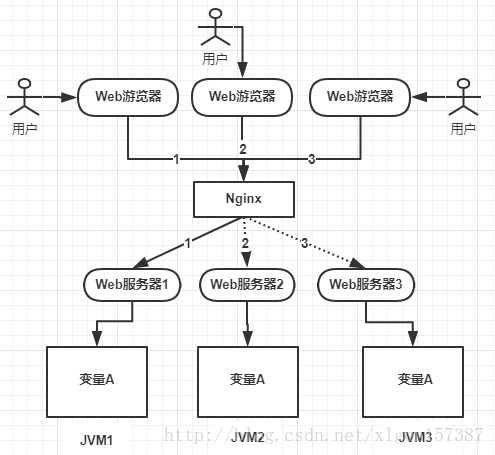
后來業務發展,需要做集群,一個應用需要部署到幾臺機器上然后做負載均衡,大致如下圖:
上圖可以看到,變量A存在JVM1、JVM2、JVM3三個JVM內存中(這個變量A主要體現是在一個類中的一個成員變量,是一個有狀態的對象,例如:UserController控制器中的一個整形類型的成員變量),如果不加任何控制的話,變量A同時都會在JVM分配一塊內存,三個請求發過來同時對這個變量操作,顯然結果是不對的!即使不是同時發過來,三個請求分別操作三個不同JVM內存區域的數據,變量A之間不存在共享,也不具有可見性,處理的結果也是不對的!
如果我們業務中確實存在這個場景的話,我們就需要一種方法解決這個問題!
為了保證一個方法或屬性在高并發情況下的同一時間只能被同一個線程執行,在傳統單體應用單機部署的情況下,可以使用Java并發處理相關的API(如ReentrantLock或Synchronized)進行互斥控制。在單機環境中,Java中提供了很多并發處理相關的API。但是,隨著業務發展的需要,原單體單機部署的系統被演化成分布式集群系統后,由于分布式系統多線程、多進程并且分布在不同機器上,這將使原單機部署情況下的并發控制鎖策略失效,單純的Java API并不能提供分布式鎖的能力。為了解決這個問題就需要一種跨JVM的互斥機制來控制共享資源的訪問,這就是分布式鎖要解決的問題!
二、分布式鎖應該具備哪些條件
在分析分布式鎖的三種實現方式之前,先了解一下分布式鎖應該具備哪些條件:
1、在分布式系統環境下,一個方法在同一時間只能被一個機器的一個線程執行;
2、高可用的獲取鎖與釋放鎖;
3、高性能的獲取鎖與釋放鎖;
4、具備可重入特性;
5、具備鎖失效機制,防止死鎖;
6、具備非阻塞鎖特性,即沒有獲取到鎖將直接返回獲取鎖失敗。
三、分布式鎖的三種實現方式
目前幾乎很多大型網站及應用都是分布式部署的,分布式場景中的數據一致性問題一直是一個比較重要的話題。分布式的CAP理論告訴我們“任何一個分布式系統都無法同時滿足一致性(Consistency)、可用性(Availability)和分區容錯性(Partition tolerance),最多只能同時滿足兩項。”所以,很多系統在設計之初就要對這三者做出取舍。在互聯網領域的絕大多數的場景中,都需要犧牲強一致性來換取系統的高可用性,系統往往只需要保證“最終一致性”,只要這個最終時間是在用戶可以接受的范圍內即可。
在很多場景中,我們為了保證數據的最終一致性,需要很多的技術方案來支持,比如分布式事務、分布式鎖等。有的時候,我們需要保證一個方法在同一時間內只能被同一個線程執行。
基于數據庫實現分布式鎖;
基于緩存(Redis等)實現分布式鎖;
基于Zookeeper實現分布式鎖;
盡管有這三種方案,但是不同的業務也要根據自己的情況進行選型,他們之間沒有最好只有更適合!
四、基于數據庫的實現方式
基于數據庫的實現方式的核心思想是:在數據庫中創建一個表,表中包含方法名等字段,并在方法名字段上創建唯一索引,想要執行某個方法,就使用這個方法名向表中插入數據,成功插入則獲取鎖,執行完成后刪除對應的行數據釋放鎖。
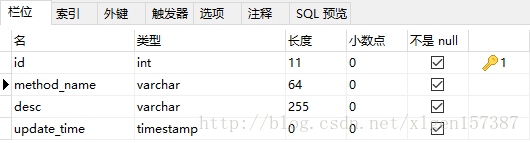
(1)創建一個表:
DROP TABLE IF EXISTS `method_lock`;
CREATE TABLE `method_lock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`method_name` varchar(64) NOT NULL COMMENT '鎖定的方法名',
`desc` varchar(255) NOT NULL COMMENT '備注信息',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='鎖定中的方法';
(2)想要執行某個方法,就使用這個方法名向表中插入數據:
INSERT INTO method_lock (method_name, desc) VALUES ('methodName', '測試的methodName');
1
因為我們對method_name做了唯一性約束,這里如果有多個請求同時提交到數據庫的話,數據庫會保證只有一個操作可以成功,那么我們就可以認為操作成功的那個線程獲得了該方法的鎖,可以執行方法體內容。
(3)成功插入則獲取鎖,執行完成后刪除對應的行數據釋放鎖:
delete from method_lock where method_name ='methodName';
1
注意:這只是使用基于數據庫的一種方法,使用數據庫實現分布式鎖還有很多其他的玩法!
使用基于數據庫的這種實現方式很簡單,但是對于分布式鎖應該具備的條件來說,它有一些問題需要解決及優化:
1、因為是基于數據庫實現的,數據庫的可用性和性能將直接影響分布式鎖的可用性及性能,所以,數據庫需要雙機部署、數據同步、主備切換;
2、不具備可重入的特性,因為同一個線程在釋放鎖之前,行數據一直存在,無法再次成功插入數據,所以,需要在表中新增一列,用于記錄當前獲取到鎖的機器和線程信息,在再次獲取鎖的時候,先查詢表中機器和線程信息是否和當前機器和線程相同,若相同則直接獲取鎖;
3、沒有鎖失效機制,因為有可能出現成功插入數據后,服務器宕機了,對應的數據沒有被刪除,當服務恢復后一直獲取不到鎖,所以,需要在表中新增一列,用于記錄失效時間,并且需要有定時任務清除這些失效的數據;
4、不具備阻塞鎖特性,獲取不到鎖直接返回失敗,所以需要優化獲取邏輯,循環多次去獲取。
5、在實施的過程中會遇到各種不同的問題,為了解決這些問題,實現方式將會越來越復雜;依賴數據庫需要一定的資源開銷,性能問題需要考慮。
五、基于Redis的實現方式
1、選用Redis實現分布式鎖原因:
(1)Redis有很高的性能;
(2)Redis命令對此支持較好,實現起來比較方便
2、使用命令介紹:
(1)SETNX
SETNX key val:當且僅當key不存在時,set一個key為val的字符串,返回1;若key存在,則什么都不做,返回0。
1
(2)expire
expire key timeout:為key設置一個超時時間,單位為second,超過這個時間鎖會自動釋放,避免死鎖。
1
(3)delete
delete key:刪除key
1
在使用Redis實現分布式鎖的時候,主要就會使用到這三個命令。
3、實現思想:
(1)獲取鎖的時候,使用setnx加鎖,并使用expire命令為鎖添加一個超時時間,超過該時間則自動釋放鎖,鎖的value值為一個隨機生成的UUID,通過此在釋放鎖的時候進行判斷。
(2)獲取鎖的時候還設置一個獲取的超時時間,若超過這個時間則放棄獲取鎖。
(3)釋放鎖的時候,通過UUID判斷是不是該鎖,若是該鎖,則執行delete進行鎖釋放。
4、 分布式鎖的簡單實現代碼:
**
* 分布式鎖的簡單實現代碼
* Created by liuyang on 2017/4/20.
*/
public class DistributedLock {
private final JedisPool jedisPool;
public DistributedLock(JedisPool jedisPool) {
this.jedisPool = jedisPool;
}
/**
* 加鎖
* @param lockName 鎖的key
* @param acquireTimeout 獲取超時時間
* @param timeout 鎖的超時時間
* @return 鎖標識
*/
public String lockWithTimeout(String lockName, long acquireTimeout, long timeout) {
Jedis conn = null;
String retIdentifier = null;
try {
// 獲取連接
conn = jedisPool.getResource();
// 隨機生成一個value
String identifier = UUID.randomUUID().toString();
// 鎖名,即key值
String lockKey = "lock:"> // 超時時間,上鎖后超過此時間則自動釋放鎖
int lockExpire = (int) (timeout / 1000);
// 獲取鎖的超時時間,超過這個時間則放棄獲取鎖
long end = System.currentTimeMillis() + acquireTimeout;
while (System.currentTimeMillis() < end) {
if (conn.setnx(lockKey, identifier) == 1) {
conn.expire(lockKey, lockExpire);
// 返回value值,用于釋放鎖時間確認
retIdentifier = identifier;
return retIdentifier;
}
// 返回-1代表key沒有設置超時時間,為key設置一個超時時間
if (conn.ttl(lockKey) == -1) {
conn.expire(lockKey, lockExpire);
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return retIdentifier;
}
/**
* 釋放鎖
* @param lockName 鎖的key
* @param identifier 釋放鎖的標識
* @return
*/
public boolean releaseLock(String lockName, String identifier) {
Jedis conn = null;
String lockKey = "lock:" + lockName;
boolean retFlag = false;
try {
conn = jedisPool.getResource();
while (true) {
// 監視lock,準備開始事務
conn.watch(lockKey);
// 通過前面返回的value值判斷是不是該鎖,若是該鎖,則刪除,釋放鎖
if (identifier.equals(conn.get(lockKey))) {
Transaction transaction = conn.multi();
transaction.del(lockKey);
List<Object> results = transaction.exec();
if (results == null) {
continue;
}
retFlag = true;
}
conn.unwatch();
break;
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return retFlag;
}
}
5、測試剛才實現的分布式鎖
例子中使用50個線程模擬秒殺一個商品,使用–運算符來實現商品減少,從結果有序性就可以看出是否為加鎖狀態。
模擬秒殺服務,在其中配置了jedis線程池,在初始化的時候傳給分布式鎖,供其使用。
/**
* Created by liuyang on 2017/4/20.
*/
public class Service {
private static JedisPool pool = null;
private DistributedLock lock = new DistributedLock(pool);
int n = 500;
static {
JedisPoolConfig config = new JedisPoolConfig();
// 設置最大連接數
config.setMaxTotal(200);
// 設置最大空閑數
config.setMaxIdle(8);
// 設置最大等待時間
config.setMaxWaitMillis(1000 * 100);
// 在borrow一個jedis實例時,是否需要驗證,若為true,則所有jedis實例均是可用的
config.setTestOnBorrow(true);
pool = new JedisPool(config, "127.0.0.1", 6379, 3000);
}
public void seckill() {
// 返回鎖的value值,供釋放鎖時候進行判斷
String identifier = lock.lockWithTimeout("resource", 5000, 1000);
System.out.println(Thread.currentThread().getName() + "獲得了鎖");
System.out.println(--n);
lock.releaseLock("resource", identifier);
}
}
模擬線程進行秒殺服務:
public class ThreadA extends Thread {
private Service service;
public ThreadA(Service service) {
this.service = service;
}
@Override
public void run() {
service.seckill();
}
}
public class Test {
public static void main(String[] args) {
Service service = new Service();
for (int i = 0; i < 50; i++) {
ThreadA threadA = new ThreadA(service);
threadA.start();
}
}
}
結果如下,結果為有序的:
若注釋掉使用鎖的部分:
public void seckill() {
// 返回鎖的value值,供釋放鎖時候進行判斷
//String indentifier = lock.lockWithTimeout("resource", 5000, 1000);
System.out.println(Thread.currentThread().getName() + "獲得了鎖");
System.out.println(--n);
//lock.releaseLock("resource", indentifier);
}
從結果可以看出,有一些是異步進行的:
5、基于ZooKeeper的實現方式
ZooKeeper是一個為分布式應用提供一致性服務的開源組件,它內部是一個分層的文件系統目錄樹結構,規定同一個目錄下只能有一個唯一文件名。基于ZooKeeper實現分布式鎖的步驟如下:
(1)創建一個目錄mylock;
(2)線程A想獲取鎖就在mylock目錄下創建臨時順序節點;
(3)獲取mylock目錄下所有的子節點,然后獲取比自己小的兄弟節點,如果不存在,則說明當前線程順序號最小,獲得鎖;
(4)線程B獲取所有節點,判斷自己不是最小節點,設置監聽比自己次小的節點;
(5)線程A處理完,刪除自己的節點,線程B監聽到變更事件,判斷自己是不是最小的節點,如果是則獲得鎖。
這里推薦一個Apache的開源庫Curator,它是一個ZooKeeper客戶端,Curator提供的InterProcessMutex是分布式鎖的實現,acquire方法用于獲取鎖,release方法用于釋放鎖。
優點:具備高可用、可重入、阻塞鎖特性,可解決失效死鎖問題。
缺點:因為需要頻繁的創建和刪除節點,性能上不如Redis方式。
6、總結
上面的三種實現方式,沒有在所有場合都是完美的,所以,應根據不同的應用場景選擇最適合的實現方式。
在分布式環境中,對資源進行上鎖有時候是很重要的,比如搶購某一資源,這時候使用分布式鎖就可以很好地控制資源。
當然,在具體使用中,還需要考慮很多因素,比如超時時間的選取,獲取鎖時間的選取對并發量都有很大的影響,上述實現的分布式鎖也只是一種簡單的實現,主要是一種思想,以上包括文中的代碼可能并不適用于正式的生產環境,只做入門參考!
1、https://yq.aliyun.com/articles/60663
2、http://www.hollischuang.com/archives/1716
3、https://www.cnblogs.com/liuyang0/p/6744076.html
感謝各位的閱讀,以上就是“java分布式鎖的原理以及實現方法”的內容了,經過本文的學習后,相信大家對java分布式鎖的原理以及實現方法這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。