溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Spark-S3-SparkSQL的架構和原理是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Spark-S3-SparkSQL的架構和原理是什么”吧!
HDFS -> HIVE
由于Hadoop在企業生產中的大量使用,HDFS上積累了大量數據,為了給熟悉RDBMS但又不理解MapReduce的技術人員提供快速上手的工具,Hive應運而生。Hive的原理是將SQL語句翻譯成MapReduce計算。
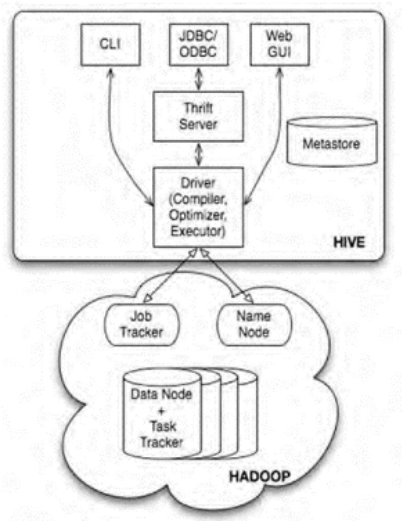
HIVE -> SHARK
MapReduce計算過程中大量的中間磁盤落地過程消耗了大量的I/O,降低了運行效率,為了提供SQL-on-Hadoop的效率,Shark出現了。
Shark是伯克利AMPLab實驗室Spark生態環境的組件之一,它修改了Hive中的內存管理、物理計劃和執行三個模塊,使得SQL語句直接運行在Spark上,從而使得SQL查詢的速度得到10-100倍的提升。
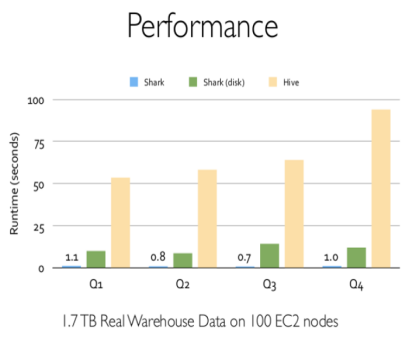
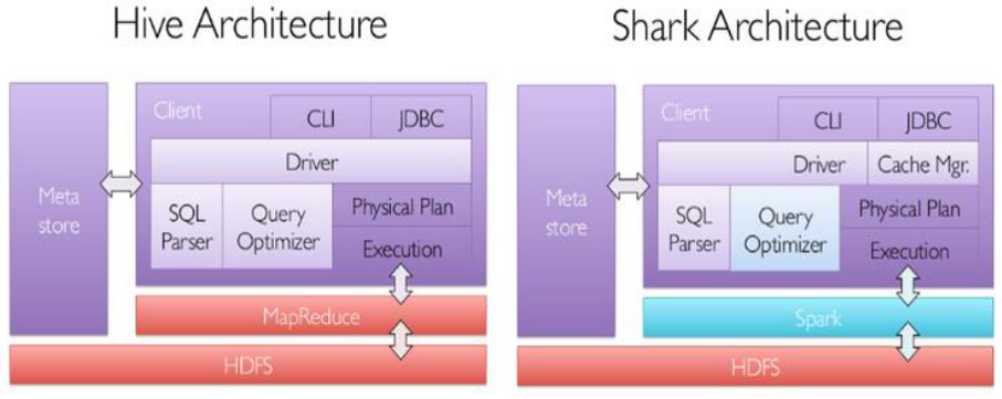
SHARK -> SPARK SQL
2014年6月1日,Shark項目和SparkSQL項目的主持人Reynold Xin宣布:停止對Shark的開發,團隊將所有資源放sparkSQL項目上,至此,Shark的發展畫上了句號。
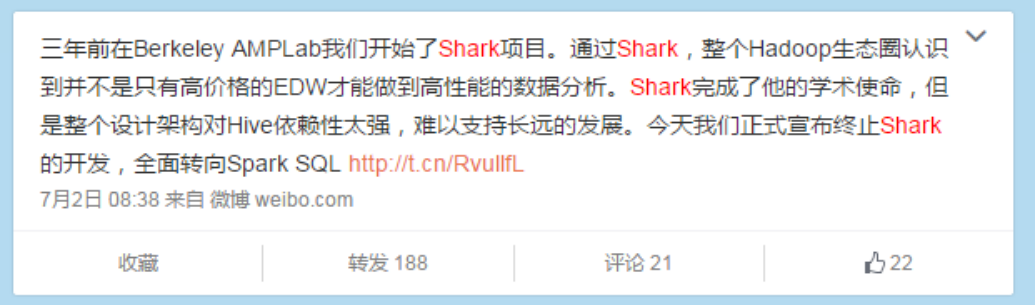
隨著Spark的發展,Shark對于Hive的太多依賴制約了Spark的One Stack rule them all的方針,制約了Spark各個組件的相互集成,同時Shark也無法利用Spark的特性進行深度優化,所以決定放棄Shark,提出了SparkSQL項目。
隨著Shark的結束,兩個新的項目應運而生:SparkSQL和Hive on Spark。其中SparkSQL作為Spark生態的一員繼續發展,而不再受限于Hive,只是兼容Hive;而Hive on Spark是一個Hive的發展計劃,該計劃將Spark作為Hive的底層引擎之一,也就是說,Hive將不再受限于一個引擎,可以采用Map-Reduce、Tez、Spark等引擎。
SparkSQL優勢
SparkSQL擺脫了對Hive的依賴性,無論在數據兼容、性能優化、組件擴展方面都得到了極大的方便。
1、數據兼容方面
不但兼容Hive,還可以從RDD、parquet文件、JSON文件中獲取數據,未來版本甚至支持獲取RDBMS數據以及cassandra等NOSQL數據;
2、性能優化方面
除了采取In-Memory Columnar Storage、byte-code generation等優化技術外、將會引進Cost Model對查詢進行動態評估、獲取最佳物理計劃等等;
3、組件擴展方面
無論是SQL的語法解析器、分析器還是優化器都可以重新定義,進行擴展;
內存列存儲(In-Memory Columnar Storage)
對于內存列存儲來說,將所有原生數據類型的列采用原生數組來存儲,將Hive支持的復雜數據類型(如array、map等)先序列化后并接成一個字節數組來存儲。
這樣,每個列創建一個JVM對象,從而導致可以快速地GC和緊湊的數據存儲。
額外的,還可以用低廉CPU開銷的高效壓縮方法來降低內存開銷。
更有趣的是,對于分析查詢中頻繁使用的聚合特定列,性能會得到很大的提高,原因就是這些列的數據放在一起,更容易讀入內存進行計算。
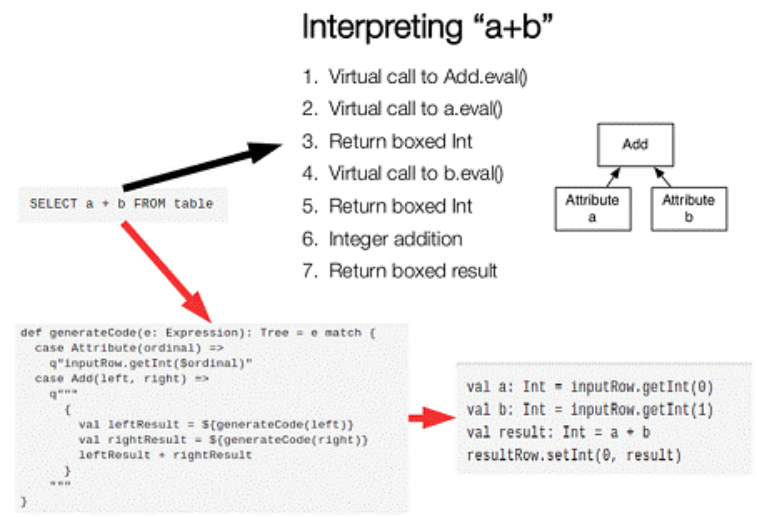
字節碼生成技術(bytecode generation,即CG)
在數據庫查詢中有個昂貴的操作就是查詢語句中的表達式,主要是由JVM的內存模型引起的。如SELECT a+b FROM table,這個查詢里如果采用通用的SQL語法途徑去處理,會先生成一個表達樹,會多次設計虛函數的調用,這會打斷CPU的正常流水線處理,減緩執行速度。
spark -1.1.0在catalyst模塊的expressions增加了codegen模塊,如果使用動態字節碼生成技術,Spark SQL在執行物理計劃時,會對匹配的表達式采用特定的代碼動態編譯,然后運行。
Scala代碼的優化
Spark SQL在使用Scala語言編寫代碼時,應盡量避免容易GC的低效代碼。盡管增加了編寫代碼的難度,但對于用戶來說,還是使用了統一的接口,讓開發在使用上更加容易。

SparkSQL有兩個分支,sqlContext和hiveContext,sqlContext現在只支持SQL語法解析器;hiveContext現在支持SQL語法解析器和hivesql語法解析器,默認為hiveSQL語法解析器,用戶可以通過配置切換成SQL語法解析器,來運行hiveSQL不支持的語法。

Spark SQL由Core、Catalyst、Hive、Hive-ThriftServer四部分構成:
1.Core: 負責處理數據的輸入和輸出,如獲取數據,查詢結果輸出成DataFrame等
2.Catalyst: 負責處理整個查詢過程,包括解析、綁定、優化等
3.Hive: 負責對Hive數據進行處理
4.Hive-ThriftServer: 主要用于對hive的訪問
SparkSQL有兩個分支,sqlContext和hiveContext,sqlContext現在只支持SQL語法解析器;hiveContext現在支持SQL語法解析器和hivesql語法解析器,默認為hiveSQL語法解析器,用戶可以通過配置切換成SQL語法解析器,來運行hiveSQL不支持的語法。
Spark SQL語句的執行順序
1.對讀入的SQL語句進行解析(Parse),分辨出SQL語句中哪些詞是關鍵詞(如SELECT、FROM、WHERE),哪些是表達式、哪些是Projection、哪些是Data Source等,從而判斷SQL語句是否規范;
2.將SQL語句和數據庫的數據字典(列、表、視圖等等)進行綁定(Bind),如果相關的Projection、Data Source等都是存在的話,就表示這個SQL語句是可以執行的;
3.一般的數據庫會提供幾個執行計劃,這些計劃一般都有運行統計數據,數據庫會在這些計劃中選擇一個最優計劃(Optimize);
4.計劃執行(Execute),按Operation-->Data Source-->Result的次序來進行的,在執行過程有時候甚至不需要讀取物理表就可以返回結果,比如重新運行剛運
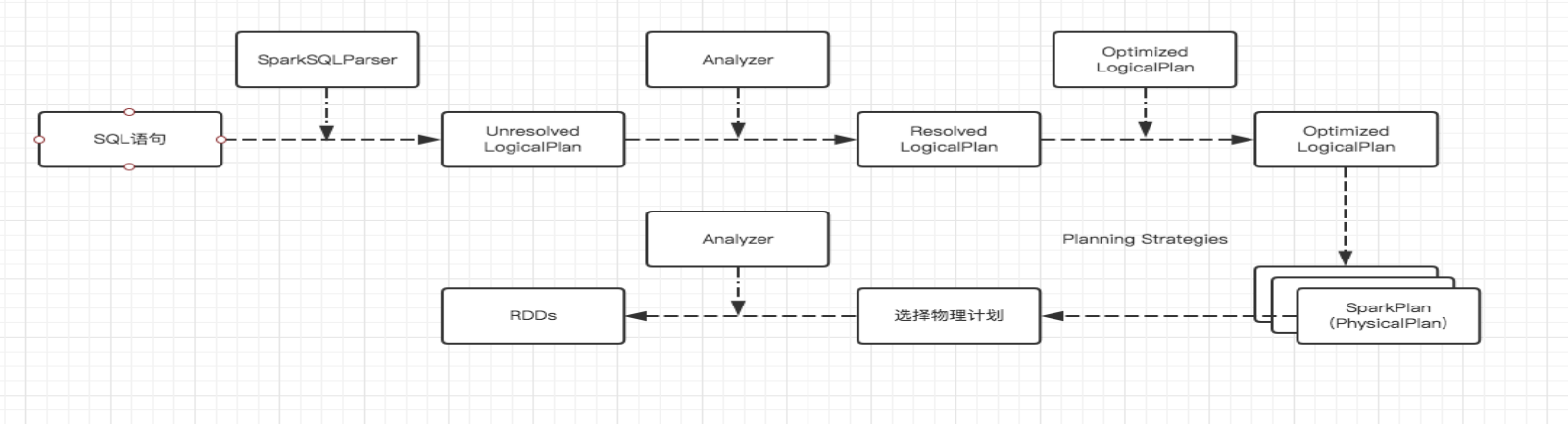
1,使用SessionCatalog保存元數據
在解析SQL語句之前,會創建SparkSession,或者如果是2.0之前的版本初始化SQLContext,SparkSession只是封裝了SparkContext和SQLContext的創建而已。會把元數據保存在SessionCatalog中,涉及到表名,字段名稱和字段類型。創建臨時表或者視圖,其實就會往SessionCatalog注冊。
2,解析SQL使用ANTLR生成未綁定的邏輯計劃
當調用SparkSession的SQL或者SQLContext的SQL方法,我們以2.0為準,就會使用SparkSqlParser進行解析SQL。使用的ANTLR進行詞法解析和語法解析。它分為2個步驟來生成Unresolved LogicalPlan:
詞法分析:Lexical Analysis, 負責將token分組成符號類。
構建一個分析樹或者語法樹AST。
3,使用分析器Analyzer綁定邏輯計劃
在該階段,Analyzer會使用Analyzer Rules,并結合SessionCatalog,對未綁定的邏輯計劃進行解析,生成已綁定的邏輯計劃。
4,使用優化器Optimizer優化邏輯計劃
優化器也是會定義一套Rules,利用這些Rule對邏輯計劃和Exepression進行迭代處理,從而使得樹的節點進行合并和優化。
5,使用SparkPlanner生成物理計劃
SparkSpanner使用Planning Strategies,對優化后的邏輯計劃進行轉換,生成可以執行的物理計劃SparkPlan.
6,使用QueryExecution執行物理計劃
此時調用SparkPlan的execute方法,底層其實已經再觸發JOB了,然后返回RDD。
TreeNode
邏輯計劃、表達式等都可以用tree來表示,它只是在內存中維護,并不會進行磁盤的持久化,分析器和優化器對樹的修改只是替換已有節點。
TreeNode有2個直接子類,QueryPlan和Expression。QueryPlan下又有LogicalPlan和SparkPlan. Expression是表達式體系,不需要執行引擎計算而是可以直接處理或者計算的節點,包括投影操作,操作符運算等
Rule & RuleExecutor
Rule就是指對邏輯計劃要應用的規則,以到達綁定和優化。他的實現類就是RuleExecutor。優化器和分析器都需要繼承RuleExecutor。
每一個子類中都會定義Batch、Once、FixPoint. 其中每一個Batch代表著一套規則,Once表示對樹進行一次操作,FixPoint表示對樹進行多次的迭代操作。
RuleExecutor內部提供一個Seq[Batch]屬性,里面定義的是RuleExecutor的處理邏輯,具體的處理邏輯由具體的Rule子類實現。
SparkSQL1.1總體上由四個模塊組成:core、catalyst、hive、hive-Thriftserver:
core處理數據的輸入輸出,從不同的數據源獲取數據(RDD、Parquet、json等),將查詢結果輸出成schemaRDD;
catalyst處理查詢語句的整個處理過程,包括解析、綁定、優化、物理計劃等,說其是優化器,還不如說是查詢引擎;
hive對hive數據的處理
hive-ThriftServer提供CLI和JDBC/ODBC接口
在這四個模塊中,catalyst處于最核心的部分,其性能優劣將影響整體的性能。由于發展時間尚短,還有很多不足的地方,但其插件式的設計,為未來的發展留下了很大的空間。
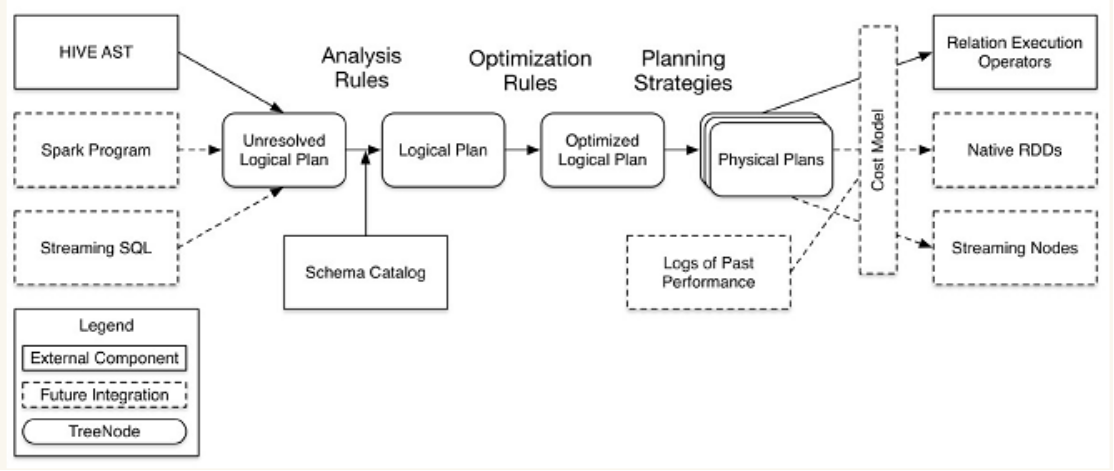
從上圖看,catalyst主要的實現組件有:
1.sqlParse,完成sql語句的語法解析功能,目前只提供了一個簡單的sql解析器;
2.Analyzer,主要完成綁定工作,將不同來源的Unresolved LogicalPlan和數據元數據(如hive metastore、Schema catalog)進行綁定,生成resolved LogicalPlan;
3.optimizer對resolved LogicalPlan進行優化,生成optimized LogicalPlan;
4.Planner將LogicalPlan轉換成PhysicalPlan;、
5.CostModel,主要根據過去的性能統計數據,選擇最佳的物理執行計劃
這些組件的基本實現方法:
1.先將sql語句通過解析生成Tree,然后在不同階段使用不同的Rule應用到Tree上,通過轉換完成各個組件的功能。
2.Analyzer使用Analysis Rules,配合數據元數據(如hive metastore、Schema catalog),完善Unresolved LogicalPlan的屬性而轉換成resolved LogicalPlan;
3.optimizer使用Optimization Rules,對resolved LogicalPlan進行合并、列裁剪、過濾器下推等優化作業而轉換成optimized LogicalPlan;
4.Planner使用Planning Strategies,對optimized LogicalPlan
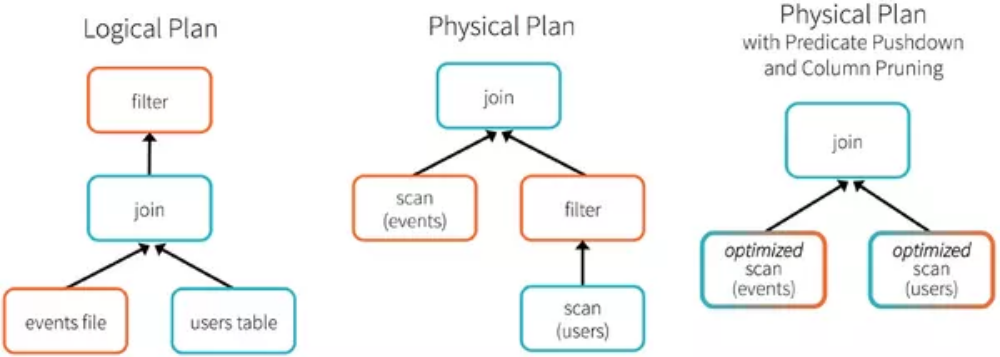
為了說明查詢優化,我們來看下圖展示的人口數據分析的示例。圖中構造了兩個DataFrame,將它們join之后又做了一次filter操作。如果原封不動地執行這個執行計劃,最終的執行效率是不高的。因為join是一個代價較大的操作,也可能會產生一個較大的數據集。如果我們能將filter下推到 join下方,先對DataFrame進行過濾,再join過濾后的較小的結果集,便可以有效縮短執行時間。而Spark SQL的查詢優化器正是這樣做的。簡而言之,邏輯查詢計劃優化就是一個利用基于關系代數的等價變換,將高成本的操作替換為低成本操作的過程。
得到的優化執行計劃在轉換成物 理執行計劃的過程中,還可以根據具體的數據源的特性將過濾條件下推至數據源內。最右側的物理執行計劃中Filter之所以消失不見,就是因為溶入了用于執行最終的讀取操作的表掃描節點內。
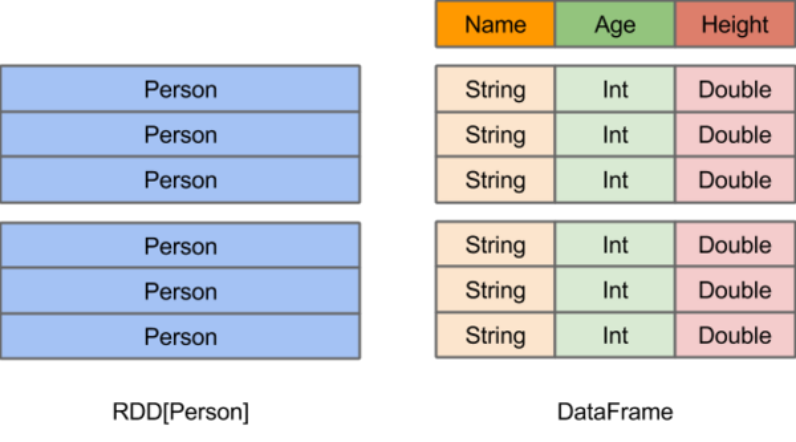
在Spark中,DataFrame是一種以RDD為基礎的分布式數據集,類似于傳統數據庫中的二維表格。DataFrame與RDD的主要區別在于,前者帶有schema元信息,即DataFrame所表示的二維表數據集的每一列都帶有名稱和類型。這使得Spark SQL得以洞察更多的結構信息,從而對藏于DataFrame背后的數據源以及作用于DataFrame之上的變換進行了針對性的優化,最終達到大幅提升運行時效率的目標。反觀RDD,由于無從得知所存數據元素的具體內部結構,Spark Core只能在stage層面進行簡單、通用的流水線優化。
DataFrame的特性
能夠將單個節點集群上的大小為Kilobytes到Petabytes的數據處理為大型集群。
支持不同的數據格式(Avro,csv,彈性搜索和Cassandra)和存儲系統(HDFS,HIVE表,mysql等)。
通過Spark SQL Catalyst優化器(樹變換框架)的最先進的優化和代碼生成。
可以通過Spark-Core輕松地與所有大數據工具和框架集成。
提供用于Python,Java,Scala和R編程的API。
創建DataFrame
在Spark SQL中,開發者可以非常便捷地將各種內、外部的單機、分布式數據轉換為DataFrame。
# 從Hive中的users表構造
DataFrame users = sqlContext.table("users")
# 加載S3上的JSON文件
logs = sqlContext.load("s3n://path/to/data.json", "json")
# 加載HDFS上的Parquet文件
clicks = sqlContext.load("hdfs://path/to/data.parquet", "parquet")
# 通過JDBC訪問MySQL comments = sqlContext.jdbc("jdbc:mysql://localhost/comments", "user")
# 將普通RDD轉變為
DataFrame rdd = sparkContext.textFile("article.txt") \
.flatMap(lambda line: line.split()) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b) \
wordCounts = sqlContext.createDataFrame(rdd, ["word", "count"])# 將本地數據容器轉變為
DataFrame data = [("Alice", 21), ("Bob", 24)]
people = sqlContext.createDataFrame(data, ["name", "age"])使用DataFrame
和R、Pandas類似,Spark DataFrame也提供了一整套用于操縱數據的DSL。這些DSL在語義上與SQL關系查詢非常相近(這也是Spark SQL能夠為DataFrame提供無縫支持的重要原因之一) 。
# 創建一個只包含"年輕"用戶的DataFrame
df = users.filter(users.age < 21)
# 也可以使用Pandas風格的語法
df = users[users.age < 21]
# 將所有人的年齡加1
df.select(young.name, young.age + 1)
# 統計年輕用戶中各性別人數
df.groupBy("gender").count()
# 將所有年輕用戶與另一個名為logs的DataFrame聯接起來
df.join(logs, logs.userId == users.userId, "left_outer")
保存DataFrame
當數據分析邏輯編寫完畢后,我們便可以將最終結果保存下來或展現出來。
# 追加至HDFS上的Parquet文件
df.save(path="hdfs://path/to/data.parquet", source="parquet", mode="append")
# 覆寫S3上的JSON文件
df.save(path="s3n://path/to/data.json", source="json", mode="append")
# 保存為SQL表
df.saveAsTable(tableName="young", source="parquet" mode="overwrite")
# 轉換為Pandas DataFrame(Python API特有功能)
pandasDF = young.toPandas()
# 以表格形式打印輸出
df.show()
到此,相信大家對“Spark-S3-SparkSQL的架構和原理是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





