溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
移動互聯網時代,“大數據”是關鍵詞之一。作為推送技術服務行業的先行者,個推不斷進行技術革新引領推送革命。通過挖掘用戶使用場景,結合地理位置信息精確命中不同用戶的各類需求。在服務大客戶的過程中通過自身平臺積累的海量數據發展了大數據。
目前,3.0產品最重要的技術——電子圍欄技術:電子圍欄是精確捕捉用戶場景,實時給用戶推送有價值消息的手機推送解決方案。客戶根據業務需求,在地圖上設置電子圍欄區域和目標用戶屬性,通過冷數據畫像(結合大數據分析,篩選目標用戶)以及熱數據投放(當目標用戶進入電子圍欄實時觸發),做到在合適的時間、合適的地點、合適的場景、把合適的內容、推送給合適的人。
構建基于LBS的大數據應用,一般的實現流程為:通過信息收集后進行基礎數據的整理,數據挖掘/機器學習,服務搭建以及數據可視化等。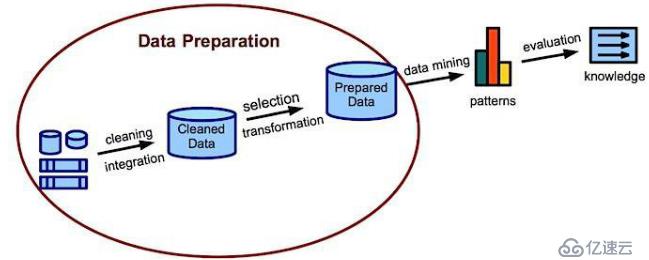
數據挖掘的基本流程
基礎數據的處理主要包括:數據集成和一些部分數據處理。
數據集成,數據挖掘或統計分析可能用到來自不同數據源的數據,我們需要將這些數據集成在一起。但如果只有一個數據源,這一步可以省略。
基礎數據處理,有些數據是缺失的(數據屬性的值是空值),有些數據是含噪聲的(屬性的值是錯誤的,或有孤立點數據),有時同樣的信息采用了多種不同的表示方式(在編碼或命名上存在不一致),基于種種問題要對數據進行基礎的處理。通過基礎數據處理,可以確保村人數據倉庫中的信息是完整、正確和格式一致的。
數據轉換主要是利用現有的字段進行運算來得到新的字段,通常說到數據變換主要包括四種:數據離散化(采用分箱等方式)、產生衍生變量、使變量分布更接近正態分布、數據標準化。如果對連續變量進行離散化,可以避免引入任何分布假設。這樣就不需要符合正態分布了。
數據挖掘時只根據數據庫中的數據,用合適的數據挖掘算法進行分析,得出有用的信息。其中,模型算法質量的評價是很重要的一步。且數據挖掘是一個循環往復的過程。
基于LBS的大數據應用需要解決很多問題:基礎數據問題比如海量數據流(>20W 條/s)、數據處理性能復雜計算(定位和統計)、準確率、秒級實時性要求、以及數據的實時性等。對此,個推的解決方案是:分布式流式計算框架、Spark Streaming、發布/訂閱模型、Apache Kafka、Events等。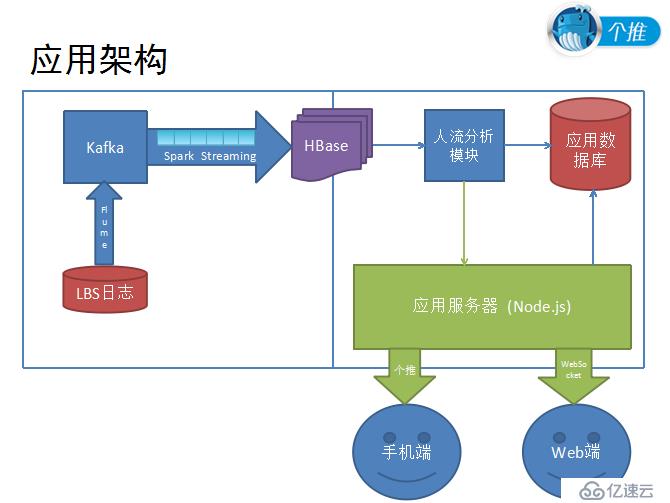
最后,基于大數據的LBS應用,可以使用分布式流式計算框架,構建數據閉環,從而實現持續優化基礎數據。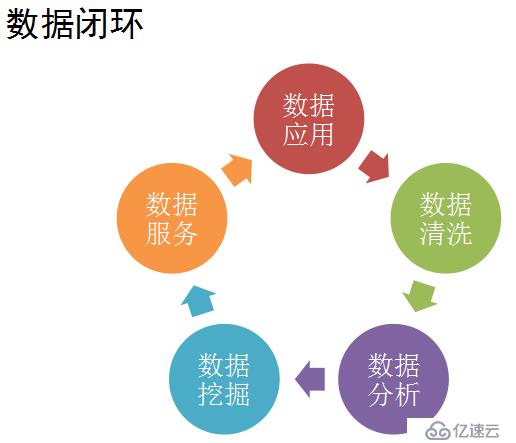
目前的成功案例有:
1.杭州白馬湖動漫節的安全保障。本通過海量的樣本數據采集和分析,以實時人流熱力分析圖為主要服務接口,監控動漫節期間杭州濱江區白馬湖動漫廣場附近的人流去向和擁擠程度。這一項部署建立了白馬湖區塊的實時監控和人流預警系統,在人流量超過一定數量的時候實時發布預警,從而及時提醒相關人員注意對應區域的高峰人流量疏散和引導,從源頭上防范踩踏事件及避免安全隱患的發生。
2.發生地震時實時警報,并通過大數據對人群熱力圖的分析,為震后救援工作定制合理方案及提供有效幫助。
3.與旅游局合作,將旅游分析熱點圖與實時推送相結合,用于疏散和引導景區高峰人流量,避免危險事件發生。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





