溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Slor的基本概念和倒排索引介紹”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Slor的基本概念和倒排索引介紹”吧!
Solr它是一種開放源碼的、基于 Lucene Java 的搜索服務器,易于加入到 Web 應用程序中。
Solr 提供了層面搜索(就是統計)、命中醒目顯示并且支持多種輸出格式(包括XML/XSLT 和JSON等格式)。它易于安裝和配置,而且附帶了一個基于 HTTP 的管理界面。Solr已經在眾多大型的網站中使用,較為成熟和穩定。
Solr 包裝并擴展了 Lucene,所以Solr的基本上沿用了Lucene的相關術語。更重要的是,Solr 創建的索引與 Lucene 搜索引擎庫完全兼容。
通過對Solr 進行適當的配置,某些情況下可能需要進行編碼,Solr 可以閱讀和使用構建到其他 Lucene 應用程序中的索引。
此外,很多 Lucene 工具(如Nutch、 Luke)也可以使用Solr 創建的索引。可以使用 Solr 的表現優異的基本搜索功能,也可以對它進行擴展從而滿足企業的需要。
高級的全文搜索功能;
專為高通量的網絡流量進行的優化;
基于開放接口(XML和HTTP)的標準;
綜合的HTML管理界面;
可伸縮性-能夠有效地復制到另外一個Solr搜索服務器;
使用XML配置達到靈活性和適配性;
可擴展的插件體系。
Lucene中的基本概念是:index(索引),document(文檔),field(字段)和term(術語)
一個索引文件(index)包含一連串的文檔(document);
一個文檔(document)是由一連串字段(fields),類似于數據庫中的一條記錄;
一個字段(field)由一連串的術語(terms)組成;
一個術語(term)是一個字符串
ps:相同的字符串在不同的fields被認為是不同的term
index存儲terms的統計數據,為了使得基于term的檢索效率更高。相對于oracle中索引(B-TREE)結構,solr搜索引擎中采用的是一種倒排索引。 倒排索引(Inverted Index):倒排索引是實現“單詞-文檔矩陣”的一種具體存儲形式,通過倒排索引,可以根據單詞快速獲取包含這個單詞的文檔列表。倒排索引主要由兩個部分組成:“單詞詞典”和“倒排文件”。 文檔(Document):一般搜索引擎的處理對象是互聯網網頁,而文檔這個概念要更寬泛些,代表以文本形式存在的存儲對象,相比網頁來說,涵蓋更多種形式,比如Word,PDF,html,XML等不同格式的文件都可以稱之為文檔。再比如一封郵件,一條短信,一條微博也可以稱之為文檔。在本書后續內容,很多情況下會使用文檔來表征文本信息。
中文和英文等語言不同,單詞之間沒有明確分隔符號,所以首先要用分詞系統將文檔自動切分成單詞序列。這樣每個文檔就轉換為由單詞序列構成的數據流,為了系統后續處理方便,需要對每個不同的單詞賦予唯一的單詞編號,同時記錄下哪些文檔包含這個單詞,在如此處理結束后,我們可以得到最簡單的倒排索引。在圖中,“單詞ID”一欄記錄了每個單詞的單詞編號,第二欄是對應的單詞,第三欄即每個單詞對應的倒排列表。比如單詞“谷歌”,其單詞編號為1,倒排列表為{1,2,3,4,5},說明文檔集合中每個文檔都包含了這個單詞。
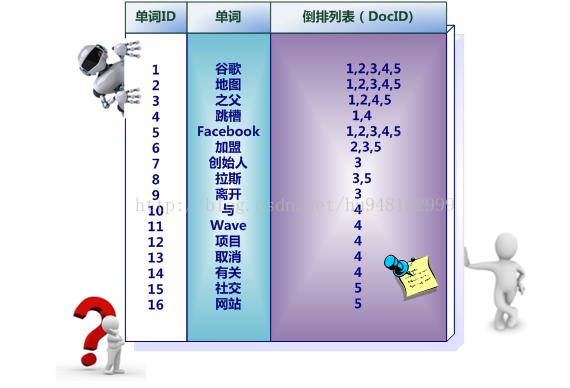
之所以說上圖所示倒排索引是最簡單的,是因為這個索引系統只記載了哪些文檔包含某個單詞,而事實上,索引系統還可以記錄除此之外的更多信息。下面這張圖是一個相對復雜些的倒排索引,與上圖的基本索引系統比,在單詞對應的倒排列表中不僅記錄了文檔編號,還記載了單詞頻率信息(TF),即這個單詞在某個文檔中的出現次數。下圖中,詞“創始人”的單詞編號為7,對應的倒排列表內容為:(3:1),其中的3代表文檔編號為3的文檔包含這個單詞,數字1代表詞頻信息,即這個單詞在3號文檔中只出現過1次,其它單詞對應的倒排列表所代表含義與此相同。 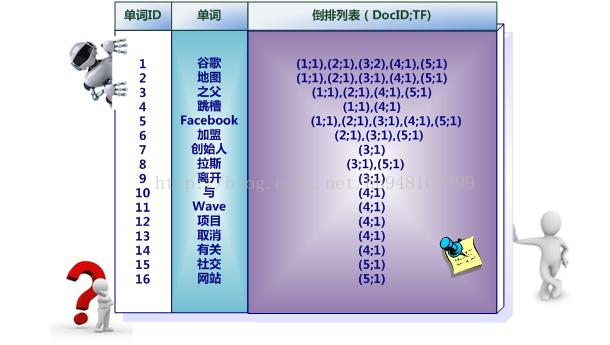
實用的倒排索引還可以記載更多的信息,索引系統除了記錄文檔編號和單詞頻率信息外,額外記載了兩類信息,即每個單詞對應的“文檔頻率信息”以及在倒排列表中記錄單詞在某個文檔出現的位置信息。 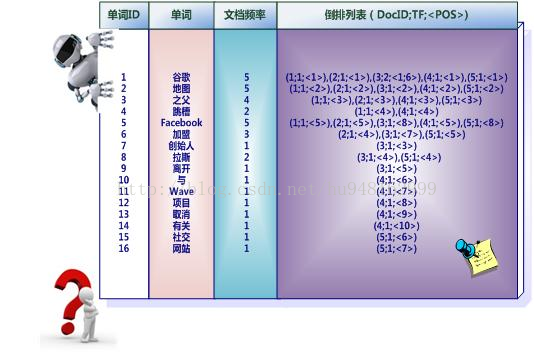
“文檔頻率信息”代表了在文檔集合中有多少個文檔包含某個單詞
以單詞“拉斯”為例,其單詞編號為8,文檔頻率為2,代表整個文檔集合中有兩個文檔包含這個單詞,對應的倒排列表為:{(3;1;<4>),(5;1;<4>)},其含義為在文檔3和文檔5出現過這個單詞,單詞頻率都為1,單詞“拉斯”在兩個文檔中的出現位置都是4,即文檔中第四個單詞是“拉斯”。
收集待索引的原文檔
從數據庫、web等獲取原文檔
將原文檔交給分詞組件(Tokenizer)
此過程叫做Tokenize,得到的結果稱為Token。 會做如下幾件事: a.將文檔分成一個個獨立的單詞 b.去除標點 b.去除停詞(stopword)
將得到的Token交給語言處理組件(LinguisticProcessor)
此過程處理的結果是Term 會做如下幾件事: a.轉為小寫 b.將單詞縮減為詞根,如cars-->car c.將單詞轉變為詞根,如drove-->drive
將得到的Term交給索引組件(Indexer)
會做如下幾件事: a.將得到的Term創建字典 b.對字典按字母排序 c.合并相同的Term為倒排索引表
感謝各位的閱讀,以上就是“Slor的基本概念和倒排索引介紹”的內容了,經過本文的學習后,相信大家對Slor的基本概念和倒排索引介紹這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





