溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“ELK日志系統的架構是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
日志數據處理
這么多的日志,運維要通過各種手段完成日志的收集、過濾分析、可視化展示,那么如何實現這些功能呢?
方法很多,例如ELK集成套件(Elasticsearch , Logstash, Kibana)就可以輕松實現日志數據的實時收集、分析傳輸以及圖形化展示。
那么要如何使用ELK呢,根據日志量的不同,對應的ELK架構也不盡相同,看下面幾個常見架構:
ELK架構1
此架構主要是將Logstash部署在各個節點上搜集相關日志、數據,并經過分析、過濾后發送給遠端服務器上的Elasticsearch進行存儲。
Elasticsearch再將數據以分片的形式壓縮存儲,并提供多種API供用戶查詢、操作。用戶可以通過Kibana Web直觀的對日志進行查詢,并根據需求生成數據報表。
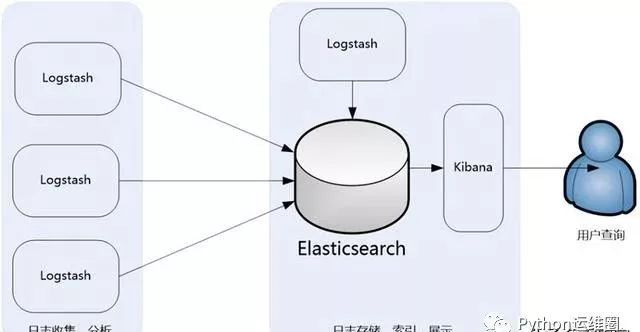
此架構的優點是搭建簡單,易于上手。缺點是Logstash消耗系統資源比較大,運行時占用CPU和內存資源較高。
另外,由于沒有消息隊列緩存,可能存在數據丟失的風險。此架構建議供初學者或數據量小的環境使用。
ELK架構2
由此衍生出來了第二種架構:
此架構主要特點是引入了消息隊列機制,位于各個節點上的Logstash Agent(一級Logstash,主要用來傳輸數據)先將數據傳遞給消息隊列(常見的有Kafka、Redis等)。
接著,Logstash server(二級Logstash,主要用來拉取消息隊列數據,過濾并分析數據)將格式化的數據傳遞給Elasticsearch進行存儲。
最后,由Kibana將日志和數據呈現給用戶。由于引入了Kafka(或者Redis)緩存機制,即使遠端Logstash server因故障停止運行,數據也不會丟失,因為數據已經被存儲下來了。
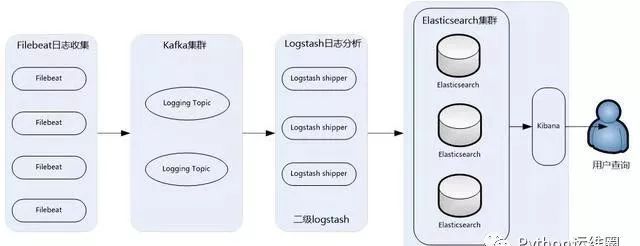
此架構適合大型集群、海量數據的業務場景,它通過將前端Logstash Agent替換成filebeat,有效降低了收集日志對業務系統資源的消耗。
同時,消息隊列使用kafka集群架構,有效保障了收集數據的安全性和穩定性,而后端Logstash和Elasticsearch均采用集群模式搭建,從整體上提高了ELK系統的高效性、擴展性和吞吐量。
用大數據思維做運維監控
大數據分析最早就來源于運維人的日志分析,到逐漸發展對各種業務的分析,人們發現這些數據蘊涵著非常大的價值。
那么如何用大數據思維做運維呢,大數據架構上的一個思維就是:提供一個平臺讓運維方便解決這些問題, 而不是,讓大數據平臺去解決出現的問題。
基本的一個大數據運維架構是這樣的:
對于運維的監控,利用大數據思維,需要分三步走:
獲取需要的數據過濾出異常數據并設置告警閥值通過第三方監控平臺進行告警
所有系統最可靠的就是日志輸出,系統是不是正常,發生了什么情況,我們以前是出了問題去查日志,或者自己寫個腳本定時去分析。現在這些事情都可以整合到一個已有的平臺上,我們唯一要做的就是定義分析日志的的邏輯。
“ELK日志系統的架構是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





