溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關RocketMQ消費模式是什么,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
RocketMQ提供兩種消費策略CLUSTERING集群消費(默認)和BROADCASTING廣播消費,在創建Consumer消費者時可以指定消費策略,策略不同其內部機制也不同,消息的消費方式、記錄消費進度、消息的消費狀態等也都各不相同。下面我們具體來探討一下。
集群模式:一個ConsumerGroup中的Consumer實例根據隊列分配策略算法為Consumer分配隊列,平均分攤(默認)消費消息。例如Topic是Test的消息發送到該主題的不同隊列中,發送了有100條消息,其中一個ConsumerGroup有3個Consumer實例,那么根據隊列分配算法,每個隊列都會有消費者,每個消費者實例只消費自己隊列上的數據,消費完的消息不能被其他消費實例消費。
一個消費隊列會分配一個消費者,有且只有一個
一個消費者可能消費0到多個隊列,例如:某個主題有4個消費隊列,然而消費者有5個那么根據第一條原則,一個消費隊列只能有一個消費者,就會有消費者沒有分配到隊列。
創建兩個集群消費者Consumer1、Consumer2,下面寫出了Consumer1的代碼,Consumer2也是一樣的不再重復了。
public class Consumer1 {
public static void main(String[] args){
try {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer();
consumer.setConsumerGroup("consumer_test_clustering");
consumer.setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
consumer.subscribe("TopicTest", "*");
consumer.registerMessageListener(new MessageListenerConcurrently(){
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> paramList,
ConsumeConcurrentlyContext paramConsumeConcurrentlyContext) {
try {
for(MessageExt msg : paramList){
String msgbody = new String(msg.getBody(), "utf-8");
System.out.println("Consumer1=== MessageBody: "+ msgbody);//輸出消息內容
}
} catch (Exception e) {
e.printStackTrace();
return ConsumeConcurrentlyStatus.RECONSUME_LATER; //稍后再試
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //消費成功
}
});
consumer.start();
System.out.println("Consumer1===啟動成功!");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}我們發現這里面并沒有明顯的說是集群消費,怎么能判斷是集群消費呢,我們查看下源碼分析下。

我們發現DefaultMQPushConsumer consumer = new DefaultMQPushConsumer();創建消費者的時候已經默認了很多內置參數,其中就有消費模式CLUSTERING集群消費。
我們先啟動Consumer1和Consumer2,發送10條消息看一下消費情況,RocketMQ消息是基于訂閱發布模型的。
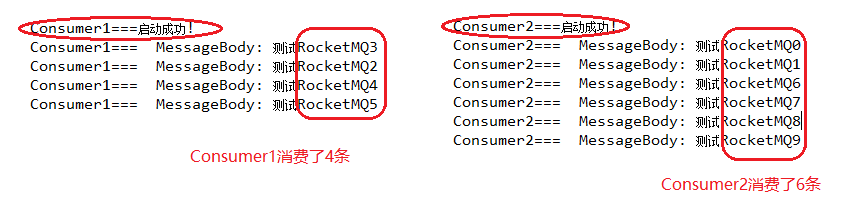
我們發現10條消息都消費了,沒有重復的。集群消息每條消息都是集群內的消費者共同消費且不會重復消費。
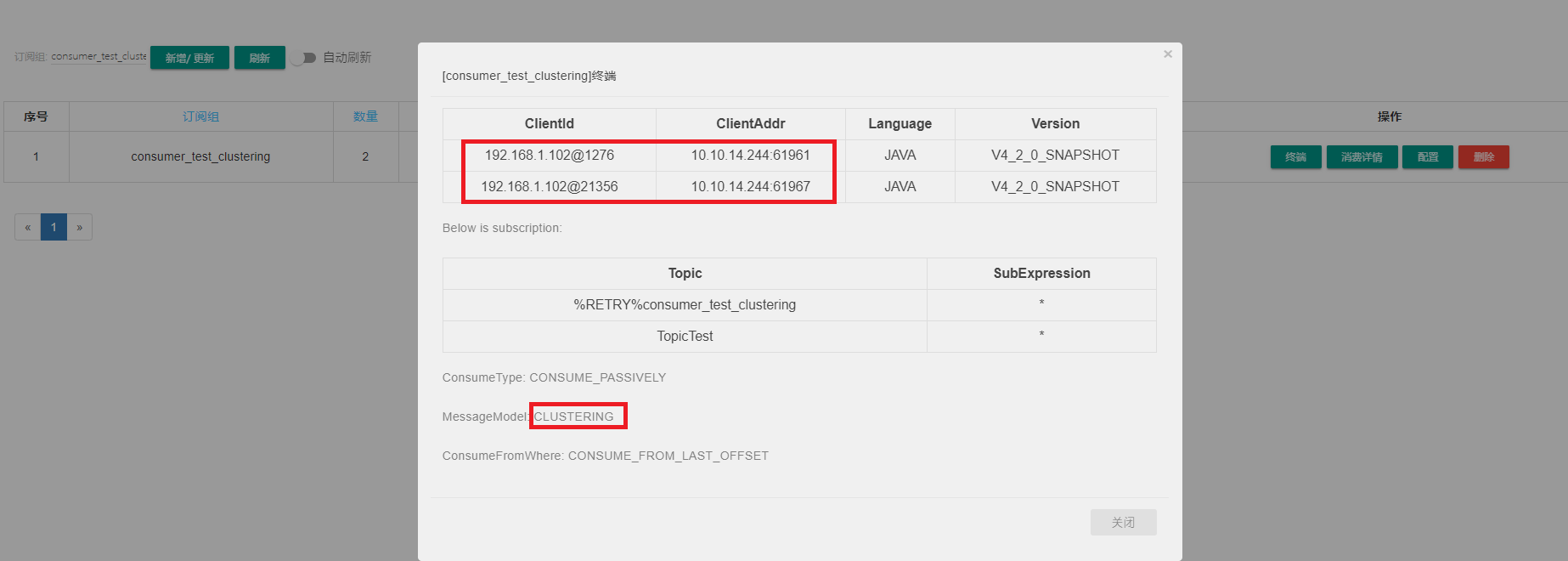
可視化界面查看其客戶端信息
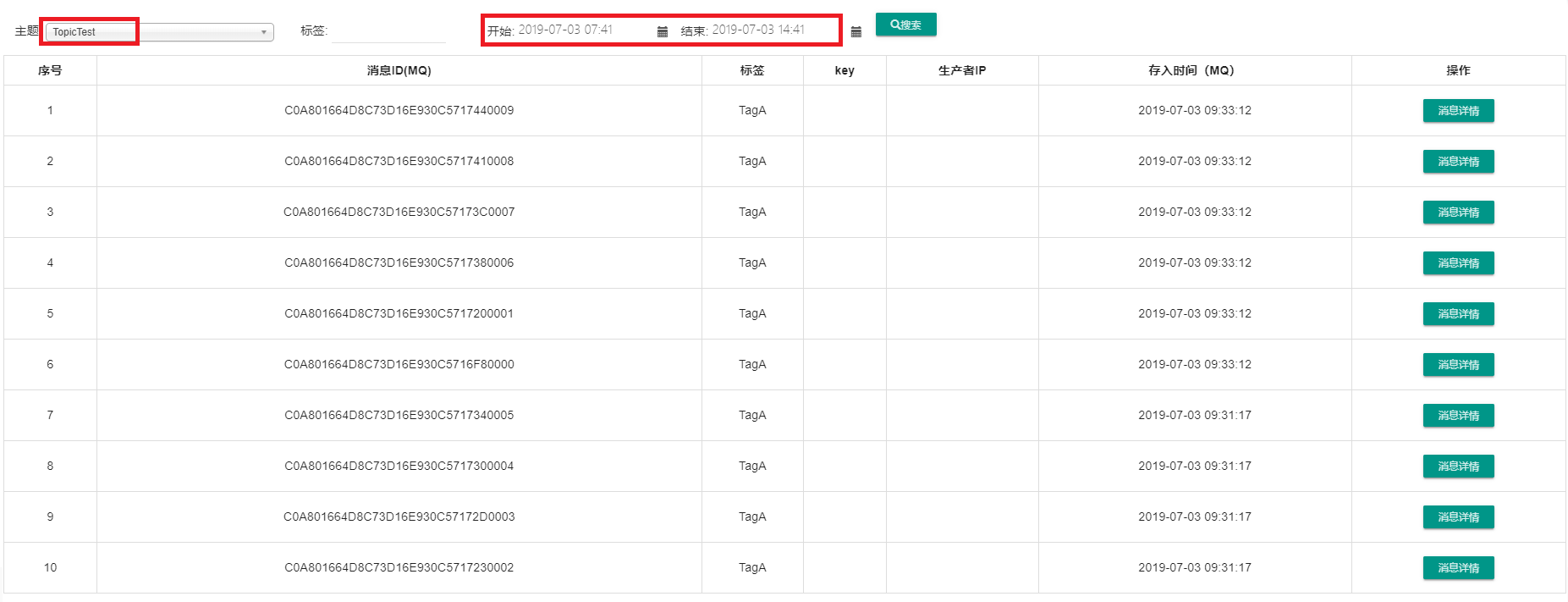
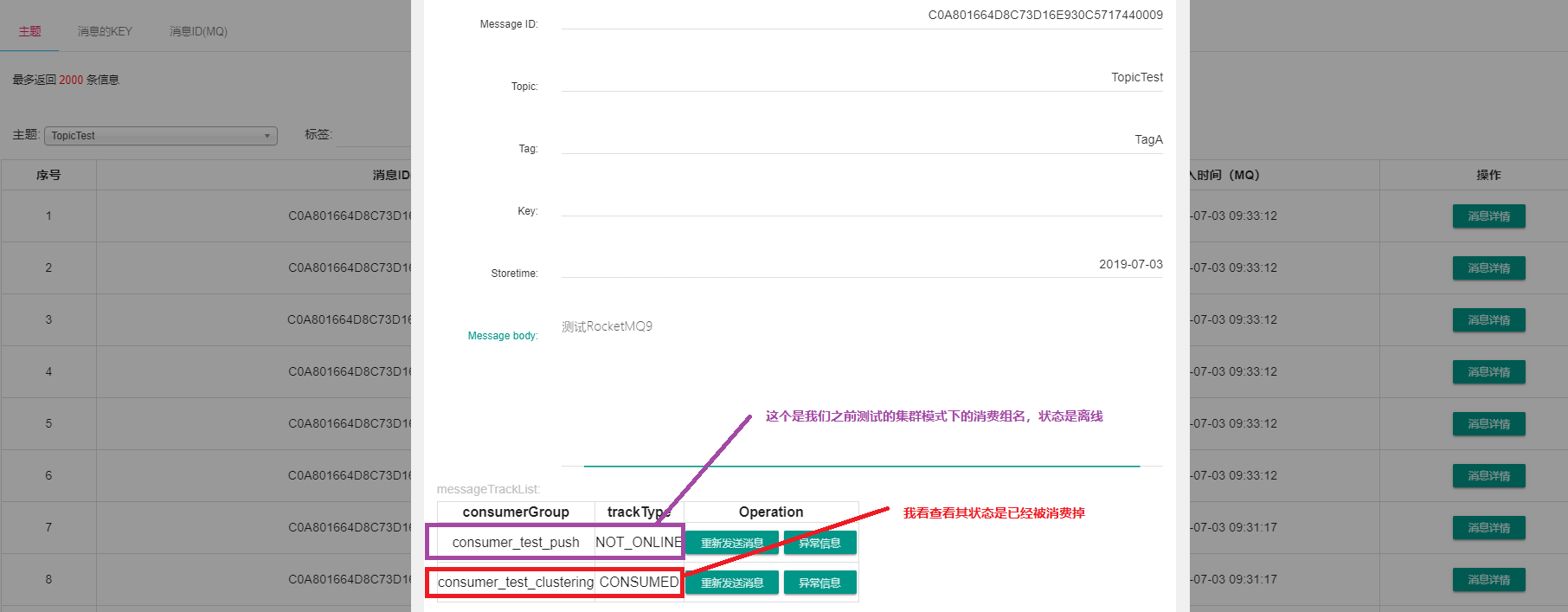
查看其消息情況發了10條消息,我們查看其狀態。
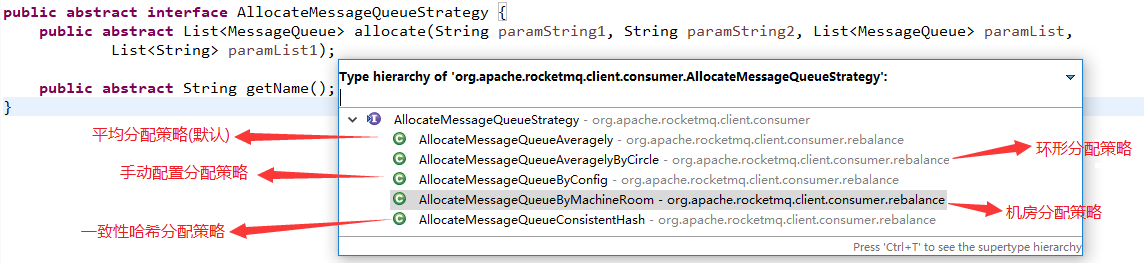
我們首先查看其原理圖
分析其源碼AllocateMessageQueueAveragely類的核心方法是allocate
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
//校驗當前消費者id是否存在的校驗
if ((currentCID == null) || (currentCID.length() < 1)) {
throw new IllegalArgumentException("currentCID is empty");
}
//校驗消息隊列是否存在
if ((mqAll == null) || (mqAll.isEmpty())) {
throw new IllegalArgumentException("mqAll is null or mqAll empty");
}
//校驗所有的消費者id的集合是否為null
if ((cidAll == null) || (cidAll.isEmpty())) {
throw new IllegalArgumentException("cidAll is null or cidAll empty");
}
List result = new ArrayList();
//校驗當前的消費者id是否在消費者id的集群中
if (!(cidAll.contains(currentCID))) {
this.log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
new Object[] { consumerGroup, currentCID, cidAll });
return result;
}
//獲取當前的消費者id在集合中的下標
int index = cidAll.indexOf(currentCID);
int mod = mqAll.size() % cidAll.size();
int averageSize = ((mod > 0) && (index < mod)) ? mqAll.size() / cidAll.size() + 1
: (mqAll.size() <= cidAll.size()) ? 1 : mqAll.size() / cidAll.size();
int startIndex = ((mod > 0) && (index < mod)) ? index * averageSize : index * averageSize + mod;
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; ++i) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
}分析其源碼
26行:消息隊列總數和消費者總數取余
27、28行:計算當前的消費者分配的消息隊列數
(1)取余大于0且當前消費者的下標小于取余數(mod > 0) && (index < mod) -》確定當前的消費者是否在取余里,在則在整除數中+1,mqAll.size() / cidAll.size() + 1
(2)如果已經整除或者不在取余里則判斷消息隊列是否小于等于消費者總數mqAll.size() <= cidAll.size(),在則該消費者分配的消息隊列為1
(3)如果(2)中不成立則,mqAll.size() / cidAll.size()
29、30行:計算當前消費者在消息隊列數組中的開始的下標
(1)取余大于0且當前消費者的下標小于取余數((mod > 0) && (index < mod)) -》當前下標乘以每個隊列的平均隊列數index * averageSize
(2)如果(1)中不成立則index * averageSize + mod
31行:根據Math.min()計算消費者最終需要消費的數量
32行:獲取當前的消費者的隊列集合
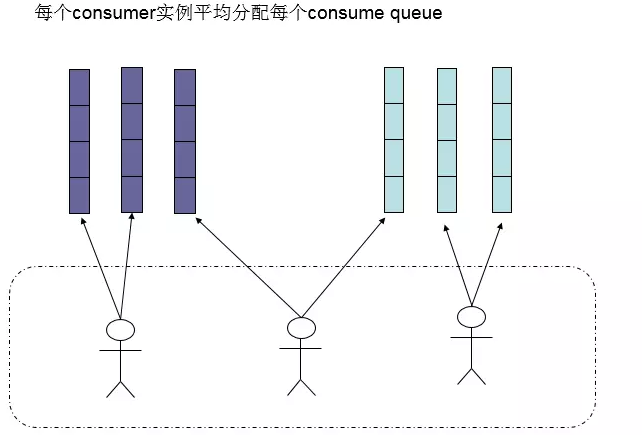
我們首先查看其原理圖
分析其源碼AllocateMessageQueueAveragelyByCircle類的核心方法是allocate
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
if ((currentCID == null) || (currentCID.length() < 1)) {
throw new IllegalArgumentException("currentCID is empty");
}
if ((mqAll == null) || (mqAll.isEmpty())) {
throw new IllegalArgumentException("mqAll is null or mqAll empty");
}
if ((cidAll == null) || (cidAll.isEmpty())) {
throw new IllegalArgumentException("cidAll is null or cidAll empty");
}
List result = new ArrayList();
if (!(cidAll.contains(currentCID))) {
this.log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
new Object[] { consumerGroup, currentCID, cidAll });
return result;
}
//上面一堆校驗我們之間略過
int index = cidAll.indexOf(currentCID);
for (int i = index; i < mqAll.size(); ++i) {
if (i % cidAll.size() == index) {
result.add(mqAll.get(i));
}
}
return result;
}分析其源碼
23、24、25行:遍歷消息的下標, 對下標取模(mod), 如果與index相等, 則存儲到result集合中
分析其源碼AllocateMessageQueueByConfig類
public class AllocateMessageQueueByConfig implements AllocateMessageQueueStrategy {
private List<MessageQueue> messageQueueList;
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
return this.messageQueueList;
}
public String getName() {
return "CONFIG";
}
public List<MessageQueue> getMessageQueueList() {
return this.messageQueueList;
}
public void setMessageQueueList(List<MessageQueue> messageQueueList) {
this.messageQueueList = messageQueueList;
}
}通過配置來記性消息隊列的分配
分析其源碼AllocateMessageQueueByMachineRoom類的核心方法是allocate
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
List result = new ArrayList();
int currentIndex = cidAll.indexOf(currentCID);
if (currentIndex < 0) {
return result;
}
List premqAll = new ArrayList();
for (MessageQueue mq : mqAll) {
String[] temp = mq.getBrokerName().split("@");
if ((temp.length == 2) && (this.consumeridcs.contains(temp[0]))) {
premqAll.add(mq);
}
}
int mod = premqAll.size() / cidAll.size();
int rem = premqAll.size() % cidAll.size();
int startIndex = mod * currentIndex;
int endIndex = startIndex + mod;
for (int i = startIndex; i < endIndex; ++i) {
result.add(mqAll.get(i));
}
if (rem > currentIndex) {
result.add(premqAll.get(currentIndex + mod * cidAll.size()));
}
return result;
}分析源碼
4-7行, 計算當前消費者在消費者集合中的下標(index), 如果下標 < 0 , 則直接返回
8-14行, 根據brokerName解析出所有有效機房信息(其實是有效mq), 用Set集合去重, 結果存儲在premqAll中
16行, 計算消息整除的平均結果mod
17行, 計算消息是否能夠被平均消費rem,(即消息平均消費后還剩多少消息(remaing))
18行, 計算當前消費者開始消費的下標(startIndex)
19行, 計算當前消費者結束消費的下標(endIndex)
20-26行, 將消息的消費分為兩部分, 第一部分 – (cidAllSize * mod) , 第二部分 – (premqAll - cidAllSize * mod) ; 從第一部分中查詢startIndex ~ endIndex之間所有的消息, 從第二部分中查詢 currentIndex + mod * cidAll.size() , 最后返回查詢的結果result
分析其源碼AllocateMessageQueueByMachineRoom類的核心方法是allocate
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
if ((currentCID == null) || (currentCID.length() < 1)) {
throw new IllegalArgumentException("currentCID is empty");
}
if ((mqAll == null) || (mqAll.isEmpty())) {
throw new IllegalArgumentException("mqAll is null or mqAll empty");
}
if ((cidAll == null) || (cidAll.isEmpty())) {
throw new IllegalArgumentException("cidAll is null or cidAll empty");
}
List result = new ArrayList();
if (!(cidAll.contains(currentCID))) {
this.log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
new Object[] { consumerGroup, currentCID, cidAll });
return result;
}
Collection cidNodes = new ArrayList();
for (String cid : cidAll)
cidNodes.add(new ClientNode(cid));
ConsistentHashRouter router;
ConsistentHashRouter router;
if (this.customHashFunction != null)
router = new ConsistentHashRouter(cidNodes, this.virtualNodeCnt, this.customHashFunction);
else {
router = new ConsistentHashRouter(cidNodes, this.virtualNodeCnt);
}
List results = new ArrayList();
for (MessageQueue mq : mqAll) {
ClientNode clientNode = (ClientNode) router.routeNode(mq.toString());
if ((clientNode != null) && (currentCID.equals(clientNode.getKey()))) {
results.add(mq);
}
}
return results;
}廣播消費:一條消息被多個consumer消費,即使這些consumer屬于同一個ConsumerGroup,消息也會被ConsumerGroup中的每個Consumer都消費一次,廣播消費中ConsumerGroup概念可以認為在消息劃分方面無意義。
創建兩個集群消費者ConsumerGB1、ConsumerGB2,下面寫出了ConsumerGB1的代碼,ConsumerGB2也是一樣的不再重復了。
public class ConsumerGB1 {
public static void main(String[] args){
try {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer();
consumer.setConsumerGroup("consumer_test_broadcasting");
//設置廣播消費
consumer.setMessageModel(MessageModel.BROADCASTING);
consumer.setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
consumer.subscribe("TopicTest", "*");
consumer.registerMessageListener(new MessageListenerConcurrently(){
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> paramList,
ConsumeConcurrentlyContext paramConsumeConcurrentlyContext) {
try {
for(MessageExt msg : paramList){
String msgbody = new String(msg.getBody(), "utf-8");
System.out.println("ConsumerGB1=== MessageBody: "+ msgbody);//輸出消息內容
}
} catch (Exception e) {
e.printStackTrace();
return ConsumeConcurrentlyStatus.RECONSUME_LATER; //稍后再試
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //消費成功
}
});
consumer.start();
System.out.println("ConsumerGB1===啟動成功!");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}**consumer.setMessageModel(MessageModel.BROADCASTING);**設置其為廣播模式
廣播模式下的消息的消費進度存儲在客戶端本地,服務端上不存儲其消費進度
集群模式下的消息的消費進度存儲在服務端
廣播模式消費進度文件夾:C:/Users/gumx/.rocketmq_offsets 文件夾下

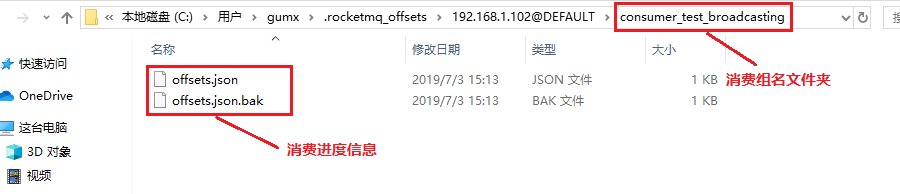
查看消費進度文件
{
"offsetTable":{{
"brokerName":"broker-a",
"queueId":3,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-a",
"queueId":2,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-b",
"queueId":3,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-b",
"queueId":0,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-a",
"queueId":1,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-b",
"queueId":2,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-a",
"queueId":0,
"topic":"TopicTest"
}:13,{
"brokerName":"broker-b",
"queueId":1,
"topic":"TopicTest"
}:13
}
}通過這個我們可以發現主題是TopicTest一共有8個消費隊列,分布在兩個Broker節點上broker-a、broker-b,隊列的ID從0~3分別是4個,每個隊列現在消息的偏移量不同,兩個13六個14。
通過界面客戶端查看其消費者信息
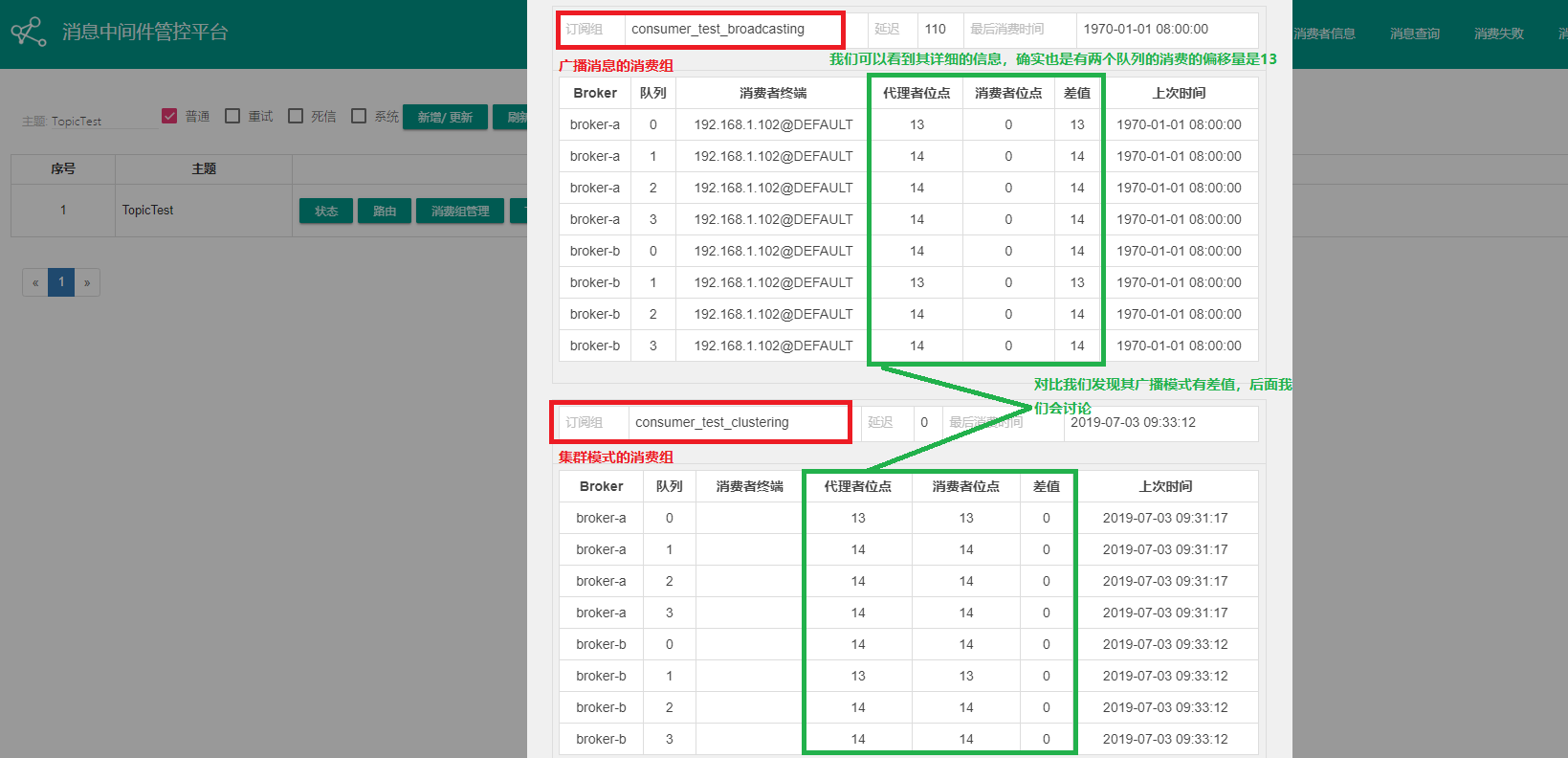
發送10條消息

我們發現兩個消費組都消費了10條消息
再次通過界面客戶端查看其消費者信息
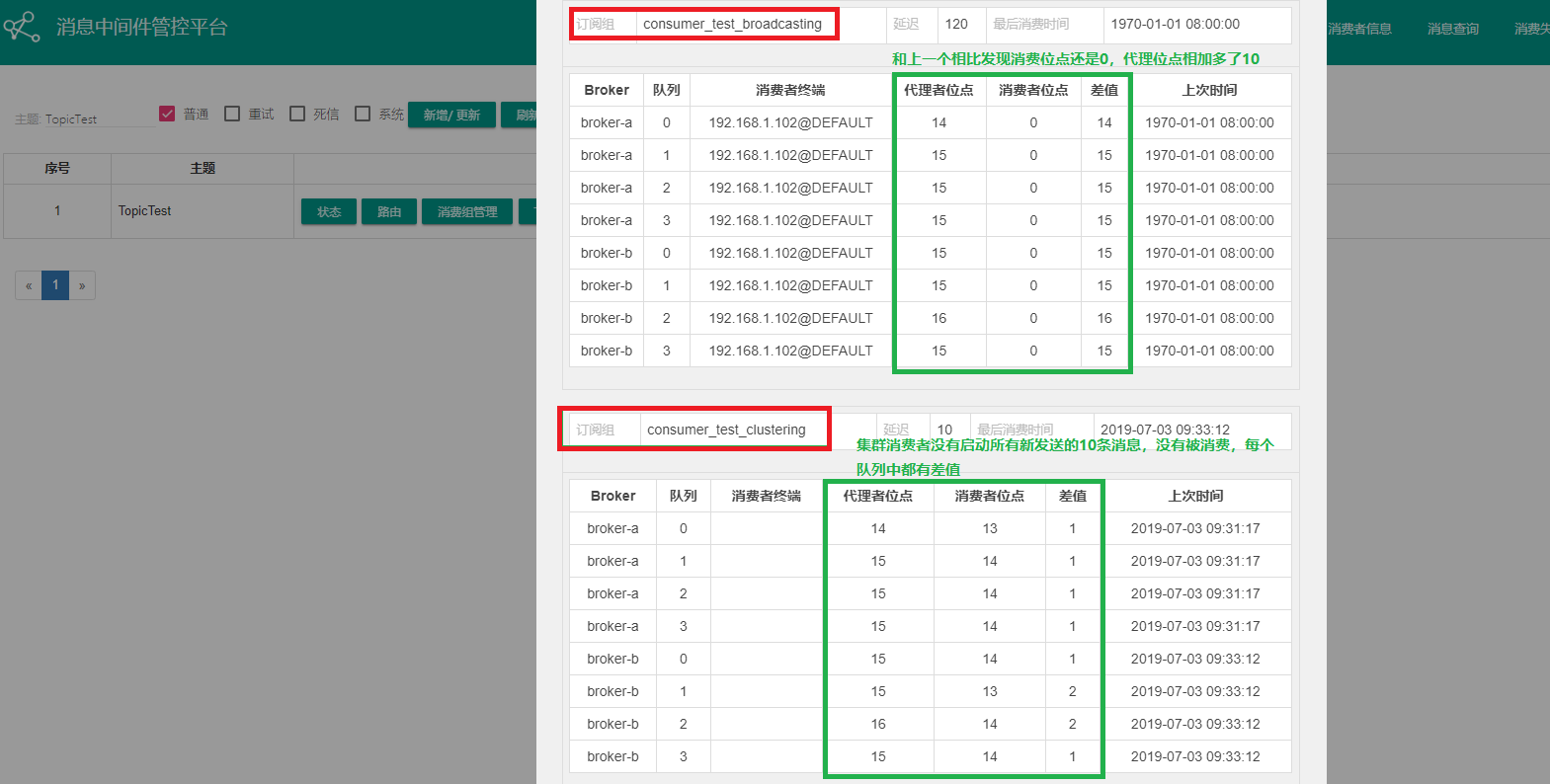
廣播模式下消息發送前后其消費位點還是0,其實是因為廣播模式下消息消費后其消息的狀態不做改變
集群模式下消息發送后,如果消費者消費成功后消費位點也會增加,該消費組的消息狀態會改變
我們查看下本地的消費進度文件
{
"offsetTable":{{
"brokerName":"broker-a",
"queueId":3,
"topic":"TopicTest"
}:15,{
"brokerName":"broker-a",
"queueId":2,
"topic":"TopicTest"
}:15,{
"brokerName":"broker-b",
"queueId":3,
"topic":"TopicTest"
}:15,{
"brokerName":"broker-b",
"queueId":0,
"topic":"TopicTest"
}:15,{
"brokerName":"broker-a",
"queueId":1,
"topic":"TopicTest"
}:15,{
"brokerName":"broker-b",
"queueId":2,
"topic":"TopicTest"
}:16,{
"brokerName":"broker-a",
"queueId":0,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-b",
"queueId":1,
"topic":"TopicTest"
}:15
}
}發現已經改變了其消費位點
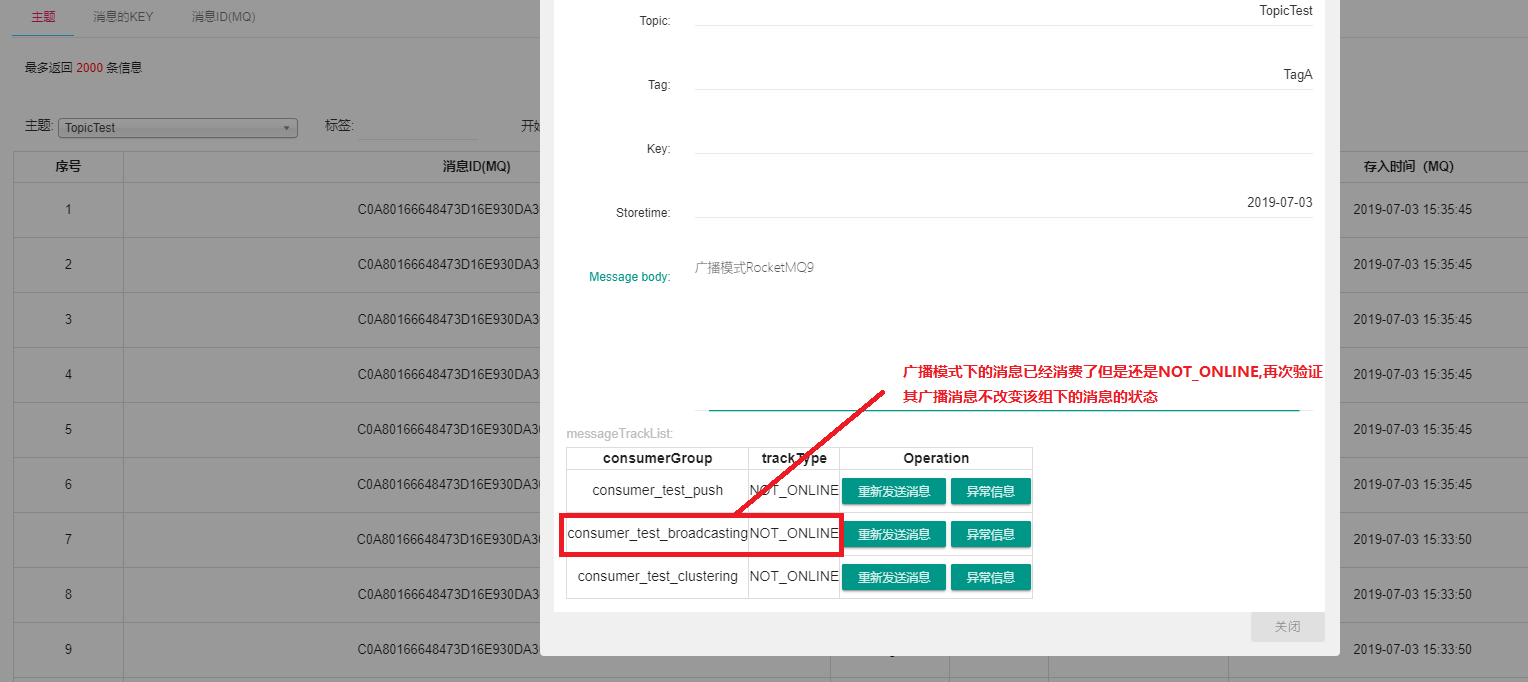
廣播模式下會有一些問題,我們具體分析下。

當看到這個圖的時候是不是會有一些疑問我們明明啟用了兩個消費者為什么消費者的ID為什么是相同的,難道圖中標注的有問題?其實不然,這個就是消費者的ID我們進一步探討下。
**consumer.start();**消費者啟動的源碼查找,其核心方法是DefaultMQPushConsumerImpl.start(),分析其源碼,我們查看一下其消費者的ID生成
this.mQClientFactory=MQClientManager.getInstance().getAndCreateMQClientInstance(this.defaultMQPushConsumer,this.rpcHook);
public MQClientInstance getAndCreateMQClientInstance(final ClientConfig clientConfig, RPCHook rpcHook) {
String clientId = clientConfig.buildMQClientId();
MQClientInstance instance = this.factoryTable.get(clientId);
if (null == instance) {
instance =
new MQClientInstance(clientConfig.cloneClientConfig(),
this.factoryIndexGenerator.getAndIncrement(), clientId, rpcHook);
MQClientInstance prev = this.factoryTable.putIfAbsent(clientId, instance);
if (prev != null) {
instance = prev;
log.warn("Returned Previous MQClientInstance for clientId:[{}]", clientId);
} else {
log.info("Created new MQClientInstance for clientId:[{}]", clientId);
}
}
return instance;
}String clientId = clientConfig.buildMQClientId();
private String instanceName = System.getProperty("rocketmq.client.name", "DEFAULT");
public String buildMQClientId() {
StringBuilder sb = new StringBuilder();
sb.append(this.getClientIP());
sb.append("@");
sb.append(this.getInstanceName());
if (!UtilAll.isBlank(this.unitName)) {
sb.append("@");
sb.append(this.unitName);
}
return sb.toString();
}我們發現其clientId 是由兩部分組成客戶端IP地址,和InstanceName中間用了“@”連接,當然InstanceName可以設置,默認則是DEFAULT,這樣我們就解釋了其為什么消費者啟動了兩個其客戶端消費者的ID只有一個。
廣播模式消費下當客戶端需要啟動多個消費者的時候,建議手動設置其InstanceName,沒有設置時會發現其消費進度是使用的一個文件。
廣播模式消費時我們如果遷移客戶端則會重新生成其消費進度文件,默認開始消費的位置為隊列的尾部,之前的消費默認放棄,消費的起始位置可以配置(PS:下一章節會介紹)
廣播模式消費時.rocketmq_offsets文件夾下的消費者ID/消費組名稱文件夾下的offsets.json很重要,切記不能刪除或損壞,否則消費進度會有影響,消費時可能導致數據重復或丟失
C:/Users/gumx/.rocketmq_offsets/192.168.1.102@DEFAULT/consumer_test_broadcasting/offsets.json
改造其消費端ConsumerGB1、ConsumerGB2分別設置InstanceName為00001、00002
public class ConsumerGB1 {
public static void main(String[] args){
try {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer();
consumer.setConsumerGroup("consumer_test_broadcasting");
//設置廣播消費
consumer.setMessageModel(MessageModel.BROADCASTING);
consumer.setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
consumer.subscribe("TopicTest", "*");
//設置其InstanceName
consumer.setInstanceName("00001");
consumer.registerMessageListener(new MessageListenerConcurrently(){
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> paramList,
ConsumeConcurrentlyContext paramConsumeConcurrentlyContext) {
try {
for(MessageExt msg : paramList){
String msgbody = new String(msg.getBody(), "utf-8");
System.out.println("ConsumerGB1=== MessageBody: "+ msgbody);//輸出消息內容
}
} catch (Exception e) {
e.printStackTrace();
return ConsumeConcurrentlyStatus.RECONSUME_LATER; //稍后再試
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //消費成功
}
});
consumer.start();
System.out.println("ConsumerGB1===啟動成功!");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}我們查看其消費進度文件夾
 廣播模式下如果兩個消費者GB1、GB2的InstanceName相同消費組相同,都啟動情況下,發送消息時都會消費消息,其中GB1異常停止,GB2正常消費,則GB1手動干預啟動后,異常停止期間的消息不會再消費,因為公用一個消費進度文件。
廣播模式下如果兩個消費者GB1、GB2的InstanceName相同消費組相同,都啟動情況下,發送消息時都會消費消息,其中GB1異常停止,GB2正常消費,則GB1手動干預啟動后,異常停止期間的消息不會再消費,因為公用一個消費進度文件。
關于RocketMQ消費模式是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





