溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么理解數據庫分布式架構的高并發處理”,在日常操作中,相信很多人在怎么理解數據庫分布式架構的高并發處理問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么理解數據庫分布式架構的高并發處理”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
高并發介紹
在同時或者極短時間內,有大量請求到達服務端,每個請求都需要服務端耗費資源進行處理,并做出相應反饋
服務端比如同時開啟進程數,能同時運行的線程數、網絡連接數、CPU運算、I/O、內存都是有限,
所以服務端能同時處理請求也是有限的。高并發本質就是資源的有限性
如:1.系統在線人數10W,并不意味系統并發用戶是10W,可能存在10w用戶同時在首頁查看靜態文章,并未對服務器進行發送請求
那么高并發數 是根據系統真實用戶數并發送請求需要服務端耗費資源進行處理的請求
2.服務端只能開啟100個線程,恰好1個線程處理一個請求需要耗時1s,那么服務端1s只能處理100個請求,多余請求無法處理
經典案例
商品、活動秒殺下訂單
準備階段
系統獨立部署
做好系統容量規劃(7-7.5折計算),系統優化、系統容災限流等方案
做好系統拆分,如:功能模塊、實時/非實時、動態/靜態等
參加活動商品設置定時上架時間
服務器時間同步(集群中每臺機器時鐘要保持一致)
動態生成下單頁面的URL
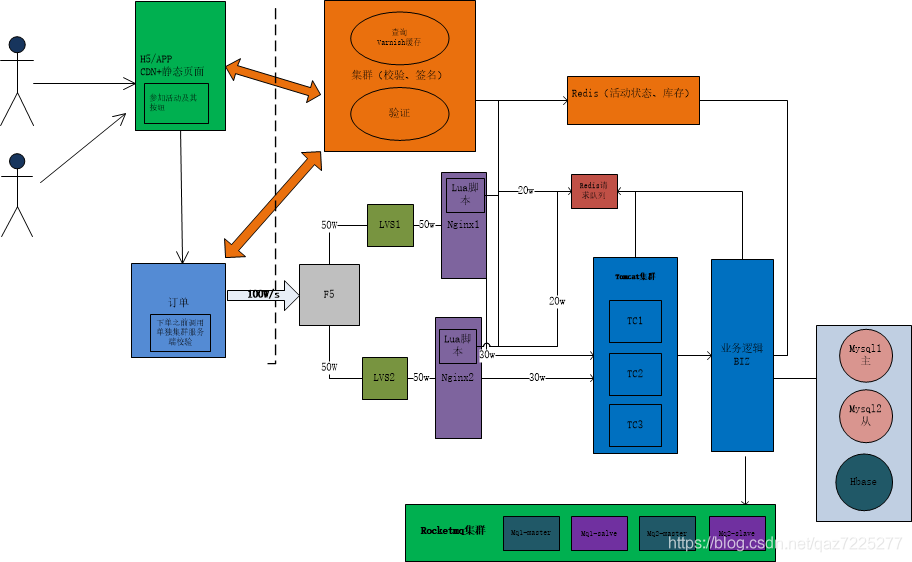
實現階段
客戶端層面:
前端頁面采用h6靜態化,ajax獲取動態內容;如實時庫存、活動狀態、當前時間等
做CDN部署加速
靜態頁面和資源緩存 如:(圖片)
JS針對請求過濾,減少請求發送到達服務端 如:(獲取驗證碼、時間截止或已售空自動結束等)
Web端層面:
F5/LVS+Nginx接收高并發請求、并做負載均衡
Lua腳本+Redis做請求隊列,針對有效請求用List排隊,并實現一些基本操作(限流、賬號參加次數檢查、同一IP請求數檢查)
Redis單線程高性能,每秒處理100W請求,如果大于100W請求如何處理呢?
1.可以結合Lua腳本控制請求數量并限流,有效減少redis壓力;比如100W請求,過濾20W,還剩80W,無效請求直接返回客戶端不到達服務端
2.如果應用非常龐大,用戶流量高額,Redis單節點做成集群模式,請求處理數量也隨之增加
Varnish緩存靜態頁面和靜態資源
Tomcat集群,預處理,通過業務場景判斷用戶是具備參加活動資格、賬號是否正常、是否在黑名單等
邏輯層面:
按照Redis請求隊列進行先后處理
純內存操作+異步(通過Redis完成減庫存,1.利用Redis的watch事物 2.利用Redis腳本Lua原子操作減庫存)
高并發產生問題,分析思考
服務端處理響應會逐漸變慢,甚至會丟失部分請求不處理,嚴重會導致服務器崩潰
客戶端(app\h6)、前端請求(nginx/varnish)、web服務器(webServer)、web應用(rmi/dubbo/遠程調用)、緩存(redis/membercache)、消息隊列(mq)、數據庫(db)都會面臨高并發等問題
高并發優化思路
客戶端層面
盡量減少請求數量,充分利用客戶端、瀏覽器自身緩存,如微服務前后端交互、網絡傳輸詳細記載,本文不在詳敘
盡量減少對服務端資源不必要浪費,如重復請求連接后端打開/關閉操作連接池
Nginx層面
動靜分離,靜態資源直接返回
負載均衡,如F5/LVS分流多個Nginx
根據系統業務,單獨拆分訪問(路徑)
Varnish層面
動態內容緩存、減少訪問后端服務
使用頁面片段緩存技術,如ESI
Web服務器層面
針對JVM配置進行合理優化
服務器配置進行優化,如:調整內存數量、線程數量等
相同服務部署多臺機器,實現負載均衡
增加資源,如增加網絡帶寬、高性能服務器、高性能數據庫 (立桿見效,服務器普通硬盤換SSD,數據庫換物理機等)
請求分流
1.使用集群:如之前1臺處理100個請求,增加兩臺后,3臺機器虛擬組成一個集群后,對外處理請求可以提升到300*80%=240
2.采用微服務架構,后續微服務架構高可用會詳細描述
Web應用層面(優化應用程序)
提高單個請求的處理速度,如上如果處理一個請求消耗從1s降低到0.5秒,并發就是200
耗時業務同步根據業務情況 使用mq異步處理
比如導入、導出耗時耗力 合理使用多線程批量處理、指向單臺應用獨立處理
高效使用緩存,減少鎖的使用范圍
優化訪問數據庫SQL
盡量避免遠程調用、大量I/O等耗時操作
合理規劃事物等比較耗資源操作
部分業務考慮采用預計算處理,減少實時計算耗資源操作 如:報表
不要盲目使用RPC、netty、http遠程網絡調用,如需特定調用注意加上超時時間
數據庫層面
合理使用數據庫引擎 如 mysql的InnoDB和MyISAM引擎
數據庫系統參數配置優化
特殊復雜計算耗時操作可以考慮使用存儲過程來處理
數據庫集群,進行讀寫分離
合理設計數據庫表結構、索引 如(組合索引)
分庫、分區、分表降到單庫單表并發量
到此,關于“怎么理解數據庫分布式架構的高并發處理”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





