溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Java內存模型可見性的分析,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
給定程序以及一個檢測程序是否合法的執行跟蹤,JMM工作原理是檢查執行跟蹤中的每個讀,并根據某些規則檢查讀觀察到的寫是否有效
JMM中可能產生的行為表現為不論代碼是如何實現程序行為,只要保證程序的所有結果執行和JMM預期的結果一致即可
基于上述的第二點,對實現者執行的代碼進行轉換的實現就比較自由,可以實現操作的重排序甚至刪除不必要的同步操作代碼
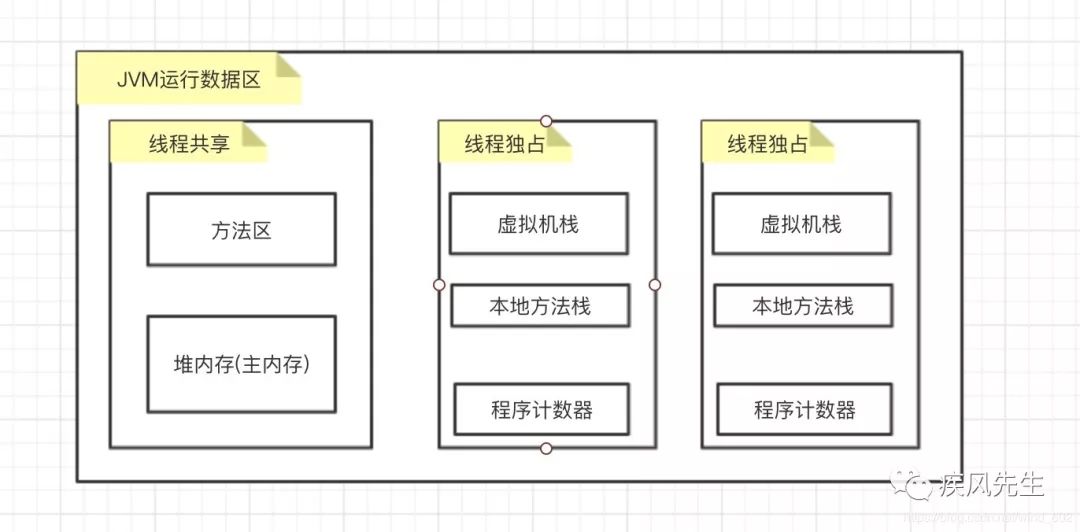
線程共享與獨占區域
線程共享區域: JVM運行數據區中的方法區,堆內存存儲的數據變量,存在數據競爭,即數據讀寫的安全問題
線程獨占區域: JVM為每個線程單獨創建的私有區域,用于存儲當前線程私有的數據變量,不存在數據競爭,比如線程局部變量,ThreadLocal/ThreadLocalRandom等
線程通信產生數據競爭
簡要的源代碼
// constant.java
final int P = 10;
final int C = 20;
// shared.java
int pwrite = 0;
int cwrite = 0;
// producer.java
int pread = 0;
public void run(){
pread = cwrite; // 生產者線程需要消費者線程cwrite的數據
pwrite = P;
}
// consumer.java
int cread = 0;
public void run(){
cread = pwrite;// 消費者線程需要生產者線程的pwrite數據
cwrite = C;
}
//按正常結果輸出的預期值推斷,不會產生同時pread == C(20)和cread == P(10)結果反推分析(基于我們看到的代碼順序)
如果上述的執行結果成立,那么cwrite = C一定是在pread = cwrite之前執行的;
由于cwrite = C是在cread = pwrite之后執行,所以cread = pwrite一定是在pread = cwrite之前執行的;
也就是cread = pwrite一定是在pwrite = P之前執行的,所以結果是不成立
產生問題
線程既然存在寫操作,那么寫操作的數據變量一定會讓另一個線程讀取到對應寫后的數據么?
由于線程本身也有自己的工作內存,因此讀取數據變量不一定就是另一個線程寫操作之后的數據,此時可能讀取到工作內存上的緩存數據(臟數據)
同時基于JMM規范,產生優化后可能執行的代碼
public void run(){
pread = cwrite; // 生產者線程需要消費者線程cwrite的數據 --1
pwrite = P; // --2
}
// consumer.java
int cread = 0;
public void run(){
cwrite = C; // --3
cread = pwrite;// 消費者線程需要生產者線程的pwrite數據 -4
}在上述兩個線程中分析
線程在并發下,可能產生執行的順序為3-1-2-4,也就是同時產生pread == C(20)和cread == P(10)
數據競爭
當前線程對一個變量執行寫操作
同時另一個線程對相同的變量執行讀操作
讀寫操作沒有通過同步實現排序
產生問題
不同線程之間通信會對共享變量的數據產生競爭,在這種情況下,JMM作出重排序的優化會導致輸出結果與預期的結果不一致,如果放在實際的業務場景中,將會導致很多無法控制的業務邏輯錯誤,后果不可想象.
JMM下的并發問題
其一,讀取到的共享數據不一定是寫操作之后的數據,也就是寫操作對讀操作不可見(緩存導致)
其二,JMM為了提升性能對代碼進行重排序,那么就會導致數據產生的結果和預期的不一致(重排序導致)
線程之工作內存
JMM抽象之工作內存(線程本地內存)
線程棧中的存儲的變量,如局部變量,方法參數,異常處理參數等
CPU高速緩存
線程,工作內存,JMM與主內存
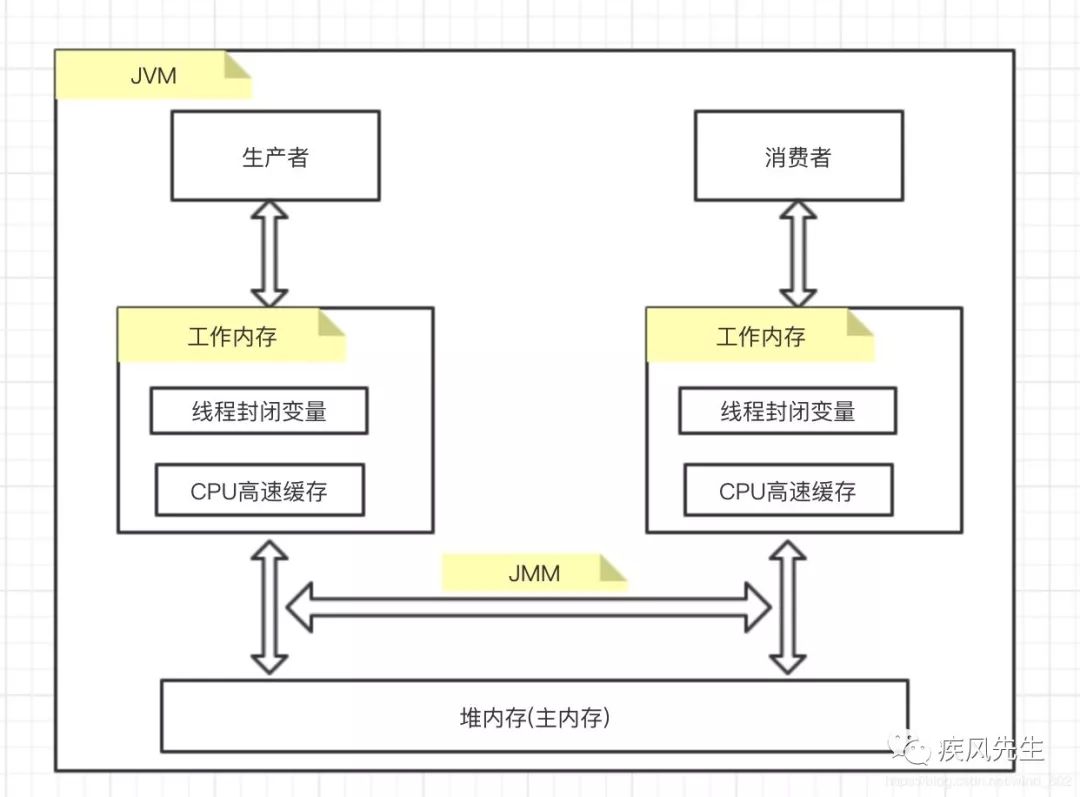 從上述可知,在JVM運行數據區中,工作內存與主內存是通過JMM模型規范來完成彼此之間的數據交互,因此可以通過JMM定義的內存語義規范來提供數據變量的可見性
從上述可知,在JVM運行數據區中,工作內存與主內存是通過JMM模型規范來完成彼此之間的數據交互,因此可以通過JMM定義的內存語義規范來提供數據變量的可見性
基于緩存問題解決方案
JMM規范規定使用針對的技術手段時,將強制線程直接繞過工作內存讀取主內存的共享數據
常用技術手段:volatile/synchronized/final/具有內存同步的操作指令
重排序
遵循規則
as-if-serial: 即不管怎么進行重排序(編譯器和處理器為了提高并行度),(單線程)程序的執行結果不能被改變.編譯器/runtime/處理器都必須遵循as-if-serial語義,也就是說編譯器和處理器不會對存在數據依賴關系的操作做重排序
重排序的分類
編譯器重排序: 基于單個線程程序的語義前提下,Java開啟server模式(clinet不支持)可以對程序代碼進行編譯優化
處理器重排序:在沒有存在數據依賴的前提下,處理器可以改變機器指令的執行順序
重排序解決方案
編譯器會根據JMM特定類型(同步代碼標志等)禁止進行重排序
在Java編譯器生成指令之前插入特定的內存屏障來禁止處理器重排序
內存屏障類型: 參見CPU高速緩存與內存屏障
關于Java內存模型可見性的分析問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





