溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關LBP的原理是什么,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
LBP特征的描述
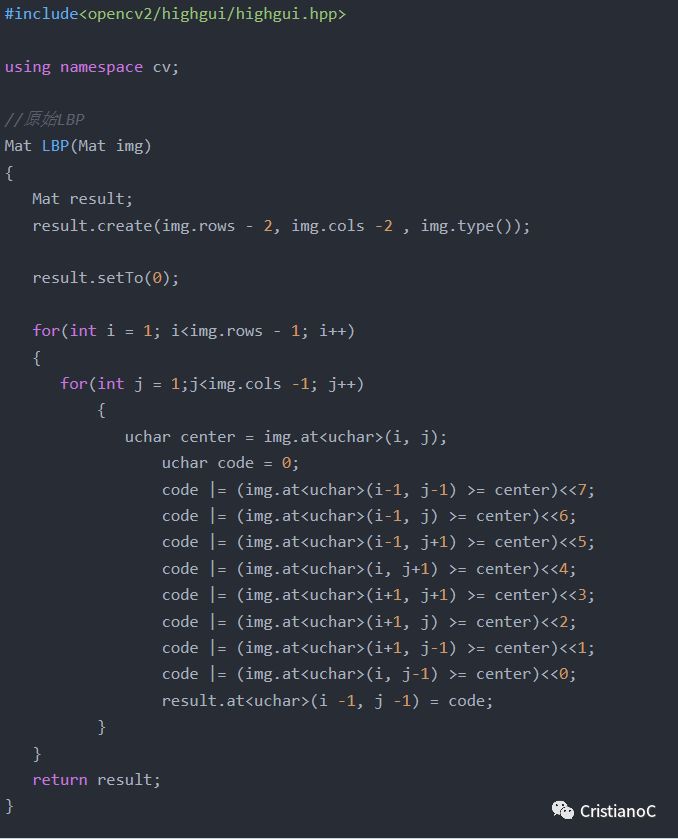
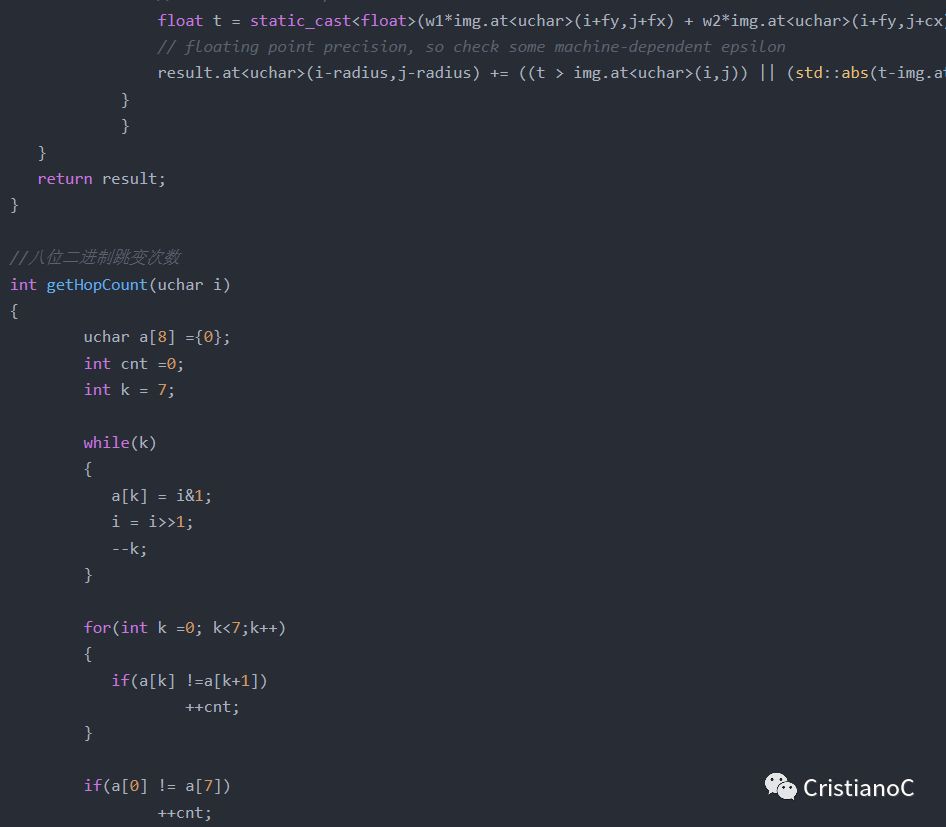
原始的LBP算子定義為在3*3的窗口內,以窗口中心像素為閾值,將相鄰的8個像素的灰度值與其進行比較,若周圍像素值大于中心像素值,則該像素點的位置被標記為1,否則為0。這樣,3*3鄰域內的8個點經比較可產生8位二進制數(通常轉換為十進制數即LBP碼,共256種),即得到該窗口中心像素點的LBP值,并用這個值來反映該區域的紋理信息。具體圖示如下:

LBP的改進
看完基本LBP運算算子之后有些讀者可能內心會有疑惑,如果某個區域是圓形或者其他尺寸怎么辦?研究人員提出了以下的改進版本。
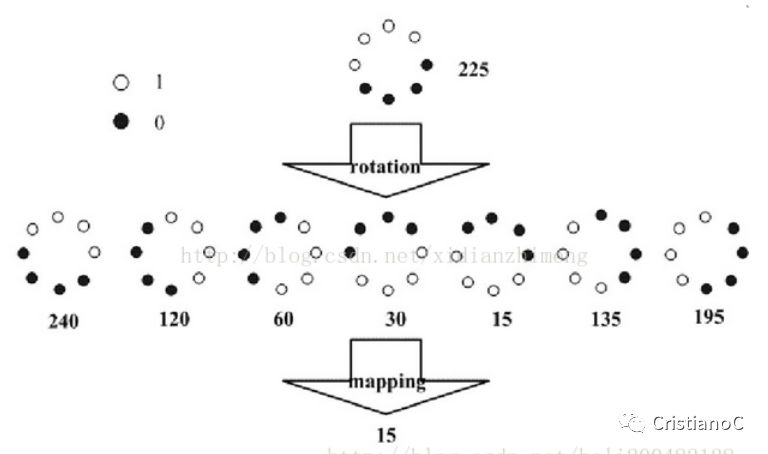
(1)圓形LBP算子
為了適應不同尺度的紋理特征,并達到灰度和旋轉不變性的要求,Ojala 等對 LBP 算子進行了改進,將 3×3 鄰域擴展到任意鄰域,并用圓形鄰域代替了正方
形鄰域,改進后的 LBP 算子允許在半徑為 R 的圓形鄰域內有任意多個像素點。從而得到了諸如半徑為R的圓形區域內含有P個采樣點的LBP算子,圖示如下:
(2)LBP的等價模式
??一個LBP算子可以產生不同的二進制模式,對于半徑為R的圓形區域內含有P個采樣點的LBP算子將會產生2的P次冪種模式。很顯然,隨著鄰域集內采樣點數的增加,二進制模式的種類是急劇增加的。例如:5×5鄰域內20個采樣點,有2的20次冪=1,048,576種二進制模式。如此多的二值模式無論對于紋理的提取還是對于紋理的識別、分類及信息的存取都是不利的。同時,過多的模式種類對于紋理的表達是不利的。例如,將LBP算子用于紋理分類或人臉識別時,常采用LBP模式的統計直方圖來表達圖像的信息,而較多的模式種類將使得數據量過大,且直方圖過于稀疏。因此,需要對原始的LBP模式進行降維,使得數據量減少的情況下能最好的代表圖像的信息。
為了解決二進制模式過多的問題,提高統計性,Ojala提出了采用一種“等價模式”(Uniform Pattern)來對LBP算子的模式種類進行降維。Ojala等認為,在實際圖像中,絕大多數LBP模式最多只包含兩次從1到0或從0到1的跳變。因此,Ojala將“等價模式”定義為:當某個LBP所對應的循環二進制數從0到1或從1到0最多有兩次跳變時,該LBP所對應的二進制就稱為一個等價模式類。如00000000(0次跳變),00000111(只含一次從0到1的跳變),10001111(先由1跳到0,再由0跳到1,共兩次跳變)都是等價模式類。除等價模式類以外的模式都歸為另一類,稱為混合模式類,例如10010111(共四次跳變)(這是我的個人理解,不知道對不對)。
通過這樣的改進,二進制模式的種類大大減少,而不會丟失任何信息。模式數量由原來的2的P次冪種減少為 P ( P-1)+2種,其中P表示鄰域集內的采樣點數。對于3×3鄰域內8個采樣點來說,二進制模式由原始的256種減少為58種,這使得特征向量的維數更少,并且可以減少高頻噪聲帶來的影響。
LBP的使用
在LBP的應用中,如紋理分類、人臉分析等,一般都不將LBP圖譜作為特征向量用于分類識別,而是采用LBP特征譜的統計直方圖作為特征向量用于分類識別。因為直接對兩幅圖片提取這種“特征”,并進行判別分析的話,會因為“位置沒有對準”而產生很大的誤差。后來,研究人員發現,可以將一幅圖片劃分為若干的子區域,對每個子區域內的每個像素點都提取LBP特征,然后,在每個子區域內建立LBP特征的統計直方圖。如此一來,每個子區域,就可以用一個統計直方圖來進行描述;整個圖片就由若干個統計直方圖組成; 例如:一個100*100像素大小的圖片,劃分為10*10=100個子區域(可以通過多種方式來劃分區域),每個子區域的大小為10*10像素;在每個子區域內的每個像素點,提取其LBP特征,然后,建立統計直方圖;這樣,這幅圖片就有10*10個子區域,也就有了10*10個統計直方圖,利用這10*10個統計直方圖,就可以描述這幅圖片了。之后,我們利用各種相似性度量函數,就可以判斷兩幅圖像之間的相似性了。圖示如下:
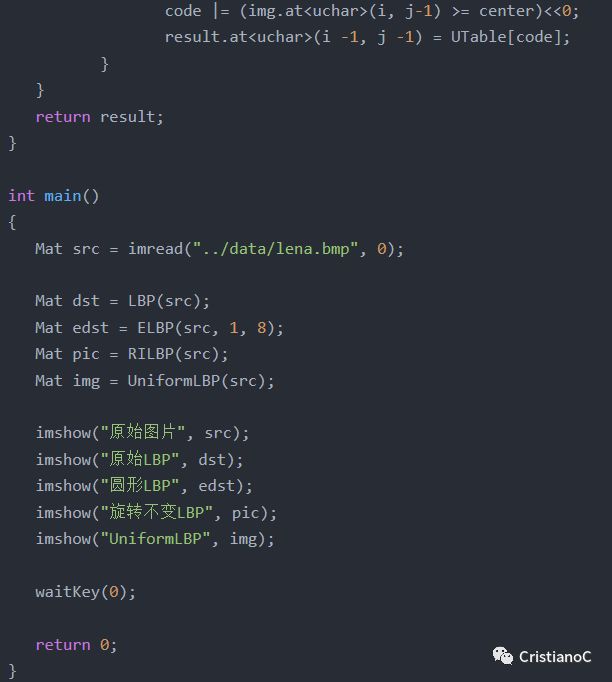
看完上述內容,你們對LBP的原理是什么有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





