溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“HashMap遍歷方法是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“HashMap遍歷方法是什么”吧!
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, Integer> next = entryIterator.next();
System.out.println("key=" + next.getKey() + " value=" + next.getValue());
}
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println("key=" + key + " value=" + map.get(key));
}
map.forEach((key,value)->{
System.out.println("key=" + key + " value=" + value);
});
強烈建議使用第一種 EntrySet 進行遍歷。
第一種可以把 key value 同時取出,第二種還得需要通過 key 取一次 value,效率較低, 第三種需要 JDK1.8 以上,通過外層遍歷 table,內層遍歷鏈表或紅黑樹。
在并發環境下使用 HashMap 容易出現死循環。
并發場景發生擴容,調用 resize() 方法里的 rehash() 時,容易出現環形鏈表。這樣當獲取一個不存在的 key 時,計算出的 index 正好是環形鏈表的下標時就會出現死循環。
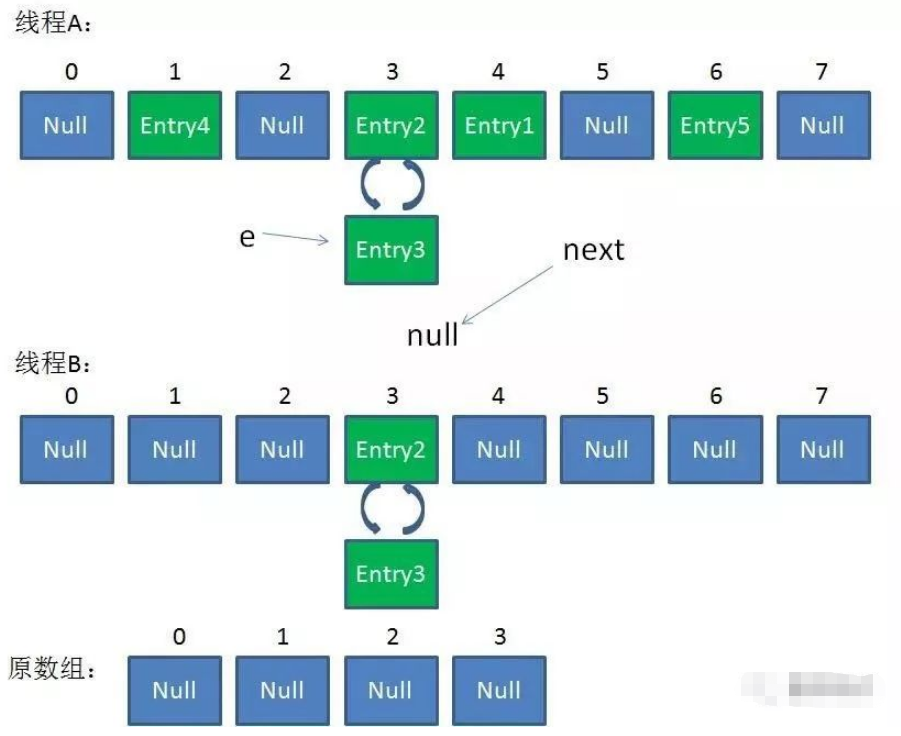
所以 HashMap 只能在單線程中使用,并且盡量的預設容量,盡可能的減少擴容。
在 JDK1.8 中對 HashMap 進行了優化: 當 hash 碰撞之后寫入鏈表的長度超過了閾值(默認為8),鏈表將會轉換為紅黑樹。
假設 hash 沖突非常嚴重,一個數組后面接了很長的鏈表,此時重新的時間復雜度就是 O(n) 。
如果是紅黑樹,時間復雜度就是 O(logn) 。
大大提高了查詢效率。
感謝各位的閱讀,以上就是“HashMap遍歷方法是什么”的內容了,經過本文的學習后,相信大家對HashMap遍歷方法是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





