溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關基于linux0.11系統的文件讀取原理是什么,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
小編的是文件系統樹,我們知道,文件系統的數據是存在硬盤里的,這里來看一下,這些數據是怎么組織成一棵樹,又是怎么進行遍歷的。下面就是這棵樹。
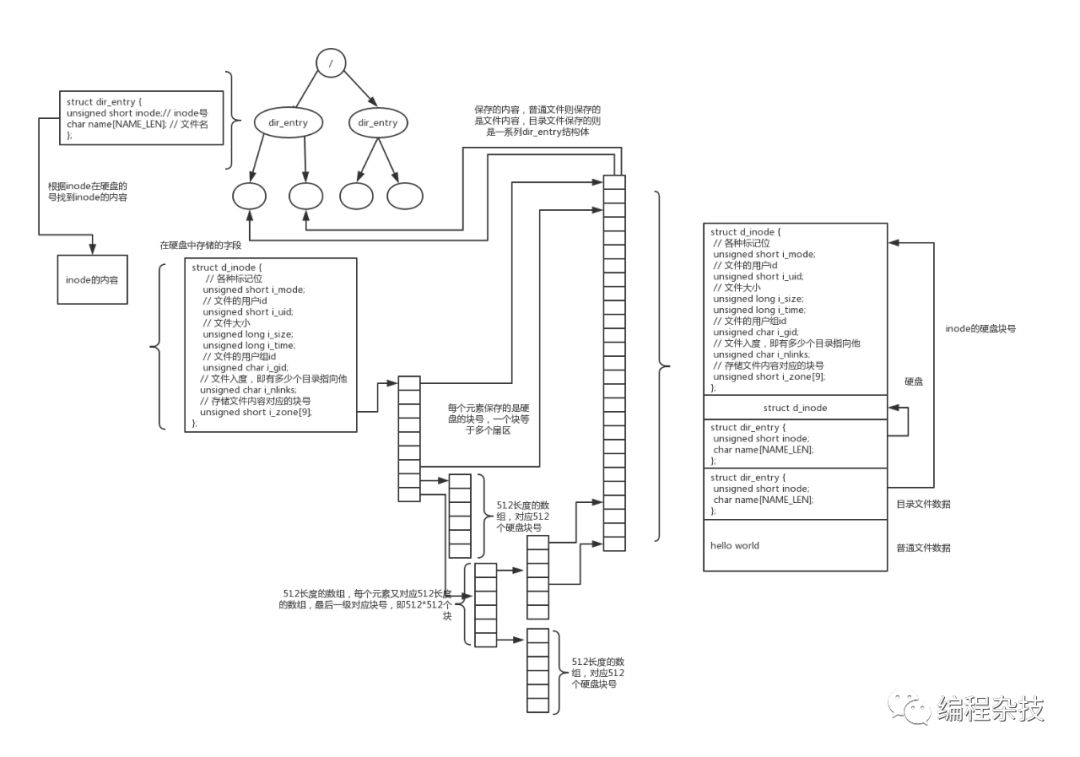
下面我們以讀取文件為線索,看一下過程是怎么樣的。
1 我們要先根據文件路徑找到文件對應的inode節點。假設是個絕對路徑。文件路徑是/a/b/c.txt。系統初始化的時候我們已經拿到了根目錄對應的inode。從inode的結構體結構中,我們知道inode有一個字段保存了文件的內容。所以這時候就把根目錄文件的文件內容讀進來,是一系列的dir_entry結構體。然后逐個遍歷,比較文件名是不是等于a,最后得到一個目錄a對應的dir_entry。
2 根據dir_entry結構體我們知道,里面不僅保存了文件名,還保存了對應的inode號。我們根據inode號把a目錄文件的內容也讀取進來。以此類推。最后得到c對應的dir_entry。
3 再根據c對應的dir_entry的inode號,從硬盤把inode的內容讀進來。發現他是一個普通文件。至此,我們找到了這個文件對應的inode節點。完成fd->file結構體->inode結構體的賦值。
4 然后我們開始讀取文件的內容。根據fd我們找到對應的inode節點。根據file結構體的pos字段,我們知道需要讀取的數據在文件中的偏移。根據這個偏移,可以算出應該取i_zone[9]字段的哪個索引,文件的前7塊對應索引0-6,前7到7+512對應索引7等。得到索引后,讀取i_zone數組在該索引的值,即我們要讀取的數據在硬盤的數據塊。然后把這個數據塊從硬盤讀取進來。返回給用戶。
5 至此,完成了文件的查找和讀取。
上述就是小編為大家分享的基于linux0.11系統的文件讀取原理是什么了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





