溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
refer : https://yq.aliyun.com/articles/530060?spm=a2c4e.11153940.blogcont181452.16.413f2ef21NKngz#
http://www.datayuan.cn/article/6737.htm
-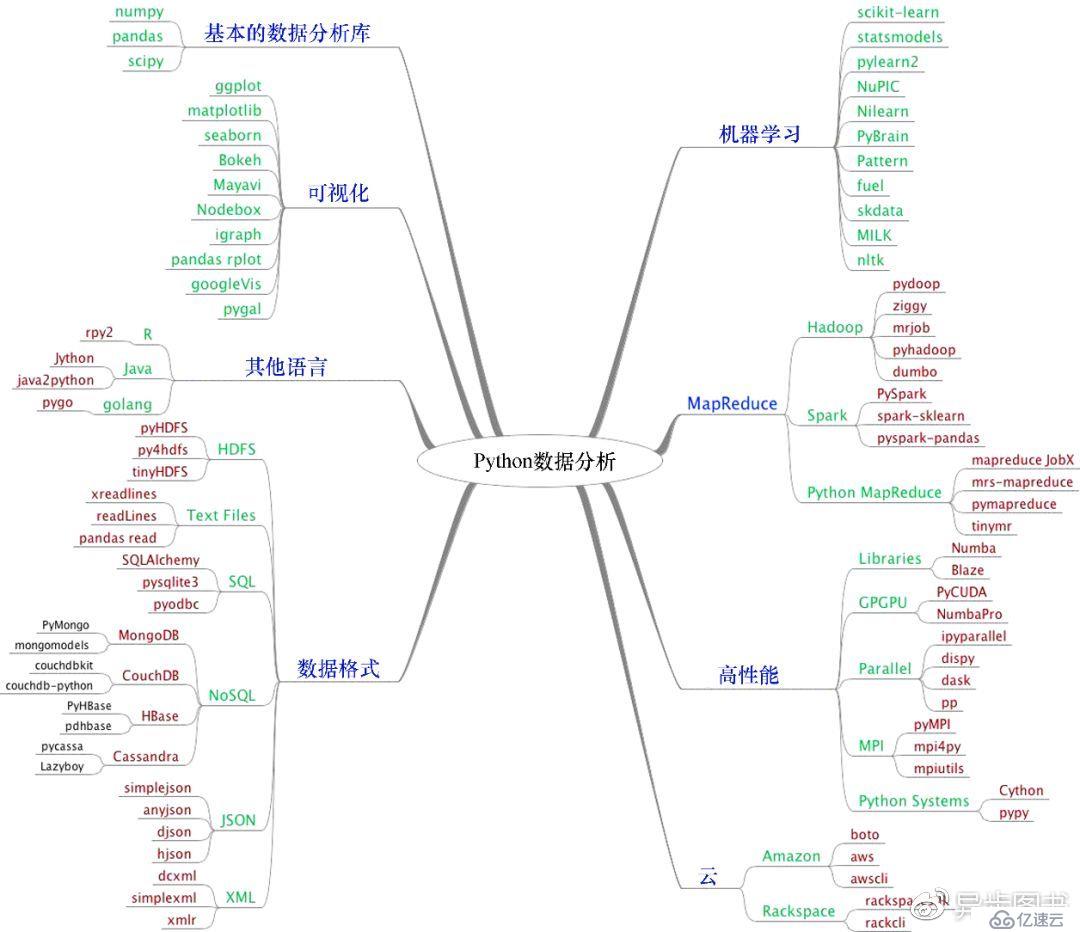
大文本數據的讀寫
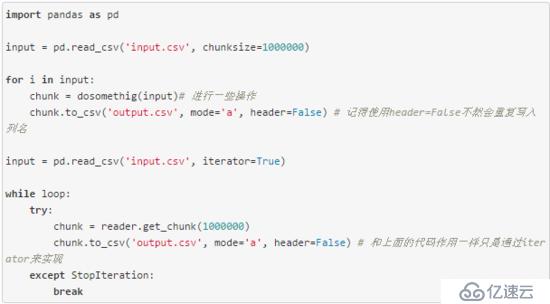
有時候我們會拿到一些很大的文本文件,完整讀入內存,讀入的過程會很慢,甚至可能無法讀入內存,或者可以讀入內存,但是沒法進行進一步的計算,這個時候如果我們不是要進行很復雜的運算,可以使用read_csv提供的chunksize或者iterator參數,來部分讀入文件,處理完之后再通過to_csv的mode='a',將每部分結果逐步寫入文件。
to_csv, to_excel的選擇
在輸出結果時統稱會遇到輸出格式的選擇,平時大家用的最多的.csv, .xls, .xlsx,后兩者一個是excel2003,一個是excel2007,我的經驗是csv>xls>xlsx,大文件輸出csv比輸出excel要快的多,xls只支持60000+條記錄,xlsx雖然支持記錄變多了,但是,如果內容有中文常常會出現詭異的內容丟失。因此,如果數量較小可以選擇xls,而數量較大則建議輸出到csv,xlsx還是有數量限制,而且 大數據 量的話,會讓你覺得python都死掉了
讀入時處理日期列
我之前都是在數據讀入后通過to_datetime函數再去處理日期列,如果數據量較大這又是一個浪費時間的過程,其實在讀入數據時,可以通過parse_dates參數來直接指定解析為日期的列。它有幾種參數,TRUE的時候會將index解析為日期格式,將列名作為list傳入則將每一個列都解析為日期格式
關于to_datetime函數再多說幾句,我們拿到的時期格式常常出現一些亂七八糟的怪數據,遇到這些數據to_datimetime函數默認會報錯,其實,這些數據是可以忽略的,只需要在函數中將errors參數設置為'ignore'就可以了。
另外,to_datetime就像函數名字顯示的,返回的是一個時間戳,有時我們只需要日期部分,我們可以在日期列上做這個修改,datetime_col = datetime_col.apply(lambda x: x.date()),用map函數也是一樣的datetime_col = datetime_col.map(lambda x: x.date())
把一些數值編碼轉化為文字
前面提到了map方法,我就又想到了一個小技巧,我們拿到的一些數據往往是通過數字編碼的,比如我們有gender這一列,其中0代表男,1代表女。當然我們可以用索引的方式來完成
其實我們有更簡單的方法,對要修改的列傳入一個dict,就會達到同樣的效果。
通過shift函數求用戶的相鄰兩次登錄記錄的時間差
之前有個項目需要計算用戶相鄰兩次登錄記錄的時間差,咋看起來其實這個需求很簡單,但是數據量大起來的話,就不是一個簡單的任務,拆解開來做的話,需要兩個步驟,第一步將登錄數據按照用戶分組,再計算每個用戶兩次登錄之間的時間間隔。數據的格式很單純,如下所示
如果數據量不大的,可以先unique uid,再每次計算一個用戶的兩次登錄間隔,類似這樣
這種方法雖然計算邏輯比較清晰易懂,但是缺點也非常明顯,計算量巨大,相當與有多少量記錄就要計算多少次。
那么為什么說pandas的shift函數適合這個計算呢?來看一下shift函數的作用
剛好把值向下錯位了一位,是不是恰好是我們需要的。讓我們用shift函數來改造一下上面的代碼。
上面的代碼就把pandas向量化計算的優勢發揮出來了,規避掉了計算過程中最耗費時間的按uid循環。如果我們的uid都是一個只要排序后用shift(1)就可以取到所有前一次登錄的時間,不過真實的登錄數據中有很多的不用的uid,因此再將uid也shift一下命名為uid0,保留uid和uid0匹配的記錄就可以了。
【方向】 2018-03-12 11:11:49 瀏覽2650 評論0
python
大數據
摘要: 本文是針對Python設計一種并行處理數據的解決方案——使用Dask和Numba并行化加速運算速度。案例對比分析了幾種不同方法的運算速度,非常直觀,可供參考。
如果你善于使用Pandas變換數據、創建特征以及清洗數據等,那么你就能夠輕松地使用Dask和Numba并行加速你的工作。單純從速度上比較,Dask完勝Python,而Numba打敗Dask,那么Numba+Dask基本上算是無敵的存在。將數值計算分成Numba sub-function和使用Dask map_partition+apply,而不是使用Pandas。對于100萬行數據,使用Pandas方法和混合數值計算創建新特征的速度比使用Numba+Dask方法的速度要慢許多倍。
Python:60.9x | Dask:8.4x | Numba:5.8x |Numba+Dask:1x
8be99f10ed908533e525b81fcd04bcdf3b27db2d
作為舊金山大學的一名數據科學碩士,會經常跟數據打交道。使用Apply函數是我用來創建新特征或清理數據的眾多技巧之一。現在,我只是一名數據科學家,而不是計算機科學方面的專家,但我是一個喜歡搗鼓并使得代碼運行更快的程序員。現在,我將會分享我在并行應用上的經驗。
大多Python愛好者可能了解Python實現的全局解釋器鎖(GIL),GIL會占用計算機中所有的CPU性能。更糟糕的是,我們主要的數據處理包,比如Pandas,很少能實現并行處理代碼。
Apply函數vs Multiprocessing.map
Tidyverse已經為處理數據做了一些美好的事情,Plyr是我最喜愛的數據包之一,它允許R語言使用者輕松地并行化他們的數據應用。Hadley Wickham說過:
“plyr是一套處理一組問題的工具:需要把一個大的數據結構分解成一些均勻的數據塊,之后對每一數據塊應用一個函數,最后將所有結果組合在一起。”
對于Python而言,我希望有類似于plyr這樣的數據包可供使用。然而,目前這樣的數據包還不存在,但我可以使用并行數據包構成一個簡單的解決方案。
Dask
bbcc3ca9a96dc7ad7129d9047a2d58be57a4ed84
之前在Spark上花費了一些時間,因此當我開始使用Dask時,還是比較容易地掌握其重點內容。Dask被設計成能夠在多核CPU上并行處理任務,此外也借鑒了許多Pandas的語法規則。
現在開始本文所舉例子。對于最近的數據挑戰而言,我試圖獲取一個外部數據源(包含許多地理編碼點),并將其與要分析的一大堆街區相匹配。在計算歐幾里得距離的同時,使用最大啟發式將最大值分配給一個街區。
8809febd555c55a69522a58770971c8cf0c57af5
最初的apply:
Dask apply:
二者看起來很相似,apply核心語句是map_partitions,最后有一個compute()語句。此外,不得不對npartitions初始化。 分區的工作原理就是將Pandas數據幀劃分成塊,對于我的電腦而言,配置是6核-12線程,我只需告訴它使用的是12分區,Dask就會完成剩下的工作。
接下來,將map_partitions的lambda函數應用于每個分區。由于許多數據處理代碼都是獨立地運行,所以不必過多地擔心這些操作的順序問題。最后,compute()函數告訴Dask來處理剩余的事情,并把最終計算結果反饋給我。在這里,compute()調用Dask將apply適用于每個分區,并使其并行處理。
由于我通過迭代行來生成一個新隊列(特征),而Dask apply只在列上起作用,因此我沒有使用Dask apply,以下是Dask程序:
Numba、Numpy和Broadcasting
由于我是根據一些簡單的線性運算(基本上是勾股定理)對數據進行分類,所以認為使用類似下面的Python代碼會運行得更快一些。
d31908d0ecfefd263b3e5373461b34374de9adf5
Broadcasting用以描述Numpy中對兩個形狀不同的矩陣進行數學計算的處理機制。假設我有一個數組,我會通過迭代并逐個變換每個單元格來改變它
相反,我完全可以跳過for循環,并對整個數組執行操作。Numpy與broadcasting混合使用,用來執行元素智能乘積(對位相乘)。
Broadcasting可以實現更多的功能,現在看看骨架代碼:
從本質上講,代碼的功能是改變數組。好的一方面是運行很快,甚至能和Dask并行處理速度比較。其次,如果使用的是最基本的Numpy和Python,那么就可以及時編譯任何函數。壞的一面在于它只適合Numpy和簡單Python語法。我不得不把所有的數值計算從我的函數轉換成子函數,但其計算速度會增加得非常快。
將其一起使用
簡單地使用map_partition()就可以將Numba函數與Dask結合在一起,如果并行操作和broadcasting能夠密切合作以加快運行速度,那么對于大數據集而言,將會看到其運行速度得到大幅提升。
09e60c6e34586f4760449a2159928877d49958cf
d9d0d60dc749ba864cbb200bb05b60e71ff6adcf
上面的第一張圖表明,沒有broadcasting的線性計算其表現不佳,并行處理和Dask對速度提升也有效果。此外,可以明顯地發現,Dask和Numba組合的性能優于其它方法。
上面的第二張圖稍微有些復雜,其橫坐標是對行數取對數。從第二張圖可以發現,對于1k到10k這樣小的數據集,單獨使用Numba的性能要比聯合使用Numba+Dask的性能更好,盡管在大數據集上Numba+Dask的性能非常好。
優化
為了能夠使用Numba編譯JIT,我重寫了函數以更好地利用broadcasting。之后,重新運行這些函數后發現,平均而言,對于相同的代碼,JIT的執行速度大約快了24%。
c9f6a34759b5b1298033c2e4ffd5d78a63994af5
可以肯定的說,一定有進一步的優化方法使得執行速度更快,但目前沒有發現。Dask是一個非常友好的工具,本文使用Dask+Numba實現的最好成果是提升運行速度60倍。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





