溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
sparkSQL在使用cache緩存的時候,有時候緩存可能不起作用,可能會發出緩存是假的吧的感慨。現在我們就把這個問題說道說道。
問題
當我們通過spark進行統計和處理數據時,發現他是延遲計算的,如果一個應用中出現多個action,而這多個action處理同一個數據源數據時,數據源用時間來過濾數據時,由于有多個action操作,遇到每個action就是一個job,每一個action都會執行數據源獲取數據的操作,由于兩個action之間的操作存在時間差,這兩個action獲取的數據有可能不一致。
例如下例
test1表中的數據
1,2018-07-01 10:10:03
2,2018-07-01 11:12:04
代碼如下操作
val odsData = spark.sql("""
select
from default.test1
where time < "2018-07-02"
""")
val targetData = odsData.map(fun _)
val targetData.createOrReplaceTempView("data1")
//第一個Action操作
val spark.sql("""
insert overwrite table default.test2
*
from data1
""")
val targetData1 = odsData.map(fun2 _) //引用同一個數據源
targetData1.createOrReplaceTempView("data2")
//第二個action操作
val spark.sql("""
insert table default.test2
*
from data2
""")
1,2018-07-01 10:10:03
2,2018-07-01 11:12:04
1,2018-07-01 10:10:03
2,2018-07-01 11:12:04
1,2018-07-01 10:10:03
2,2018-07-01 11:12:04
1,2018-07-01 10:10:03
2,2018-07-01 11:12:04
3,2018-07-01 13:12:04
結果是第二中情況。如果認為是第一種情況的對spark的執行計劃還是不太熟悉。首先spark是lazy計算的,即不觸發action操作,其實不提交作業的。而在這個application中存在兩個action,而這兩個aciton使用了同一個數據源的rdd,應該稱為變量odsData,當遇到第一個action,其會把自己這個執行鏈上的rdd都執行一遍,包括執行odsData,而遇到第二個aciton的時候,其也會把自己的執行鏈上的數據又執行了一遍包括odsData,并從數據源中重新取數。有人會疑惑,第一個action在執行的時候,已經執行了odsData,這個RDD的結果不應該緩存起來嗎?個人認為,spark還沒有那么的智能,并且網上經常說的job,stage,rdd,task的劃分應該是在同一個job內進行的。而同一個應用中夸job的stage拆分是不存在的。那么出現這個結果應該怎么辦呢?
cache的出場
當出現這樣的情況時,我的應用每天就會漏幾十條數據,很是煩人,最后發現了上面的問題,當時想解決方案時,第一個就是想到了cache,我把第一次執行Action操作時,把odsData給緩存了,這樣應該不會有什么問題了吧。從而可以保證兩個action操作,同一個數據源的數據一致性。只能說too young to sample了。這樣解決不了上面出現的問題。同樣以一個例子來看。
test表中的數據:
1 2017-01-01 01:00:00 2016-05-04 9999-12-31
2 2017-01-01 02:00:00 2016-01-01 9999-12-31
代碼:
val curentData = spark.sql(
"""
|select
|*
|from default.test
""".stripMargin)
curentData.cache() //緩存我們的結果
curentData.createOrReplaceTempView("dwData")
//第一個Action
spark.sql(
"""
|INSERT OVERWRITE TABLE default.test1
|SELECT
|
|FROM dwData
""".stripMargin)
//改變數據源表test表的數據并且是第二個Action
spark.sql(
"""
|INSERT OVERWRITE TABLE default.test
|SELECT
| 1,
| "2017",
| "2018",
| "2018"
|FROM default.test
""".stripMargin)
//第三個Action和第一個Action同數據源,并且cache第一次運行的結果。
spark.sql(
"""
|INSERT OVERWRITE TABLE default.test1
|SELECT
|
|FROM dwData
""".stripMargin)
那么test1表中的結果
第一種情況:
1 2017-01-01 01:00:00 2016-05-04 9999-12-31
2 2017-01-01 02:00:00 2016-01-01 9999-12-31
第二種情況
1 2017 2018 2018
1 2017 2018 2018
結果分析
結果是第二種情況,也就是說我們cache根本就沒有起到效果,或者說第三個Action根本就沒有使用我們cache的數據。這次我把日志都打出來了啊。
第一個Action的聲明周期: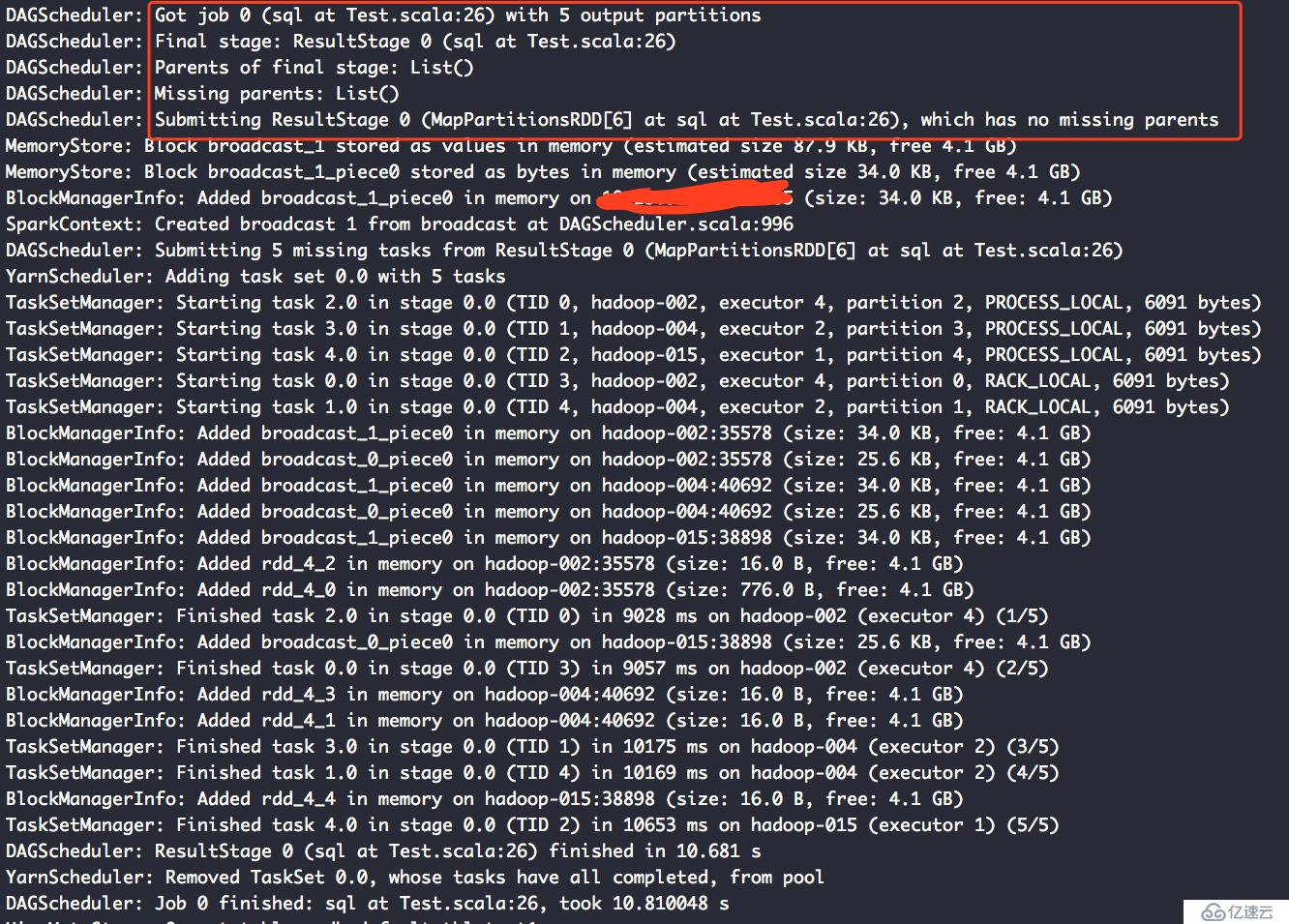
第三個Action的日志: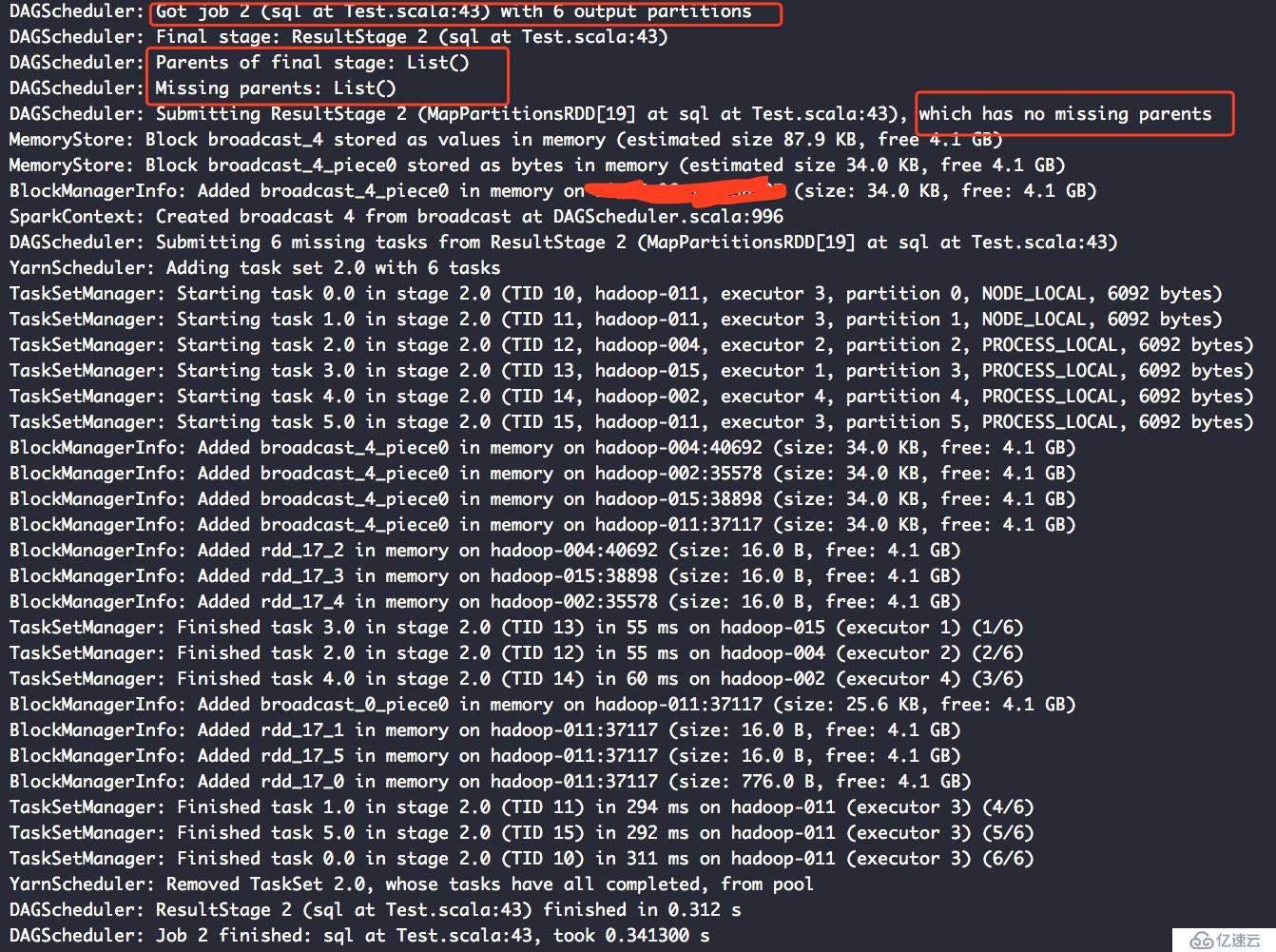
從這兩個日志可以看出,我們設置cache其只能在同一個job中生效。而夸job的使用這樣的數據緩存數據是不存在的。
如果想更加詳細的了解cache的原理和作用,可以去網上搜,大把大把的資料,但是一定要記住,網上說的要限定一個條件,在同一個job內的rdd,夸job的cache是不存在的。
解決方案
我們最終希望解決的事,當兩個action想要使用同一個數據源的rdd的時候,如何保證其數據的一致性。
方案:
把第一個Action算子用到的數據源給寫入到一個臨時表中
然后再第二個Action中,直接讀取臨時表的數據,而不是直接使用odsData
更好的方案還沒有想好,可以根據業務的不同來搞。
第二個方案現在就是我們使用spark提供的checkpoint機制,checkpoint會把我們的數據
自動緩存到hdfs,它就會把這個rdd以前的父rdd的數據全部刪除,以后不管哪個job的rdd
需要使用這個rdd的數據時,都會從這個checkpoin的目錄中讀取數據。
spark.sparkContext.setCheckpointDir("hdfs://hadoop-1:5000/hanfangfang")
curentData.cache().checkpoint
這樣就可以使不同的job,同一個數據源數據的一致性。
同時我們也要記住,當程序運行完成,其不會刪除checkpoint的數據的,需要們手動刪除。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





