溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何大幅度提高requests的訪問速度,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
我做了一個垃圾信息過濾的 HTTP 接口。現在有一千萬條消息需要經過這個接口進行垃圾檢測。
一開始我的代碼是這樣的:
import requests
messages = ['第一條', '第二條', '第三條']
for message in messages:
resp = requests.post(url, json={'msg': message}).json()
if resp['trash']:
print('是垃圾消息')
我們寫一段代碼來看看運行速度:
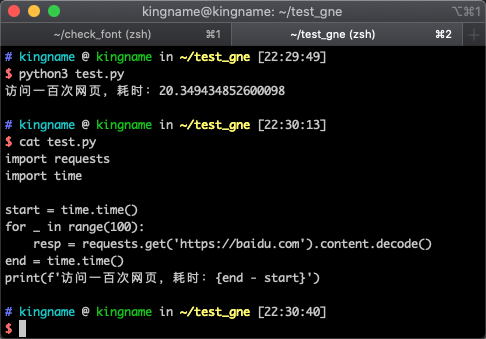
訪問一百次百度,竟然需要 20 秒。那我有一千萬條信息,這個時間太長了。
有沒有什么加速的辦法呢?除了我們之前文章講到的 多線程、aiohttp 或者干脆用 Scrapy 外,還可以讓 requests 保持連接從而減少頻繁進行 TCP 三次握手的時間消耗。
那么要如何讓 requests 保持連接呢?實際上非常簡單,使用Session對象即可。
修改后的代碼:
import requests
import time
start = time.time()
session = requests.Session()
for _ in range(100):
resp = session.get('https://baidu.com').content.decode()
end = time.time()
print(f'訪問一百次網頁,耗時:{end - start}')
運行效果如下圖所示:

性能得到了顯著提升。訪問 100 頁只需要 5 秒鐘。
在官方文檔[1]中,requests 也說到了 Session對象能夠保持連接:
?The Session object allows you to persist certain parameters across requests. It also persists cookies across all requests made from the Session instance, and will use urllib3’s connection pooling. So if you’re making several requests to the same host, the underlying TCP connection will be reused, which can result in a significant performance increase (see HTTP persistent connection).
”
?Excellent news — thanks to urllib3, keep-alive is 100% automatic within a session! Any requests that you make within a session will automatically reuse the appropriate connection!
”
看完上述內容,你們掌握如何大幅度提高requests的訪問速度的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





