溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關HifJzoc9和80T怎么獲取的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
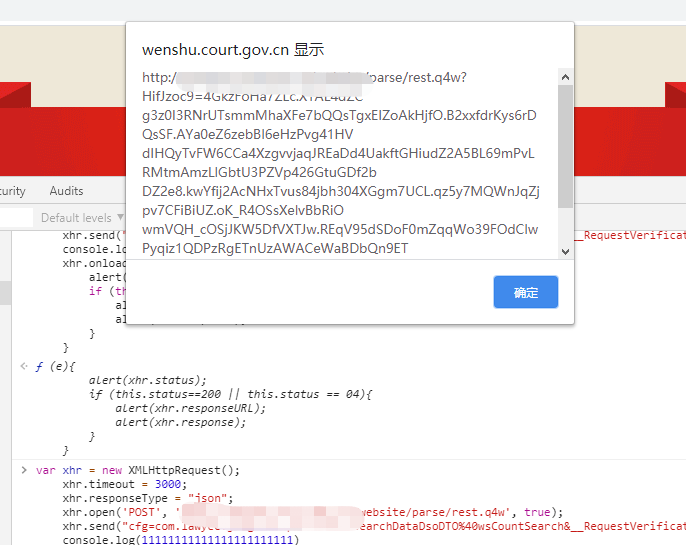
HifJzoc9 和 HM4hUBT0dDOn80T 的獲取思路直接去看控制臺請求,就會找到下面的這個請求,這個請求返回的就是列表內容

但是直接去找 HifJzoc9 是找不到。說明這是被后來加上去的。通過攔截 XMLHttpRequest ,將生成的參數加到請求參數里。而且在這個網站,這個參數的名字也是 js 動態生成。
下圖是 cookie 中 80T 的名字的生成地方。看好了就是名字。不要想太多。具體破解還未完成。

所以呢一種是增加 XHR 斷點,另一種就是使用下面的函數。這個函數我使用的時候是用谷歌插件的方式。
分享一個鉤子函數
var code = function () { var open = window.XMLHttpRequest.prototype.open; window.XMLHttpRequest.prototype.open = function open(method, url, async) { if (url.indexOf("HifJzoc9") > -1) { debugger; } };};var script = document.createElement('script');script.textContent = '(' + code + ')()';(document.head || document.documentElement).appendChild(script);script.parentNode.removeChild(script);
這個函數可以請求發送之前將該請求攔截。
既然可以攔截到請求,那就意味可以拿到當前環境下生成的加密參數。
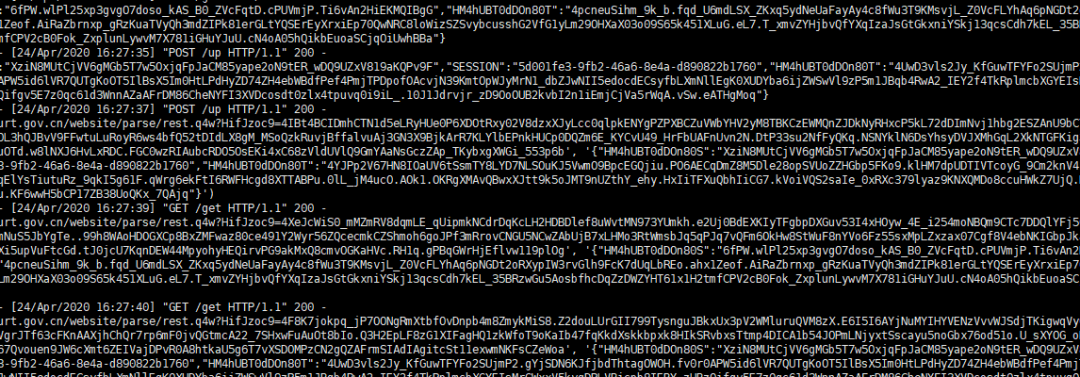
如果經常看這個網站的話,你就會注意到,他會每隔幾秒就會發起這樣的請求

所以我的攔截代碼就可以一直使用,一直攔截不讓他發起請求。從下圖就可以看到,請求并沒有發出去。
取消請求
window.XMLHttpRequest.abort();
url 參數取到了,就差 cookie 了。
直接在控制臺打印 cookie

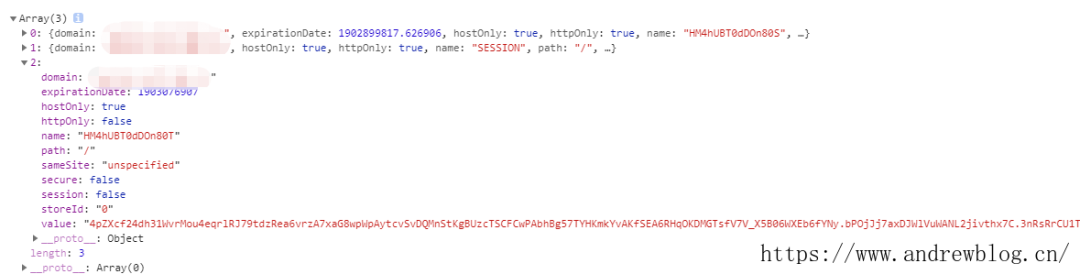
這樣打印出來其實是只有 80T 的,并沒有 80S.
這是因為 HTTPOnly 的原因。具體的可以去百度查查,現在基本大網站都有這個,也是為了安全

這個可以使用谷歌插件解決,可以看看谷歌文檔。
谷歌插件提供了一個方法。當然這個方法需要在背景頁中使用。填寫 URL后就可以獲取他的所有 cookies 。
chrome.cookies.getAll({url: "http://*.cn/"}, function (cookies) {});
80T 也是一直在刷新的,所以只需要一直獲取提交到你的爬蟲就完成了。
1、攔截 XMLHTTPRequest 請求
2、獲取到已經生成加密的參數后的 url

3、取消請求
window.XMLHttpRequest.abort();
4、獲取 cookie
5、將獲取到 cookie 和 url 發送給爬蟲。(這一塊都是通過插件的背景頁做的。網站有跨域限制,所以最后的發送操作都是在背景頁。具體的大家多看看插件,挺簡單的)
6、爬蟲請求數據。
谷歌插件 發送加密后的 url 以及 cookie 到接口,爬蟲通過接口獲取到值進行數據抓取。很簡單。
而且這網站只要你能獲取到這兩個東西,剩下就好說了,請求多了目前發現就只有個圖片驗證碼。
缺點就是:
如果需要大量抓取的話,就需要很多瀏覽器。
優點就是:
不用破解 js
還有一種思路就是通過 selenium 、pyppeteer、puppeteer 執行 js ,生成加密參數后,再取消請求。這樣就會更快的生成你想要的東西。也是挺爽的。
但是這種的我不知道如何再去取消請求,并且將參數攔截獲取出來。
感謝各位的閱讀!關于“HifJzoc9和80T怎么獲取”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





