溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“ElasticSearch索引數據優化的方法”,內容詳細,步驟清晰,細節處理妥當,希望這篇“ElasticSearch索引數據優化的方法”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
1. 索引數據優化
搜索引擎(以ES為例),是將一個查詢拆分為最細粒度的單位條件之后,按照單位條件檢索倒排索引得到單位結果集,然后對所有單位結果取交集得到最終的查詢結果,也就是說雖然一個查詢看起來只返回了10條記錄,但是有可能其中間結果是(100w)∩(100w)∩(100w)=10,所以看起來滿足條件的結果很少,但是查詢性能卻上不去。
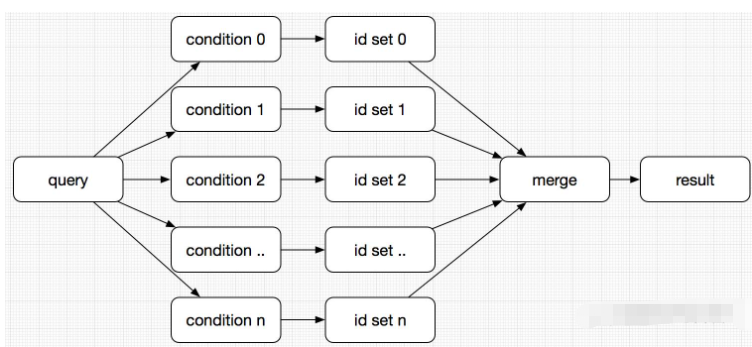
這時要優化性能,我們需要做的就是盡量減少中間結果集大小,讓取交集的時間盡可能短:
冷熱隔離
查詢倒排表是搜索引擎在執行查詢時必需要做的,單個條件得到的結果集(id set)越小,當然loop執行獲取交集的時間越短,所以大致上查詢性能與索引數據量的大小成正比。
當索引數據量變大之后,按照二八定律,80%的查詢落在最熱的20%數據上,那么將這20%數據單獨放到一個熱索引,可以有效減少單條件結果集大小,從而提高查詢性能;
ElasticSearch也會利用緩存來提高排序性能,比如fielddata,如果一個查詢命中了未緩存的冷字段,系統會自動加載該字段內容(fielddata)到內存,所以就冷查詢來說,通常帶排序的查詢要遠遠慢于普通查詢,如果做到冷熱隔離,命中熱索引的冷查詢加載fielddata的時間會大大減少,就算是冷查詢也能基本滿足低rt的查詢需求。
水平拆分
冷熱隔離有時候并不一定能完美解決業務需求,比如店內搜索,商品編輯很多,冷熱交替頻繁,而且80%的店鋪商品量都不大。
對于此類數據,有個明顯的特點是所有的查詢都帶有店鋪屬性,也就是只查詢單店鋪內的數據,這時候就可以考慮索引水平拆分了,按照店鋪維度將所有的商品數據拆分為n個子索引。
這樣原本一次查詢需要加載全部字段數據(fielddata),就可以變為只加載店鋪所在的某個子索引的字段數據(1/n),所耗費的資源能下降幾個數量級,另外單條件匹配倒排索引得到的結果集也可以縮小到原本的1/n,能夠濾掉很多其它店鋪的數據(對于本次查詢來說就是廢數據)。
當然拆分策略可以視具體的業務而定,比如也可以按照時間范圍來拆分。
另外補充一點,之所以沒有垂直拆分是因為搜索引擎沒有辦法做在線join操作,要實現join需要自己動手取不同索引的數據做交集,如果跨度范圍大或者帶了排序條件,那么跨索引的查詢基本是無解。
引擎配置
配置調優一般是搜索引擎性能優化的第一步,這里又可以分為server配置和索引配置兩方面:
server配置
Lucene系的搜索引擎都是跑在jvm上的,所以合適的jvm啟動參數對搜索引擎的表現有著重要的影響,如果分配的heap內存很大則更是如此,這里我就拋磚引玉把我們目前用到的一些jvm參數列一下,理念也就是盡量控制garbage內存在ygc時就回收掉,控制臨時的大對象不進入old區(當然優化查詢讓這些臨時大對象少生成也是一方面,下文會講到):
-XX:MaxGCPauseMillis=2000
-XX:+PrintGCDateStamps
-XX:+G1PrintHeapRegions
-XX:+UnlockDiagnosticVMOptions
-XX:+UnlockExperimentalVMOptions
-XX:+PrintAdaptiveSizePolicy
-XX:G1HeapRegionSize=32m
-XX:G1ReservePercent=15
-XX:InitiatingHeapOccupancyPercent=60
在集群規模擴大之后,將各個node按角色拆分為master/data/client也是需要做
的,將全集群的狀態同步/選舉過程等任務剝離到master,將結果聚合(內存開銷很大)/客戶端連接交互(http協議如果有大量短連接創建/銷毀,開銷也很大)等任務剝離到client,盡量減輕data node的負載(查詢/索引執行過程都是data node負責的),以提高服務性能。
針對ElasticSearch,其緩存配置和breaker配置也需要根據業務應用場景調整,比如寫多讀少并且索引量比較大的場景可以適當降低filter cache大小,調高field data大小(盡量讓加載到內存的字段內容保留,冷加載一次field data是有比較大開銷的,而且失效的field data eviction也會加重gc的負擔);
而讀多寫少并且索引量也比較小的場景就可以降低field data的大小,調高filter的比例(提高緩存復用率);
breaker配置最好寫定比例,盡量讓緩存不要在堆內存互相擠兌,避免加重gc負擔。
索引配置
索引配置比較靈活,粒度也比較細,當我們查詢索引時其實都是查詢某個時間的一個快照數據,只有index searcher重載一次索引文件,這期間(兩次reopen index searcher之間)對索引進行的操作才會可見,這段時間也叫做刷新時間(refresh_interval);
需要注意的是重載索引文件(reopen index searcher)的開銷很大,所以一般搜索引擎都是提供近實時的查詢服務,以減少重載索引文件的次數,降低系統負載,有個案例:曾經將一個索引的刷新時間從1s調整到5s,整個搜索響應時間從200ms降低到20ms以內,效果可見一斑。
字段配置是索引配置的一方面,簡而言之就是能不索引的就不索引,能不存到引擎的就不存,也要避免出現大面積的稀疏數據分布,目的就是減少資源消耗/減小索引文件大小,以提高內存使用率,降低merge時間(索引文件需要定期merge,清理碎片文件);
有條件也可以指定查詢routing,讓某個查詢能夠直接命中特定的shard,而不必去所有shard收集數據,減少等待時間;
到5.x版本,ES還是可以配置一個索引包含多個type的,實際上同一個索引的多個type物理上是存儲在同一個索引文件目錄內,也就是共享同一批索引文件,僅僅是通過隱藏的_uid/_type字段來區分。
那么問題來了,如果某個type的數據量遠遠大于其他type,數據量最大的type就會成為其他type性能表現的瓶頸(merge受影響,如果字段不相同還會導致稀疏數據問題,浪費寶貴的mem資源)。
因此生產中我們是禁止一個索引包含多個type的,而在ES6.x版本預告中也表示7.0版本中將使用默認type,不再允許同一個索引配置多type了。
順便提一句:多type在字段映射(mapping)上也有所限制,同名字段必須使用相同的類型 。
讀到這里,這篇“ElasticSearch索引數據優化的方法”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





