溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Reformer如何分析及應用,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
來自Google AI的最新的進展。
理解序列數據 —— 如語言、音樂或視頻 —— 是一項具有挑戰性的任務,特別是當它依賴于大量的周圍環境時。例如,如果一個人或一個物體在視頻中消失,很久以后又重新出現,許多模型就會忘記它的樣子。在語言領域,長短時記憶(LSTM)神經網絡覆蓋了足夠的上下文來逐句翻譯。在這種情況下,上下文窗口(在翻譯過程中需要考慮的數據范圍),從幾十個詞到大約 100 個詞不等。最新的 Transformer 模型不僅改進了逐句翻譯的性能,還可以通過多文檔摘要生成整個 Wikipedia 的文章。這是可能的,因為 Transformer 使用的上下文窗口可以擴展到數千個單詞。有了這樣一個大的上下文窗口,Transformer 可以用于文本以外的應用,包括像素或音符,使其能夠用于生成音樂和圖像。
但是,將 Transformer 擴展到更大的上下文窗口會遇到限制。Transformer 的能力來自于注意力,在這個過程中,它考慮上下文窗口中所有可能的單詞對,以理解它們之間的聯系。因此,對于 100K 個單詞的文本,這需要評估 100K x 100K 個單詞對,或者每一步 100 億對,這是不切實際的。另一個問題是存儲每個模型層輸出的標準實踐。對于使用大型上下文窗口的應用程序,存儲多個模型層的輸出的內存需求很快變得非常大(從只有幾層的 GB 字節到有數千層的模型的 TB 字節)。這意味著,使用許多層的實際的 Transformer 模型只能用于幾段文本或生成簡短的音樂片段。
今天,我們將介紹 Reformer,這是一個 Transformer 模型,設計用于處理最多 100 萬個單詞的上下文窗口,所有這些都在一個單一的加速器上,并且只使用了 16GB 的內存。它結合了兩種關鍵技術來解決注意力和內存分配問題,這些問題限制了 Transformer 的應用只能使用長上下文窗口。Reformer 使用位置敏感散列(LSH)來降低處理過長序列和可逆殘差層的復雜性,從而更有效地使用可用內存。
注意力機制的問題
當將 Transformer 模型應用于非常大的文本序列時,第一個挑戰是如何處理注意力層。LSH 通過計算一個哈希函數來實現這一點,該哈希函數將類似的向量匹配在一起,而不是搜索所有可能的向量對。例如,在翻譯任務中,來自網絡第一層的每個向量表示一個單詞(在后續層中甚至有更大的上下文),不同語言中相同單詞對應的向量可能得到相同的散列。在下面的圖中,不同的顏色描繪了不同的哈希,相似的單詞有相同的顏色。當哈希值被分配時,序列會被重新排列,將具有相同哈希值的元素放在一起,并被分成片段(或塊),以支持并行處理。然后將注意力機制放在這些更短的塊(以及它們的相鄰塊以覆蓋溢出)中,從而大大減少了計算負載。
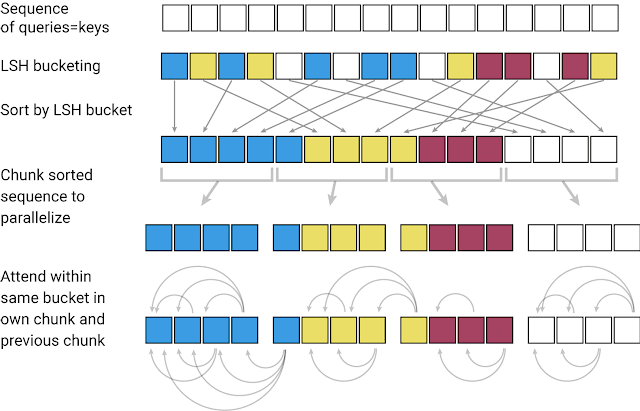
內存的問題
雖然 LSH 解決了注意力的問題,但仍然存在一個內存的問題。一個網絡的單層通常需要幾 GB 的內存,并且通常適用于一個 GPU,所以即使是一個具有長序列的模型在只有一層的情況下也是可以執行的。但是,當訓練一個具有梯度下降的多層模型時,需要保存每一層的激活值,以便在向后傳遞中使用。一個典型的 Transformer 模型有 12 個或更多的層,因此,如果用來緩存來自每個層的值,那么內存很快就會用完。
在 Reformer 中實現的第二個新方法是在反向傳播期間按需重新計算每個層的輸入,而不是將其存儲在內存中。這是通過使用可逆層來實現的,其中來自網絡的最后一層的激活被用來恢復來自任何中間層的激活,這相當于反向運行網絡。在一個典型的殘差網絡中,棧中的每一層都不斷地增加通過網絡的向量。相反,可逆層對每個層有兩組激活。一個遵循剛才描述的標準過程,并從一個層逐步更新到下一個層,但是另一個只捕獲對第一個層的更改。因此,要反向運行網絡,只需減去應用于每個層的激活。
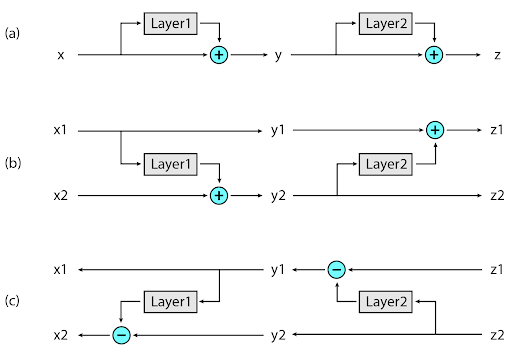
Reformer 的應用
在 Reformer 中,這兩種新方法的應用使其具有很高的效率,使其能夠僅使用 16GB 內存在單個 GPU 上處理長度高達 100 萬字的文本序列。由于 Reformer 具有如此高的效率,它可以直接應用于上下文窗口比幾乎所有當前最先進的文本域數據集大得多的數據。也許 Reformer 處理如此大的數據集的能力將刺激社區創建它們。
大上下文數據的一個不足之處是圖像生成,因此我們對圖像進行了 Reformer 的實驗。在這篇文章中,我們將舉例說明如何使用 Reformer 來“完成”部分圖像。從下圖最上面一行的圖像片段開始,Reformer 可以逐像素地生成全幀圖像(下面一行)。

雖然 Reformer 在圖像和視頻任務上的應用潛力巨大,但在文本上的應用更令人興奮。Reformer 可以一次性在單一的設備中處理整個小說。將來,當有更多的數據集需要訓練長文本時,諸如 Reformer 之類的技術可能會使生成長連貫的文本成為可能。
看完上述內容,你們掌握Reformer如何分析及應用的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





