溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下java中ZGC垃圾收集器有什么用,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
Java 11包含一個全新的垃圾收集器--ZGC,它由Oracle開發,承諾在數TB的堆上具有非常低的暫停時間。 在本文中,我們將介紹開發新GC的動機,技術概述以及由ZGC開啟的一些可能性。
那么為什么需要新GC呢?畢竟Java 10已經有四種發布多年的垃圾收集器,并且幾乎都是無限可調的。 換個角度看,G1是2006年時引入Hotspot VM的。當時最大的AWS實例有1 vCPU和1.7GB內存,而今天AWS很樂意租給你一個x1e.32xlarge實例,該類型實例有128個vCPU和3,904GB內存。 ZGC的設計目標是:支持TB級內存容量,暫停時間低(<10ms),對整個程序吞吐量的影響小于15%。 將來還可以擴展實現機制,以支持不少令人興奮的功能,例如多層堆(即熱對象置于DRAM和冷對象置于NVMe閃存),或壓縮堆。
為了理解ZGC如何匹配現有收集器,以及如何實現新GC,我們需要先了解一些術語。最基本的垃圾收集涉及識別不再使用的內存并使其可重用。現代收集器在幾個階段進行這一過程,對于這些階段我們往往有如下描述:
并行:在JVM運行時,同時存在應用程序線程和垃圾收集器線程。 并行階段是由多個gc線程執行,即gc工作在它們之間分配。 不涉及GC線程是否需要暫停應用程序線程。
串行:串行階段僅在單個gc線程上執行。與之前一樣,它也沒有說明GC線程是否需要暫停應用程序線程。
STW:STW階段,應用程序線程被暫停,以便gc執行其工作。 當應用程序因為GC暫停時,這通常是由于Stop The World階段。
并發:如果一個階段是并發的,那么GC線程可以和應用程序線程同時進行。 并發階段很復雜,因為它們需要在階段完成之前處理可能使工作無效。
增量:如果一個階段是增量的,那么它可以運行一段時間之后由于某些條件提前終止,例如需要執行更高優先級的gc階段,同時仍然完成生產性工作。 增量階段與需要完全完成的階段形成鮮明對比。
現在我們了解了不同gc階段的屬性,讓我們繼續探討ZGC的工作原理。 為了實現其目標,ZGC給Hotspot Garbage Collectors增加了兩種新技術:著色指針和讀屏障。
著色指針是一種將信息存儲在指針(或使用Java術語引用)中的技術。因為在64位平臺上(ZGC僅支持64位平臺),指針可以處理更多的內存,因此可以使用一些位來存儲狀態。 ZGC將限制最大支持4Tb堆(42-bits),那么會剩下22位可用,它目前使用了4位: finalizable, remap, mark0和mark1。 我們稍后解釋它們的用途。
著色指針的一個問題是,當您需要取消著色時,它需要額外的工作(因為需要屏蔽信息位)。 像SPARC這樣的平臺有內置硬件支持指針屏蔽所以不是問題,而對于x86平臺來說,ZGC團隊使用了簡潔的多重映射技巧。
要了解多重映射的工作原理,我們需要簡要解釋虛擬內存和物理內存之間的區別。 物理內存是系統可用的實際內存,通常是安裝的DRAM芯片的容量。 虛擬內存是抽象的,這意味著應用程序對(通常是隔離的)物理內存有自己的視圖。 操作系統負責維護虛擬內存和物理內存范圍之間的映射,它通過使用頁表和處理器的內存管理單元(MMU)和轉換查找緩沖器(TLB)來實現這一點,后者轉換應用程序請求的地址。
多重映射涉及將不同范圍的虛擬內存映射到同一物理內存。 由于設計中只有一個remap,mark0和mark1在任何時間點都可以為1,因此可以使用三個映射來完成此操作。 ZGC源代碼中有一個很好的圖表可以說明這一點。
讀屏障是每當應用程序線程從堆加載引用時運行的代碼片段(即訪問對象上的非原生字段non-primitive field):
void printName( Person person ) {
String name = person.name; // 這里觸發讀屏障
// 因為需要從heap讀取引用
//
System.out.println(name); // 這里沒有直接觸發讀屏障
}在上面的代碼中,String name = person.name 訪問了堆上的person引用,然后將引用加載到本地的name變量。此時觸發讀屏障。 Systemt.out那行不會直接觸發讀屏障,因為沒有來自堆的引用加載(name是局部變量,因此沒有從堆加載引用)。 但是System和out,或者println內部可能會觸發其他讀屏障。
這與其他GC使用的寫屏障形成對比,例如G1。讀屏障的工作是檢查引用的狀態,并在將引用(或者甚至是不同的引用)返回給應用程序之前執行一些工作。 在ZGC中,它通過測試加載的引用來執行此任務,以查看是否設置了某些位。 如果通過了測試,則不執行任何其他工作,如果失敗,則在將引用返回給應用程序之前執行某些特定于階段的任務。
現在我們了解了這兩種新技術是什么,讓我們來看看ZG的GC循環。
GC循環的第一部分是標記。標記包括查找和標記運行中的應用程序可以訪問的所有堆對象,換句話說,查找不是垃圾的對象。
ZGC的標記分為三個階段。 第一階段是STW,其中GC roots被標記為活對象。 GC roots類似于局部變量,通過它可以訪問堆上其他對象。 如果一個對象不能通過遍歷從roots開始的對象圖來訪問,那么應用程序也就無法訪問它,則該對象被認為是垃圾。從roots訪問的對象集合稱為Live集。GC roots標記步驟非常短,因為roots的總數通常比較小。
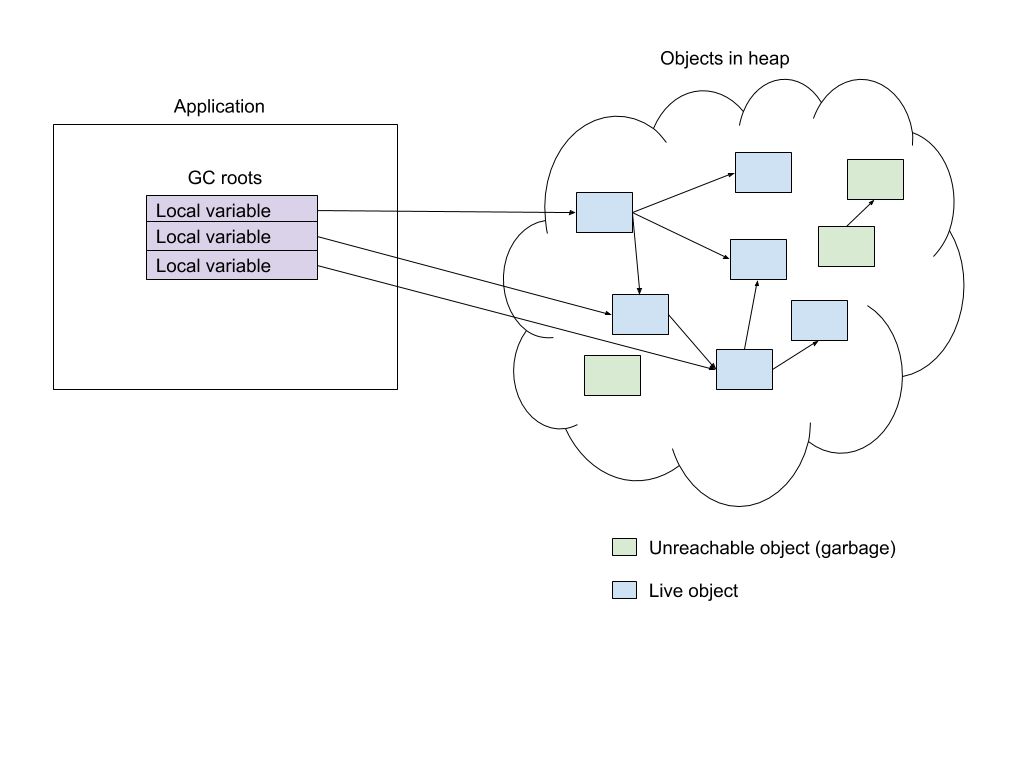
該階段完成后,應用程序恢復執行,ZGC開始下一階段,該階段同時遍歷對象圖并標記所有可訪問的對象。 在此階段期間,讀屏障針使用掩碼測試所有已加載的引用,該掩碼確定它們是否已標記或尚未標記,如果尚未標記引用,則將其添加到隊列以進行標記。
在遍歷完成之后,有一個最終的,時間很短的的Stop The World階段,這個階段處理一些邊緣情況(我們現在將它忽略),該階段完成之后標記階段就完成了。
GC循環的下一個主要部分是重定位。重定位涉及移動活動對象以釋放部分堆內存。 為什么要移動對象而不是填補空隙? 有些GC實際是這樣做的,但是它導致了一個不幸的后果,即分配內存變得更加昂貴,因為當需要分配內存時,內存分配器需要找到可以放置對象的空閑空間。 相比之下,如果可以釋放大塊內存,那么分配內存就很簡單,只需要將指針遞增新對象所需的內存大小即可。
ZGC將堆分成許多頁面,在此階段開始時,它同時選擇一組需要重定位活動對象的頁面。選擇重定位集后,會出現一個Stop The World暫停,其中ZGC重定位該集合中root對象,并將他們的引用映射到新位置。與之前的Stop The World步驟一樣,此處涉及的暫停時間僅取決于root的數量以及重定位集的大小與對象的總活動集的比率,這通常相當小。所以不像很多收集器那樣,暫停時間隨堆增加而增加。
移動root后,下一階段是并發重定位。 在此階段,GC線程遍歷重定位集并重新定位其包含的頁中所有對象。 如果應用程序線程試圖在GC重新定位對象之前加載它們,那么應用程序線程也可以重定位該對象,這可以通過讀屏障(在從堆加載引用時觸發)實現,如流程圖如下所示:
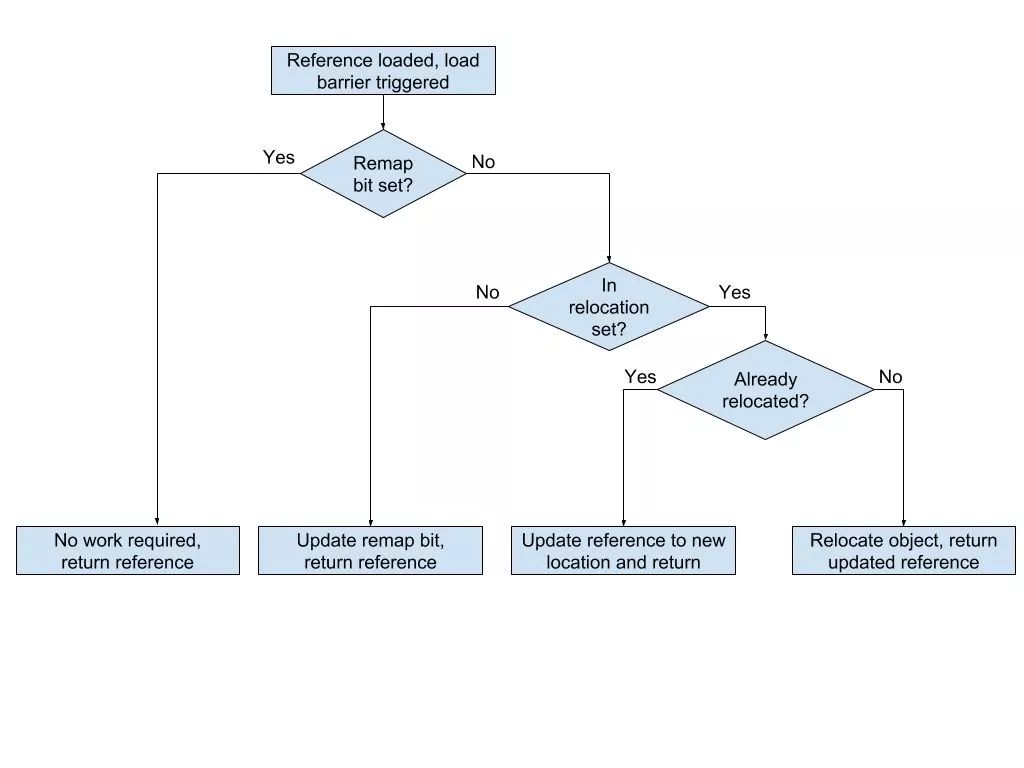
這可確保應用程序看到的所有引用都已更新,并且應用程序不可能同時對重定位的對象進行操作。
GC線程最終將對重定位集中的所有對象重定位,然而可能仍有引用指向這些對象的舊位置。 GC可以遍歷對象圖并重新映射這些引用到新位置,但是這一步代價很高昂。 因此這一步與下一個標記階段合并在一起。在下一個GC周期的標記階段遍歷對象對象圖的時候,如果發現未重映射的引用,則將其重新映射,然后標記為活動狀態。
試圖單獨理解復雜垃圾收集器(如ZGC)的性能特征是很困難的,但從前面的部分可以清楚地看出,我們所碰到的幾乎所有暫停都只依賴于GC roots集合大小,而不是實時堆大小。標記階段中處理標記終止的最后一次暫停是唯一的例外,但是它是增量的,如果超過gc時間預算,那么GC將恢復到并發標記,直到再次嘗試。
那ZGC到底表現如何?
Stefan Karlsson和Per Liden在今年早些時候的Jfokus演講中給出了一些數字。 ZGC的SPECjbb 2015吞吐量與Parallel GC(優化吞吐量)大致相當,但平均暫停時間為1ms,最長為4ms。 與之相比G1和Parallel有很多次超過200ms的GC停頓。
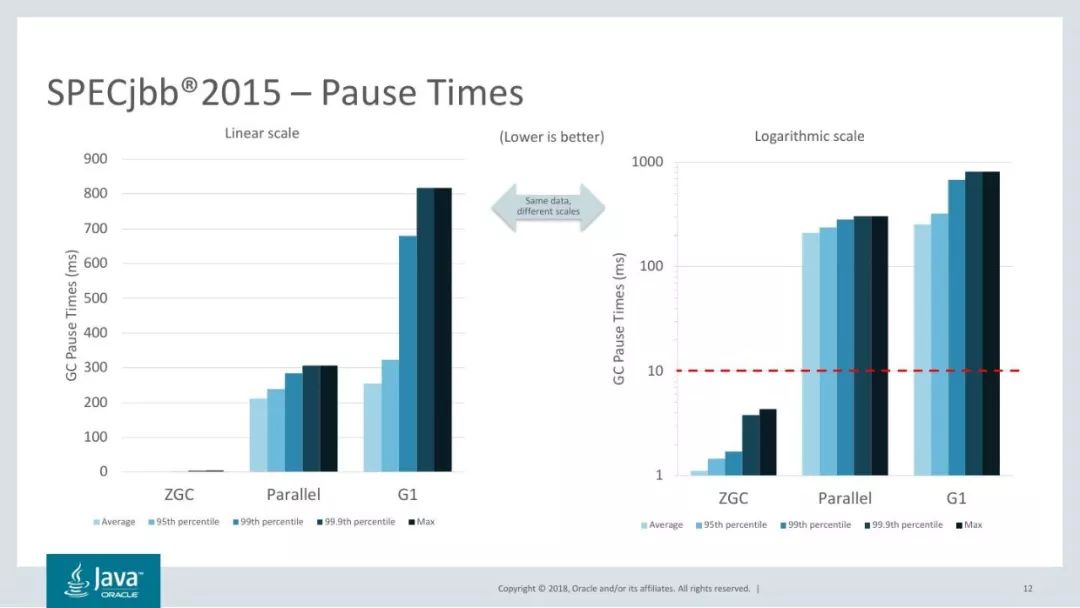
然而,垃圾收集器是復雜的軟件,從基準測試結果可能無法推測出真實世界的性能。我們期待自己測試ZGC,以了解它的性能如何因工作負載而異。
以上是“java中ZGC垃圾收集器有什么用”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





