溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關怎么使用Keras完成CNN模型搭建,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
對于圖像分類任務而言,卷積神經網絡(CNN)是目前最優的網絡結構,沒有之一。在面部識別、自動駕駛、物體檢測等領域,CNN被廣泛使用,并都取得了最優性能。對于絕大多數深度學習新手而言,數字手寫體識別任務可能是第一個上手的項目,網絡上也充斥著各種各樣的成熟工具箱的相關代碼,新手在利用相關工具箱跑一遍程序后就能立刻得到很好的結果,這時候獲得的感受只有一個——深度學習真神奇,卻沒能真正了解整個算法的具體流程。小編將利用Keras和TensorFlow設計一個簡單的二維卷積神經網絡(CNN)模型,手把手教你用代碼完成MNIST數字識別任務,便于理解深度學習的整個流程。
模型使用的MNIST數據集,該數據集是目前最大的數字手寫體數據集(0~9),總共包含60,000張訓練圖像和10,000張測試圖像,每張圖像的大小為28x28,灰度圖。第一步是加載數據集,可以通過Keras API完成:
#源代碼不能直接下載,在這里進行稍微修改,下載數據集后指定路徑#下載鏈接:https://pan.baidu.com/s/1jH6uFFC 密碼: dw3dfrom __future__ import print_functionimport kerasimport numpy as np path='./mnist.npz' f = np.load(path) X_train, y_train = f['x_train'], f['y_train'] X_test, y_test = f['x_test'], f['y_test']
上述代碼中,X_train表示訓練數據集,總共60,000張28x28大小的手寫體圖像,y_train表示訓練圖像對應的標簽。同理,X_test表示測試數據集,總共10,000張28x28大小的手寫體圖像,y_test表示測試圖像對應的標簽。下面對數據集部分數據進行可視化,以便更好地了解構建的模型深度學習模型的目的。
import matplotlib.pyplot as plt
fig = plt.figure()for i in range(9):
plt.subplot(3,3,i+1)
plt.tight_layout()
plt.imshow(X_train[i], cmap='gray', interpolation='none')
plt.title("Digit: {}".format(y_train[i]))
plt.xticks([])
plt.yticks([])
fig

# let's print the actual data shape before we reshape and normalizeprint("X_train shape", X_train.shape)print("y_train shape", y_train.shape)print("X_test shape", X_test.shape)print("y_test shape", y_test.shape)#input image size 28*28img_rows , img_cols = 28, 28#reshaping#"channels_first" assumes (channels, conv_dim1, conv_dim2, conv_dim3).X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)#more reshapingX_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255print('X_train shape:', X_train.shape) #X_train shape: (60000, 28, 28, 1)
對圖像信息進行必要的處理之后,標簽數據y_train和y_test被轉換為分類格式(向量形式),即標簽‘3’被轉換為向量[ 0,0,0,1,0,0,0,0,0,0]用于建模,標簽向量非零的位置減一(從0開始)后表示該圖像的具體標簽,即若圖像的標簽向量在下標5處不為0,則表示該圖像代表數字‘4’。
import keras#set number of categoriesnum_category = 10# convert class vectors to binary class matricesy_train = keras.utils.to_categorical(y_train, num_category) y_test = keras.utils.to_categorical(y_test, num_category)
在數據準備好提供給模型后,需要定義模型的體系結構并使用必要的優化函數,損失函數和性能指標進行編譯。
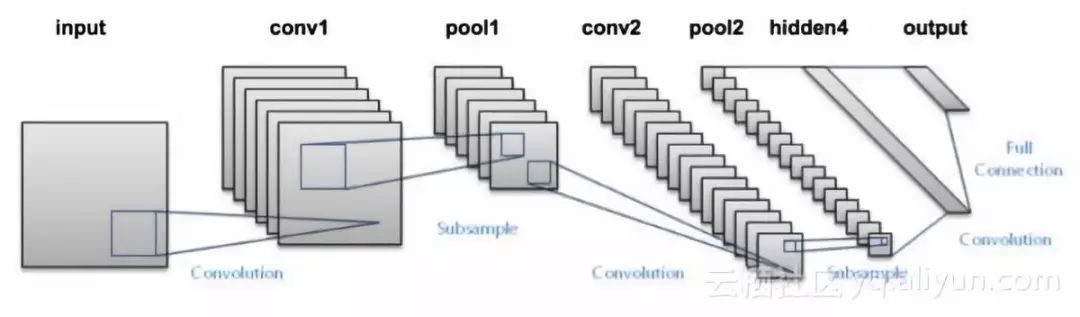
構建模型遵循的體系結構是經典卷積神經網絡,分別含有2個卷積層,之后是連接全連接層和softmax分類器。如果你對每層的作用不熟悉的話,建議學習CS231課程。
在最大池化層和全連接層之后,模型中引入dropout作為正則化來減少過擬合問題。
#導入相關層的結構from __future__ import print_functionimport kerasfrom keras.datasets import mnistfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2Dfrom keras import backend as kimport matplotlib.pyplot as pltimport numpy as np## model buildingmodel = Sequential()#convolutional layer with rectified linear unit activationmodel.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))#32 convolution filters used each of size 3x3#againmodel.add(Conv2D(64, (3, 3), activation='relu'))#64 convolution filters used each of size 3x3#choose the best features via poolingmodel.add(MaxPooling2D(pool_size=(2, 2)))#randomly turn neurons on and off to improve convergencemodel.add(Dropout(0.25))#flatten since too many dimensions, we only want a classification outputmodel.add(Flatten())#fully connected to get all relevant datamodel.add(Dense(128, activation='relu'))#one more dropout for convergence' sake :) model.add(Dropout(0.5))#output a softmax to squash the matrix into output probabilitiesmodel.add(Dense(num_category, activation='softmax'))
模型搭建好之后,需要進行編譯。在本文使用categorical_crossentropy多分類損失函數。由于所有的標簽都具有相似的權重,因此將其作為性能指標,并使用AdaDelta梯度下降技術來優化模型參數。
#Adaptive learning rate (adaDelta) is a popular form of gradient descent rivaled only by adam and adagrad#categorical ce since we have multiple classes (10) model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy'])
在定義和編譯模型架構之后,需要使用訓練數據對模型進行訓練,以便能夠識別手寫數字。即使用X_train和y_train來擬合模型。
batch_size = 128 num_epoch = 10#model trainingmodel_log = model.fit(X_train, y_train, batch_size=batch_size, epochs=num_epoch, verbose=1, validation_data=(X_test, y_test))
Epoch表示對所有訓練樣本進行一個前向傳播過程和一個反向傳播過程,Batch_Size表示每次前向過程和反向過程時處理的訓練樣本數,訓練輸出如下所示:

score = model.evaluate(X_test, y_test, verbose=0)print('Test loss:', score[0]) #Test loss: 0.0296396646054print('Test accuracy:', score[1]) #Test accuracy: 0.9904
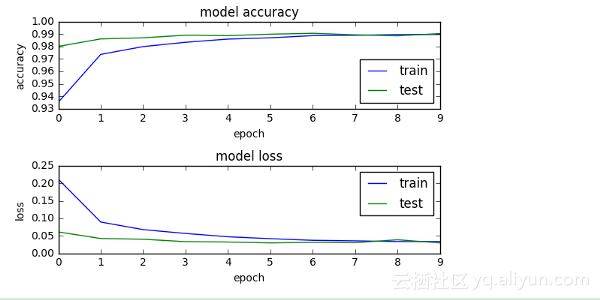
可以看到,測試準確性高達99%+,這也意味著該模型對于預測訓練得很好。對整個過程訓練和測試過程進行可視化,即畫出訓練和測試的準確曲線與損失函數曲線,如下所示。從圖中可以看到,隨著訓練迭代次數的增加,模型在訓練和測試數據上的損失和準確性趨于一致,模型最終趨于穩定。
模型訓練好后需要保存訓練好的參數,以便下次直接調用。模型的體系結構或結構將存儲在json文件中,權重將以hdf5文件格式存儲。
#Save the model# serialize model to JSONmodel_digit_json = model.to_json()with open("model_digit.json", "w") as json_file:
json_file.write(model_digit_json)# serialize weights to HDF5model.save_weights("model_digit.h6")
print("Saved model to disk")
因此,保存好的模型可以之后進行重復使用或輕易地遷移到其他應用場景中。
以上就是怎么使用Keras完成CNN模型搭建,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





