溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了如何進行深層神經網絡模型Softmax DNN分析,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
一種可能的DNN模型是softmax,它將問題看作多類預測問題,其中:
輸入是用戶查詢。
輸出是一個概率向量,其大小等于語料庫中的項目數,表示與每個項目交互的概率; 例如,點擊或觀看YouTube視頻的可能性。
DNN的輸入可包括:
密集特征(例如,觀看自上次觀看以來的時間和時間)
稀疏特征(例如,觀看歷史記錄和國家/地區)
與矩陣分解方法不同,還可以添加年齡或國家區域等側面特征。這里用x表示輸入向量。
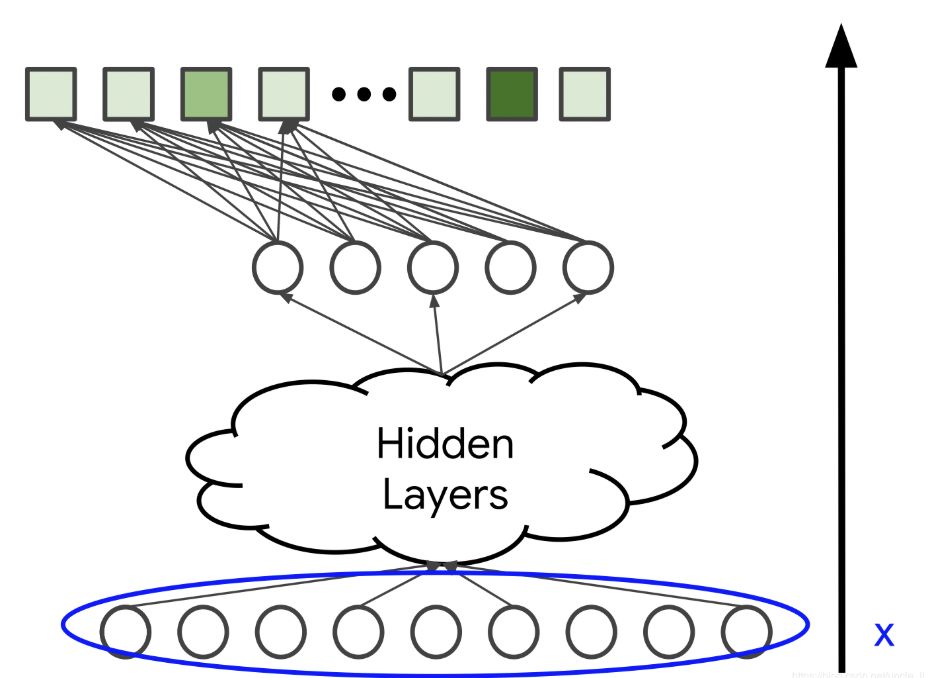
圖1.輸入層x
模型架構
模型架構決定了模型的復雜性和表現力。通過添加隱藏層和非線性激活函數(例如,ReLU),模型可以捕獲數據中更復雜的關系。然而,增加參數的數量通常也使得模型更難以訓練并且計算起來更復雜。最后一個隱藏層的輸出用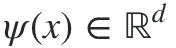 表示:
表示:
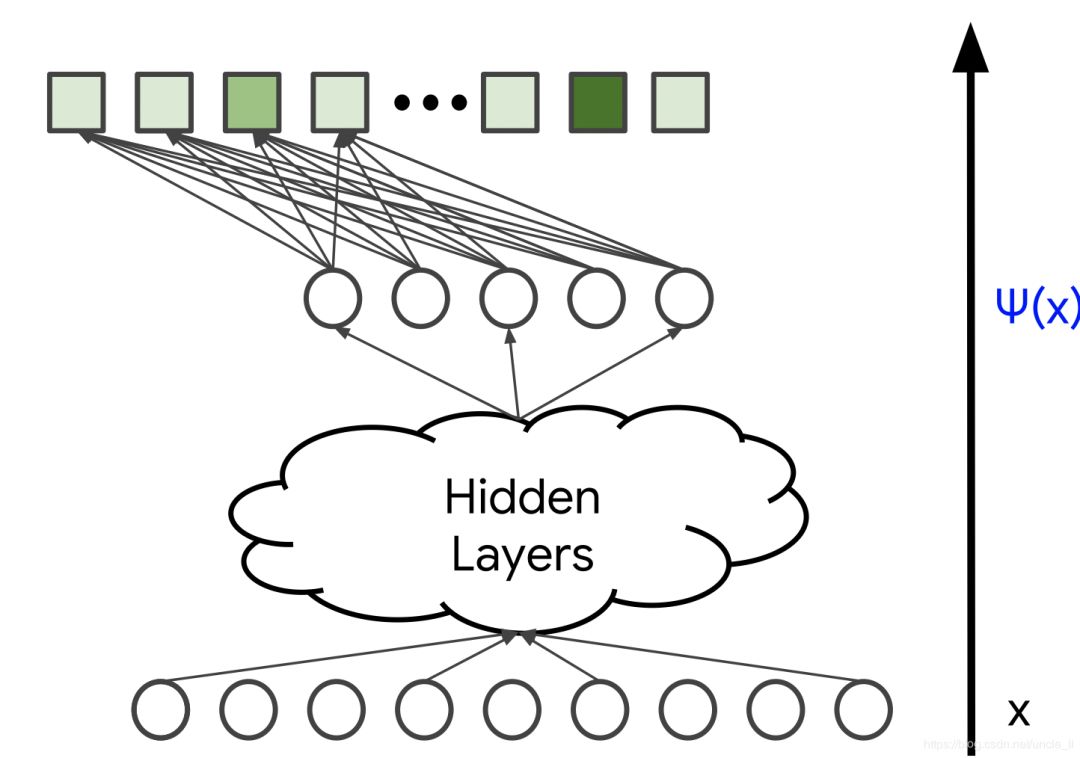
圖2.隱藏層的輸出, ψ(X)



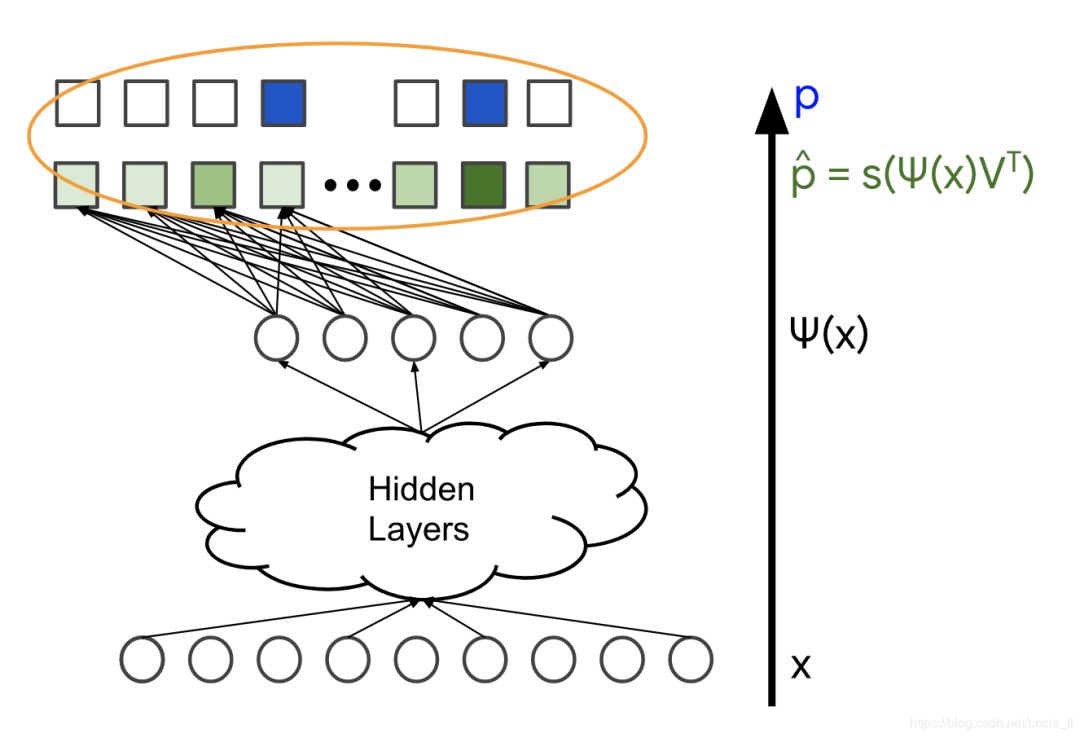
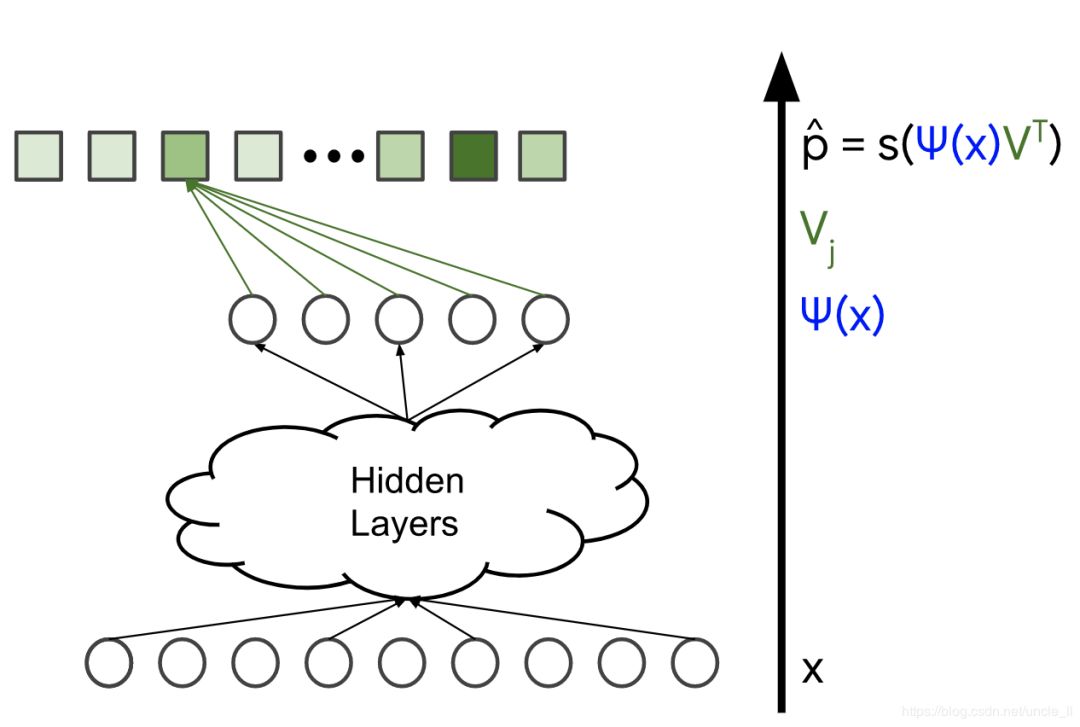
圖4.損失函數



上一節解釋了如何將softmax層合并到推薦系統的深度神經網絡中。本節將詳細介紹此系統的訓練數據。
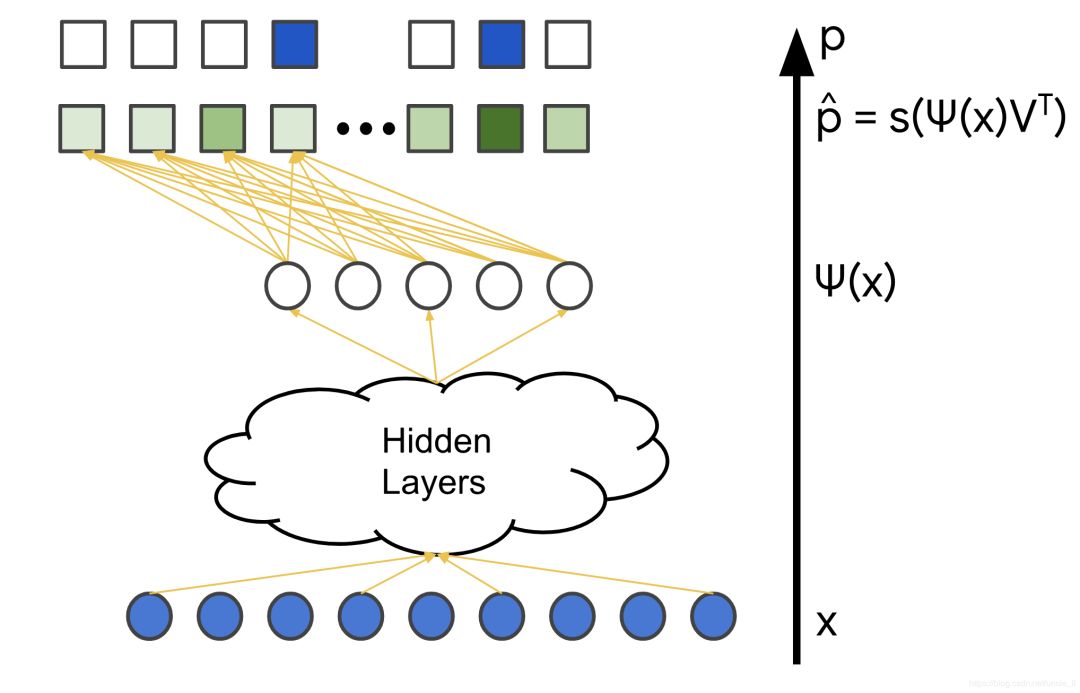
softmax訓練數據由查詢特征X以及用戶與之交互的項目向量(表示為概率分布 p)組成,在下圖中用藍色標記。模型的變量是不同層中的權重,在下圖中用橙色標記。通常使用隨機梯度下降或其變體方法來訓練模型。


DNN模型解決了矩陣分解的許多限制,但通常訓練和預測的代價更高。下表總結了兩種模型之間的一些重要差異。
| 矩陣分解 | Softmax DNN | |
|---|---|---|
| 查詢特征 | 不容易包括在內 | 可以包括在內 |
| 冷啟動 | 不容易處理詞典查詢或項目。可以使用一些啟發式方法(例如,對于新查詢,類似查詢的平均嵌入) | 容易處理新查詢 |
| 折頁 | 通過調整WALS中未觀察到的重量可以輕松減少折疊 | 容易折疊,需要使用負采樣或重力等技術 |
| 訓練可擴展性 | 可輕松擴展到非常大的語料庫(可能是數億項或更多),但僅限于輸入矩陣稀疏 | 難以擴展到非常大的語料庫,可以使用一些技術,例如散列,負采樣等。 |
| 提供可擴展性 | 嵌入U,V是靜態的,并且可以預先計算和存儲一組候選 | 項目嵌入V是靜態的并且可以存儲,查詢嵌入通常需要在查詢時計算,使得模型的服務成本更高 |
矩陣分解通常是大型語料庫的更好選擇。它更容易擴展,查詢計算量更便宜,并且不易折疊。
DNN模型可以更好地捕獲個性化偏好,但是難以訓練并且查詢成本更高。DNN模型比評分的矩陣分解更可取,因為DNN模型可以使用更多特征來更好地捕獲相關性。
上述內容就是如何進行深層神經網絡模型Softmax DNN分析,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





