溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行Algobase() 類的功能分析,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
AlgoBase() 類我們前面提到過,是所有算法的父類,那么 AlgoBase() 就應該把所有算法的共同的方法抽象出來。換句話說,AlgoBase() 中的方法,是所有子類都可能擁有的功能。
那么我們先看一下都有哪些函數,然后挑其中幾個比較重要的看一下代碼。
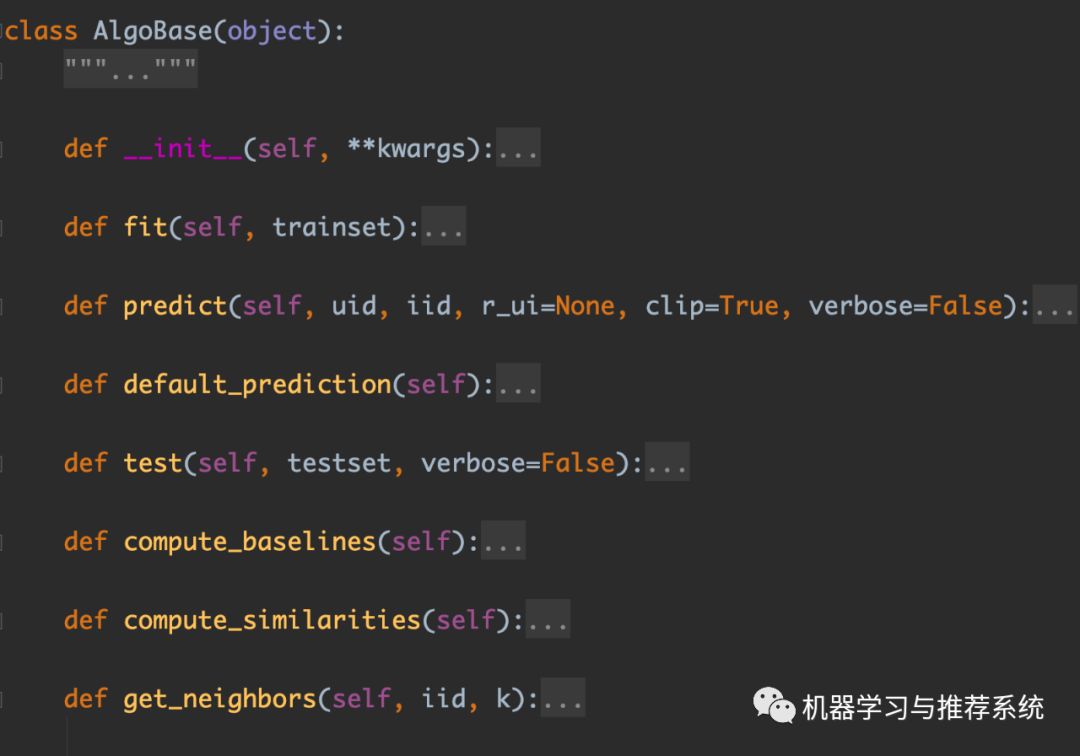
簡單的都介紹一下它們的功能。
fit() 我們在 KNN 的算法中看到,子類也重寫了這個函數,那么在父類中主要做了什么呢?父類中主要的作用是給 self 綁定上對應的 trainset,也就是對當前算法對象賦予一個 self.trainset 屬性。
def predict(self, uid, iid, r_ui=None, clip=True, verbose=False):# Convert raw ids to inner idstry:iuid = self.trainset.to_inner_uid(uid)except ValueError:iuid = 'UKN__' + str(uid)try:iiid = self.trainset.to_inner_iid(iid)except ValueError:iiid = 'UKN__' + str(iid)details = {}try:est = self.estimate(iuid, iiid)# If the details dict was also returnedif isinstance(est, tuple):est, details = estdetails['was_impossible'] = Falseexcept PredictionImpossible as e:est = self.default_prediction()details['was_impossible'] = Truedetails['reason'] = str(e)# clip estimate into [lower_bound, higher_bound]if clip:lower_bound, higher_bound = self.trainset.rating_scaleest = min(higher_bound, est)est = max(lower_bound, est)pred = Prediction(uid, iid, r_ui, est, details)if verbose:print(pred)return pred
代碼我們可以簡單的看為三部分,第一部分是兩個 try 的異常處理,將數據集中的 raw id 轉為處理過后的內部 ID。在前面數據集處理的時候,我們看了將所有 ID 轉化為一個內部的 inner ID。
第二部分是去調用該算法自己的 estimate() 函數,這個函數一般在對應算法的子類中寫了。不同的算法對應不同的 estimate() 方法。同時返回值有時候會包含一個 details 的內容,這個時候預測結果 est 就是一個包含了預測得分和 details 的元組,此處進行了拆分。如果預測失敗,則調用下一個函數:default_prediction(),我們馬上就介紹它。
第三部分是一個 clip() 的內容,就是判斷預測的結果是否超出范圍,進行一個規范化。
通過這三步完成了一個預測,最后返回一個用 Prediction() 進行預測的結果值.
當預測出現問題的時候,就會選擇調用 default_prediction(),這個函數調用 trainset 本身的 global_mean 方法,最終返回整個數據集的評分的平均值。
def test(self, testset, verbose=False): predictions = [self.predict(uid, iid, r_ui_trans, verbose=verbose) for (uid, iid, r_ui_trans) in testset] return predictions
test() 函數直接為 testset 中的每組數據去調用前面的 predict() 函數,返回一個 list 結果。
這部分會計算 user 和 items 的 baseline,只計算一次,如果在同一個數據集中已經被調用過了,下次則是直接返回結果,這里和算法之間的具體交互目前還沒有看到,后面我們遇到再詳細介紹。
這個方法構建一個相似性矩陣,在 AlgoBase() 類初始化的時候會有一個變量 sim_options,這個變量決定了以什么相似性來構建相似性矩陣。
在 surprise 中有一個 similarities.cpython-37m-darwin.so 文件,這個文件封裝了不同的相似性計算方法。
在 compute_similarities 中會利用這個文件構建的 similarities 包,最終返回一個目標的相似性矩陣。
這個方法傳入一個 user ID,傳入一個 int 值 k,返回結果為和這個 user 最相似的 k 個 user 的 ID。
AlgoBase() 基類構建了一些常用的方法,基本上包含了擬合,預測,驗證等功能接口,在具體的算法中會重寫這些方法,后者調用。
看完上述內容,你們掌握如何進行Algobase() 類的功能分析的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





