溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下python中pandas_profiling怎么用,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
分析報告全貌
?
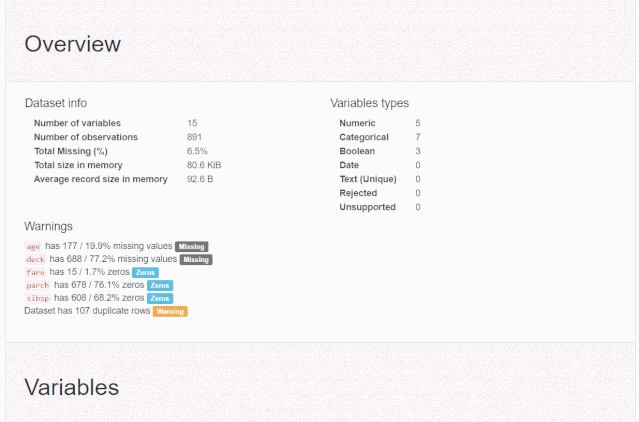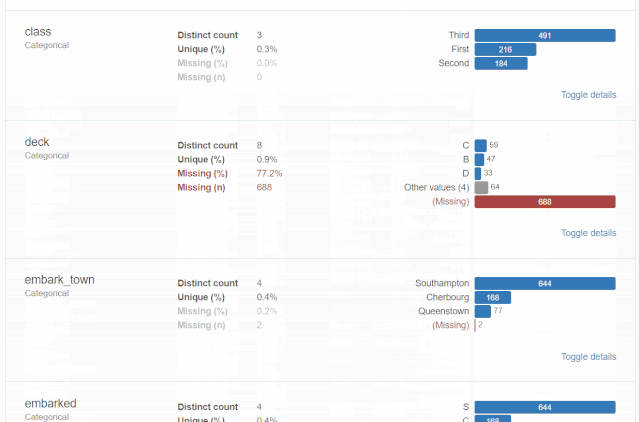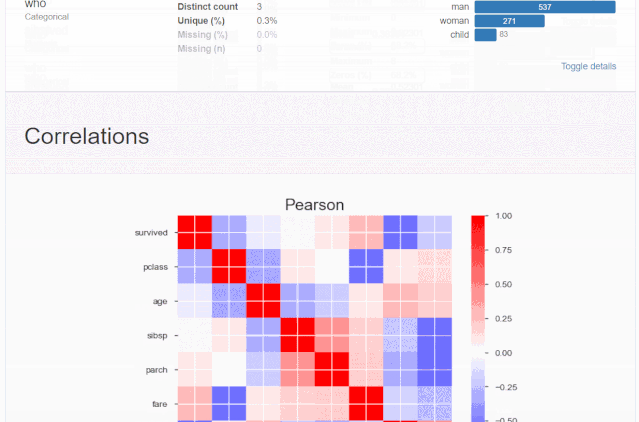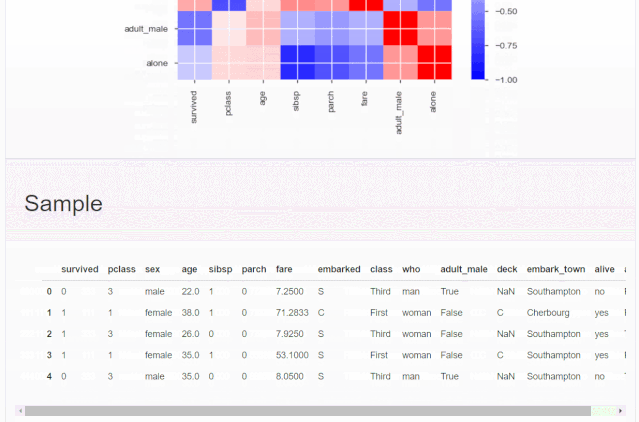
什么是探索性數據分析
熟悉pandas的童鞋估計都知道pandas的describe()和info()函數,用來查看數據的整體情況,比如平均值、標準差之類,就是所謂的探索性數據分析-EDA。
pandas_profiling簡介
如果你想更方便快捷地了解數據的全貌,泣血推薦一個python庫:pandas_profiling,這個庫只需要一行代碼就可以生成數據EDA報告。
pandas_profiling基于pandas的DataFrame數據類型,可以簡單快速地進行探索性數據分析。
對于數據集的每一列,pandas_profiling會提供以下統計信息:
1、概要:數據類型,唯一值,缺失值,內存大小
2、分位數統計:最小值、最大值、中位數、Q1、Q3、最大值,值域,四分位
3、描述性統計:均值、眾數、標準差、絕對中位差、變異系數、峰值、偏度系數
4、最頻繁出現的值,直方圖/柱狀圖
5、相關性分析可視化:突出強相關的變量,Spearman, Pearson矩陣相關性色階圖
并且這個報告可以導出為HTML,非常方便查看。
pandas_profiling安裝
安裝pandas_profiling可以使用pip、conda或者下載文件安裝,非常方便。
我這里使用pip方式,在命令行輸入:
pip install pandas-profiling
本文在Jupyter notebook中進行代碼實驗。
pandas_profiling使用方法
1、加載數據集
我這里用經典的泰坦尼克數據集:
# 導入相關庫import seaborn as snsimport pandas as pdimport pandas_profiling as ppimport matplotlib.pyplot as plt# 加載泰坦尼克數據集data = sns.load_dataset('titanic')data.head()
輸出:

2、使用pandas_profiling生成數據探索報告
report = pp.ProfileReport(data)report
輸出報告:
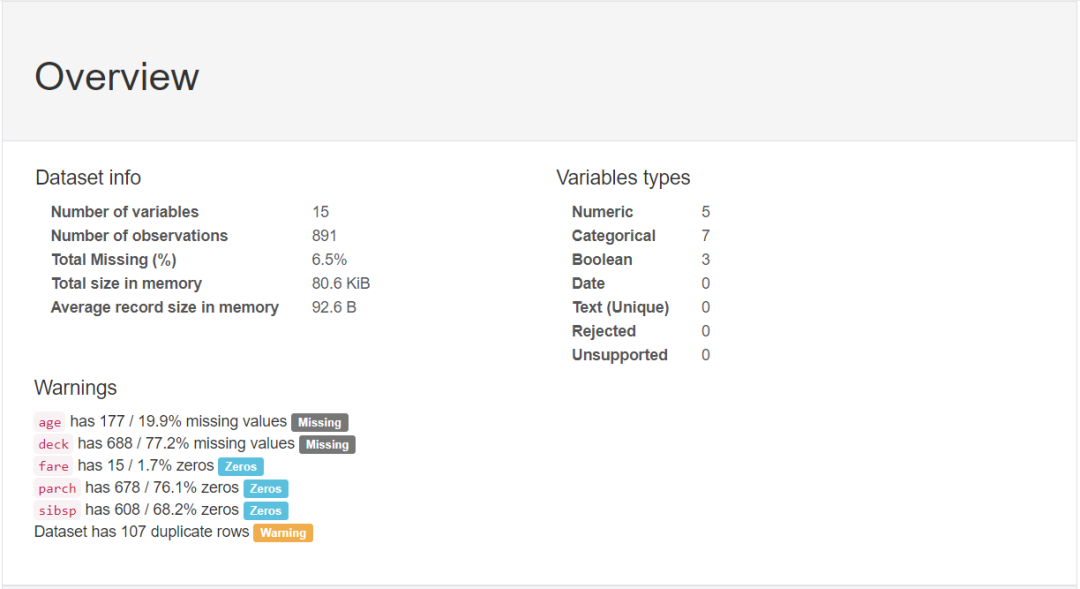
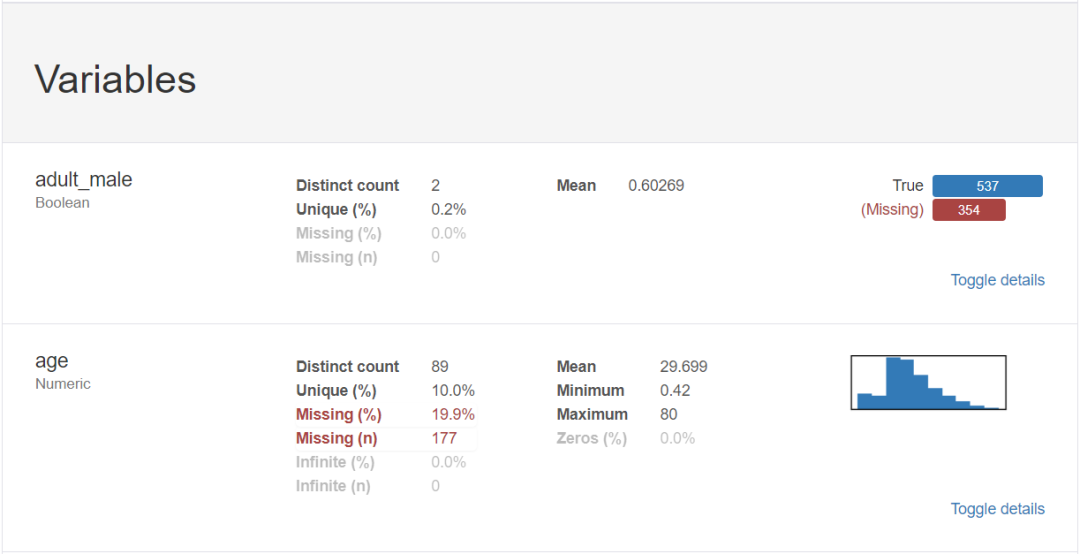
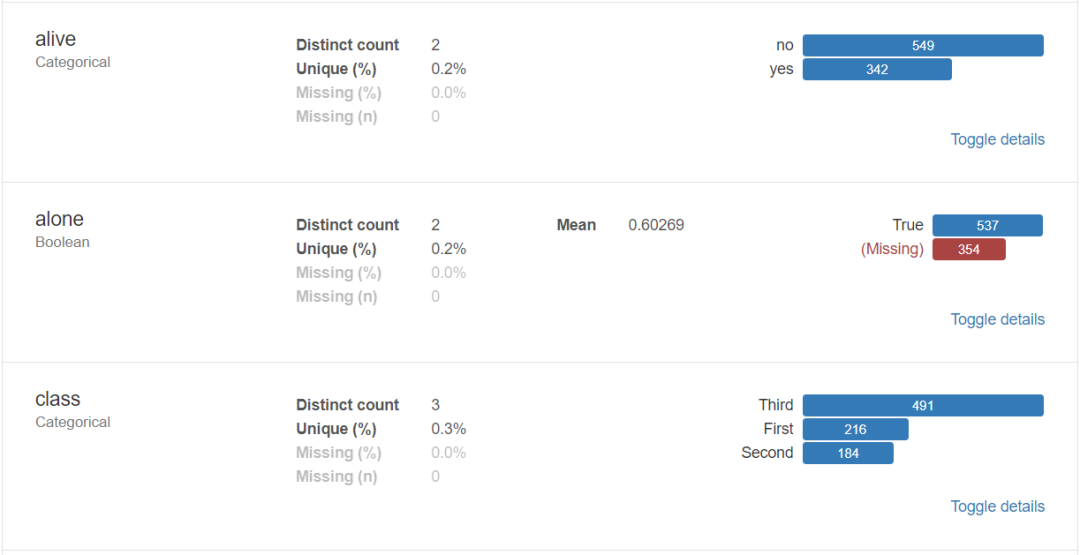
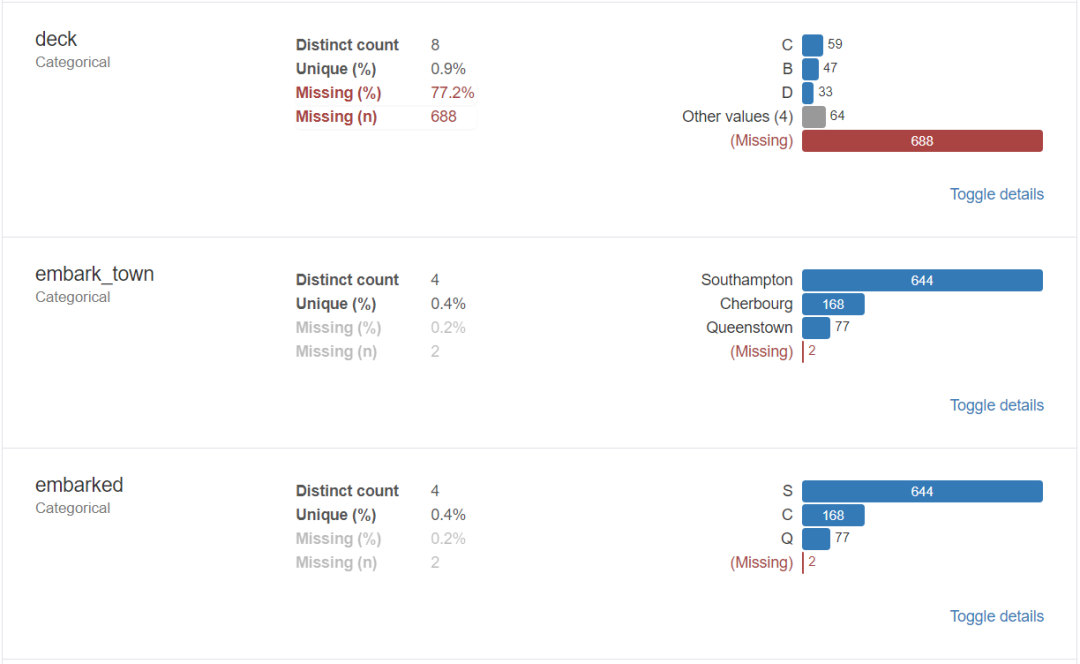
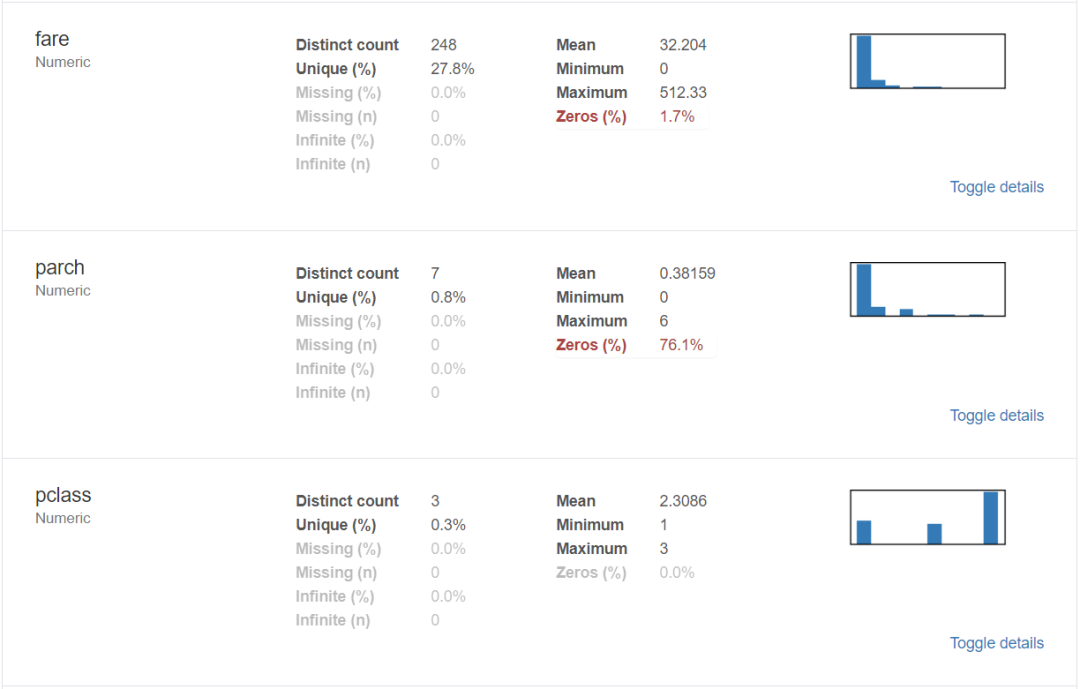
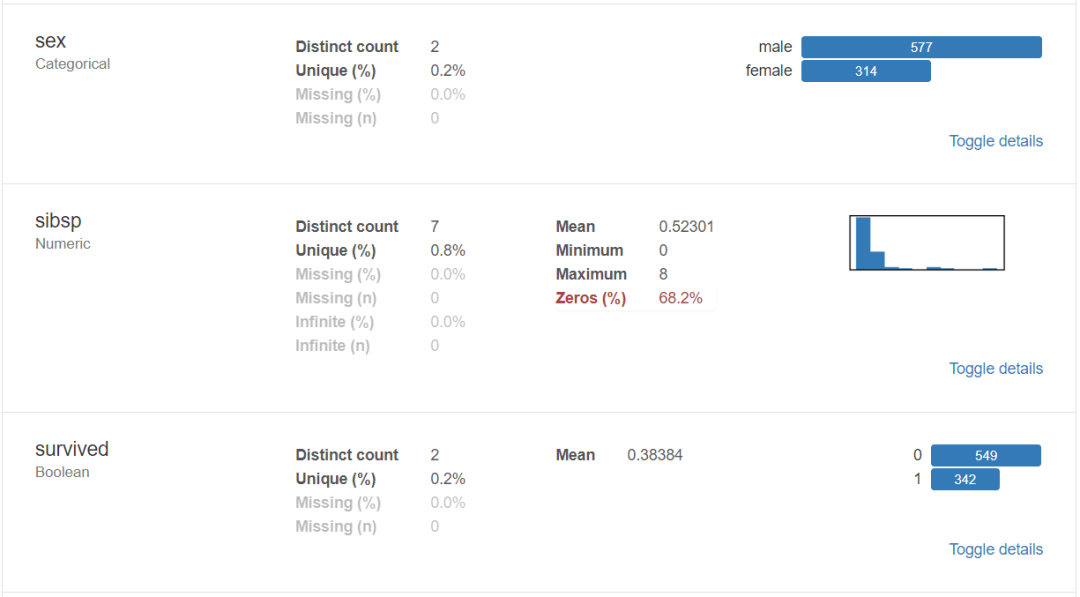


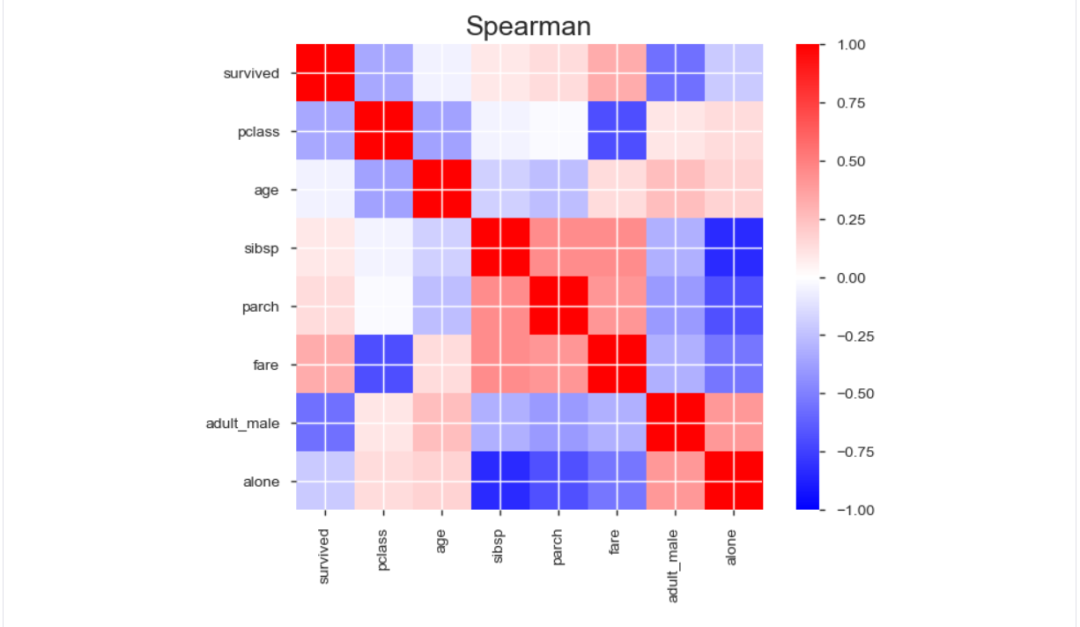
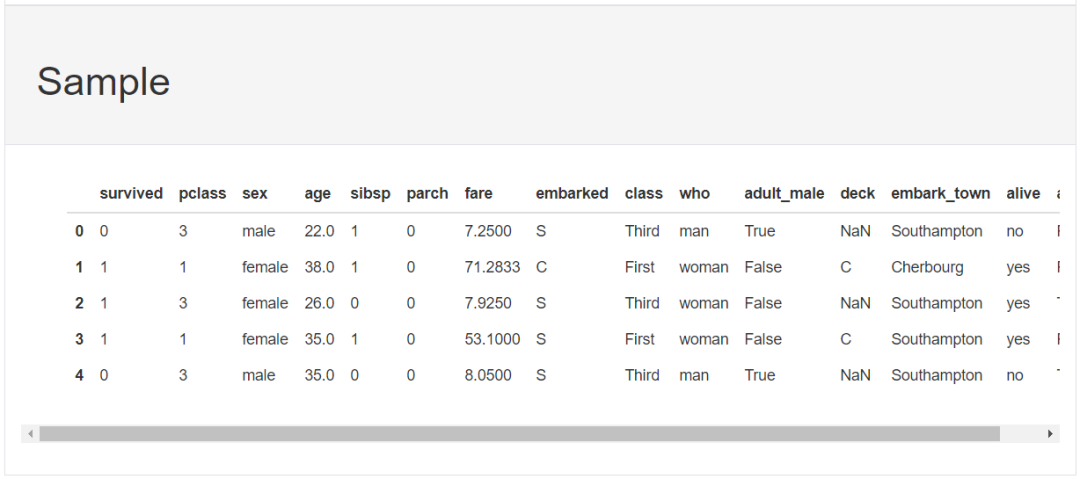
3、導出為html文件
report.to_file('report.html')
看完了這篇文章,相信你對“python中pandas_profiling怎么用”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





