溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了如何使用docker快速搭建Spark集群的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇如何使用docker快速搭建Spark集群文章都會有所收獲,下面我們一起來看看吧。
準備工作
安裝docker
(可選)下載java和spark with hadoop
spark集群
spark運行時架構圖
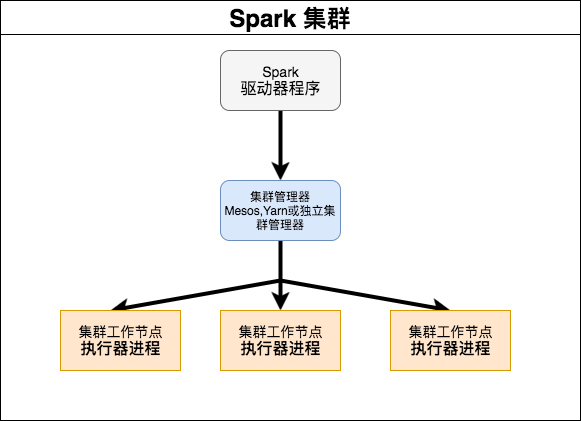
如上圖: spark集群由以下兩個部分組成
集群管理器(mesos, yarn或者standalone mode)
工作節點(worker)
如何docker化(本例使用standalone模式)
1、將spark集群拆分
base(基礎鏡像)
master(主節點鏡像)
worker(工作鏡像)
2、編寫base dockerfile
注: 為方便切換版本基礎鏡像選擇的是centos, 所以要下載java和spark, 方便調試, 可以下載好安裝文件后本地搭建一個靜態文件服務器, 使用node.js 的可以快速搞定
命令如下
npm install http-server -g http-server -p 54321 ~/downloads
正式開始寫dockerfile
from centos:7 maintainer ravenzz <raven.zhu@outlook.com> # 安裝系統工具 run yum update -y run yum upgrade -y run yum install -y byobu curl htop man unzip nano wget run yum clean all # 安裝 java env jdk_version 8u11 env jdk_build_version b12 # 如果網速快,可以直接從源站下載 #run curl -lo "http://download.oracle.com/otn-pub/java/jdk/$jdk_version-$jdk_build_version/jdk-$jdk_version-linux-x64.rpm" -h 'cookie: oraclelicense=accept-securebackup-cookie' && rpm -i jdk-$jdk_version-linux-x64.rpm; rm -f jdk-$jdk_version-linux-x64.rpm; run curl -lo "http://192.168.199.102:54321/jdk-8u11-linux-x64.rpm" && rpm -i jdk-$jdk_version-linux-x64.rpm; rm -f jdk-$jdk_version-linux-x64.rpm; env java_home /usr/java/default run yum remove curl; yum clean all workdir spark run \ curl -lo 'http://192.168.199.102:54321/spark-2.1.0-bin-hadoop2.7.tgz' && \ tar zxf spark-2.1.0-bin-hadoop2.7.tgz run rm -rf spark-2.1.0-bin-hadoop2.7.tgz run mv spark-2.1.0-bin-hadoop2.7/* ./ env spark_home /spark env path /spark/bin:$path env path /spark/sbin:$path
3、編寫master dockerfile
from ravenzz/spark-hadoop maintainer ravenzz <raven.zhu@outlook.com> copy master.sh / env spark_master_port 7077 env spark_master_webui_port 8080 env spark_master_log /spark/logs expose 8080 7077 6066 cmd ["/bin/bash","/master.sh"]
4、編寫worker dockerfile
from ravenzz/spark-hadoop maintainer ravenzz <raven.zhu@outlook.com> copy worker.sh / env spark_worker_webui_port 8081 env spark_worker_log /spark/logs env spark_master "spark://spark-master:32769" expose 8081 cmd ["/bin/bash","/worker.sh"]
5、docker-compose
version: '3' services: spark-master: build: context: ./master dockerfile: dockerfile ports: - "50001:6066" - "50002:7077" # spark_master_port - "50003:8080" # spark_master_webui_port expose: - 7077 spark-worker1: build: context: ./worker dockerfile: dockerfile ports: - "50004:8081" links: - spark-master environment: - spark_master=spark://spark-master:7077 spark-worker2: build: context: ./worker dockerfile: dockerfile ports: - "50005:8081" links: - spark-master environment: - spark_master=spark://spark-master:7077
6、測試集群
docker-compose up
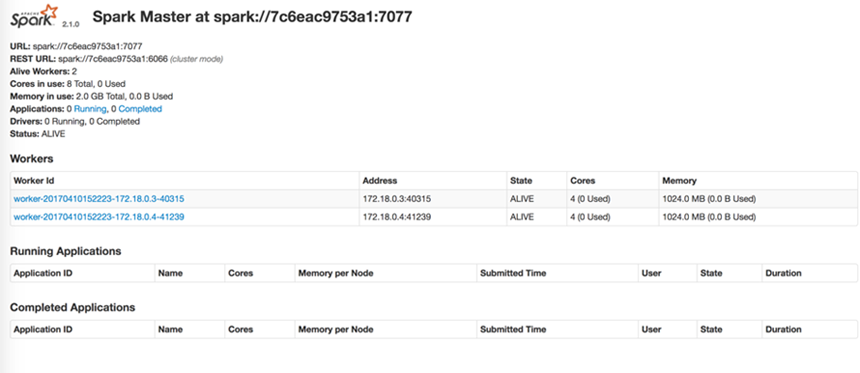
訪問http://localhost:50003/ 結果如圖
關于“如何使用docker快速搭建Spark集群”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“如何使用docker快速搭建Spark集群”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





