溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么用python采集網頁內容并整合成pdf文件”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
登陸網站:深規院(http://www.upr.cn/)。接下來跟大家一樣,我就挨個點擊了它的主頁。
主頁
很自然我就紅色4點進去看到了他們的內刊,有段時間我不太愛看文字,評職稱我對自己的論文不是很滿意,就點進去看看論文了解下最近的規劃學術動態也好。于是就有接下來的看圖。
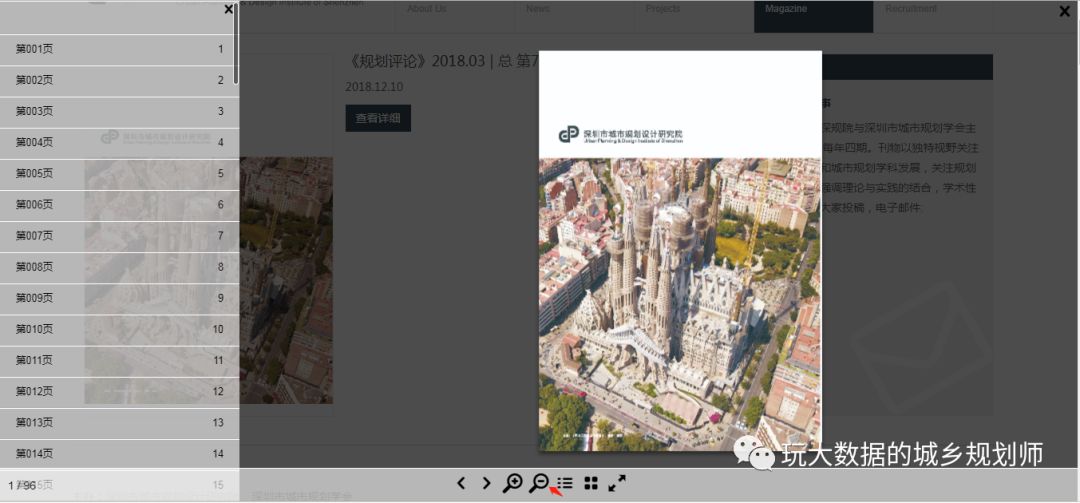
期刊瀏覽
在看的過程中,發現寶貝了,就是有一篇論文寫村莊污水集中跟分散處理的論文,我做過幾個村莊整治規劃,這方面我一直腦袋空白。

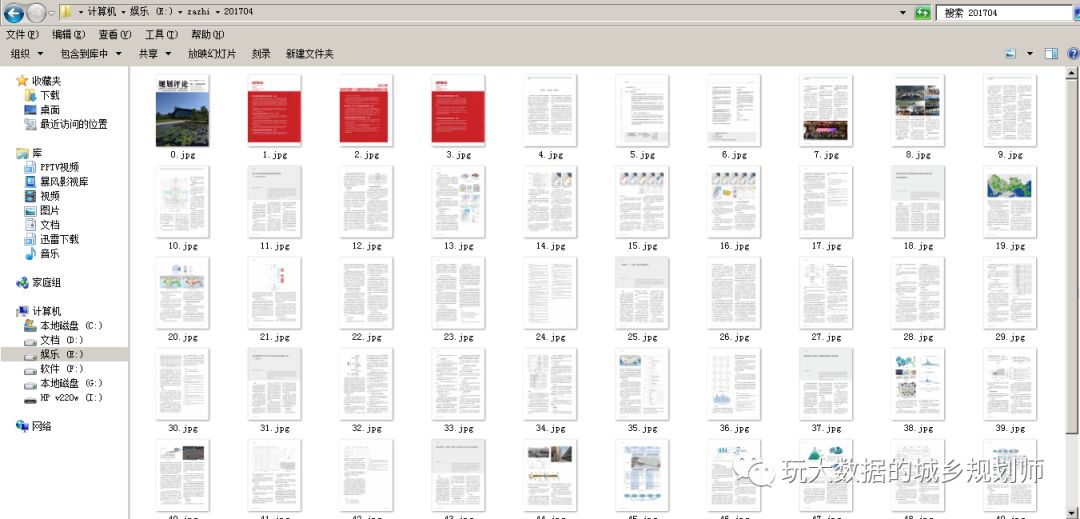
看到它即使再有文字障礙,我也要把他讀完。等一等,讀完以后還看呢!我去,最近在學爬蟲,干確給弄下來。那個什么送長輩,哦錯了,送同行看看也好。那就分析下唄。看看是什么格式。
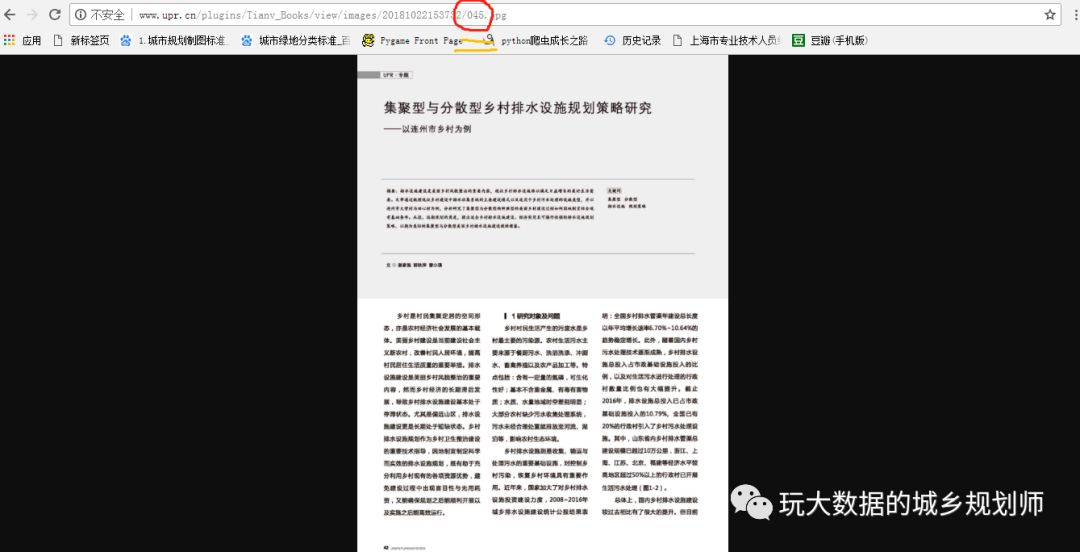
右鍵復制圖片地址得到
看到沒有,那個像書一樣翻來翻去的,頁面變化其實只有網址045在變化。奶思,循環采集圖片對于現在的我來說簡直是小兒科。用pycharm寫幾行代碼搞定一下。
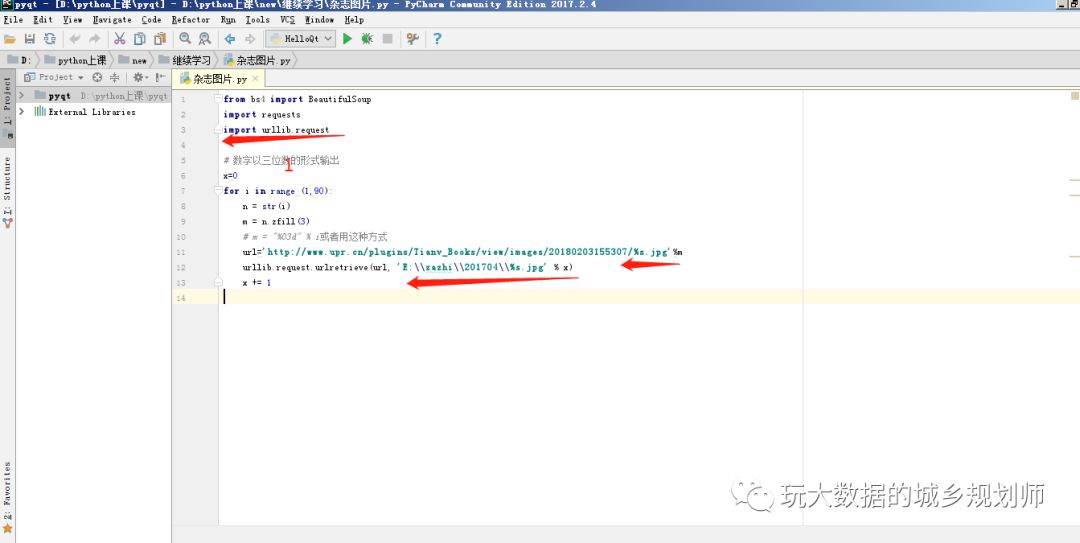
三點注意一下就好:1,導入urllib模塊;2,循環變化url;3,設置好保存路徑跟保存圖片的文件名。接下來就運行py文件唄,要不是我住的地用的移動送的爛網絡。總之,如下:
“怎么用python采集網頁內容并整合成pdf文件”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





