溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Spark2.2.0中Spark系統架構及任務提交流程是怎樣的,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
在講解Spark系統架構之前,先給大家普及一些比較重要的概念 :
| 術語 | 描述 |
| Application | Spark的應用程序,包含一個Driver、多個Executor |
| SparkContxt | spark應用程序入口,負責調度運算資源,協調worker上的executor |
| Driver程序 | 運行sark應用程序的main函數,并創建sparkContext |
| Executor | 運行在Worker上的一個進行,負責運行Task |
| Worker | 集群中的計算節點,運行一個或多個Executor |
| Task | Worker中的一個線程,Executor中的計算單元 |
| Job | SparkContext提交的Action操作,有幾個action就會有幾個Job,應用程序會有一個、多個job |
| Stage | 每個Job都會劃分為多個stage執行,也稱TaskSet |
| RDD | spark的核心,分布式彈性數據集 |
| DAGScheduler | 根據Job構建基于stage的DAG,并發送TaskScheduler執行 |
| TaskScheduler | 提交Taskset給Woker進行執行,并返回執行結果 |
| Transformations | RDD一種轉換類型,返回值還是一個RDD,具有懶加載屬性,如果程序全是Transformation,沒有Action程序是不會執行的。 |
| Actions | RDD一種轉換類型,返回值也是一個RDD,程序只有Action操作才會被觸發。 |
Spark部署模式:
這里簡單說一下,詳細部署請自行百度,這個網上資料很多也很全,我這里不在說了:
運行
運行 | 模式 | 描述 |
local | 本地模式 | 常用于本地開發測試,本地還分為local和local-cluster |
standalone | 集群模式 | 典型的Master/Slave模式,Master存在單點故障的,Spark支持Zookeeper來實現HA |
On Yarn | 集群模式 | 運行在Yarn資源管理器框架上,由Yarn負責資源管理,Spark負責任務調度和計算 |
On Mesos | 集群模式 | 運行在 mesos資源管理器框架上,由mesos負責資源管理,Spark負責任務調度和計算 |
On cloud | 集群模式 | 比如AWS的EMR,使用這個模式能很方便地訪問Amazon的S3;Spark支持多種分布式存儲系統,hdfs,S3,hbase等 |
Spark是一個基于內存的分布式并行處理框架,有幾個關鍵字:分布式、基于內存、并行處理,因此學習它要學習它的分布式架構以及它實現高速并行計算的機理,下面是spark的任務執行架構圖,整體劃分為以下幾部分:
一、Client客戶端:負責任務的提交,執行提交命令,指定任務MainClass、資源需求、參數配置等;在yarn/standalone-client模式下,客戶端提交程序后,Client新建一個Driver程序,這個client的作用持續到spark程序運行完畢,而yarn/standalone-cluster模式下,客戶端提交程序后就不再發揮任何作用,也就是說僅僅發揮了提交程序包的作用。
二、Driver:主要是對SparkContext進行配置、初始化以及關閉。初始化SparkContext是為了構建Spark應用程序的運行環境,在初始化SparkContext,要先導入一些Spark的類和隱式轉換;在Executor部分運行完畢后,需要將SparkContext關閉。
三、ClusterManager:負責接收任務的請求,分配計算資源、完成資源調度,一般采用FIFO策略;Driver向ClusterManager提交資源申請,ClusterManager結合任務資源需求和自身資源可用量,從Worker分配資源,并負責告知Driver資源分配結果,Driver接收到ClusterManager響應后發送Task到Worker執行,Worker通過心跳機制向ClusterManager匯報自己的資源和運行情況。
四、Executor:運行在worker節點上的一個進程,該進程負責運行某些Task, 并且負責將數據存到內存或磁盤上,每個Application都有各自獨立的一批Executor,在Spark on Yarn模式下,其進程名稱為CoarseGrainedExecutor Backend。一個CoarseGrainedExecutor Backend有且僅有一個Executor對象, 負責將Task包裝成taskRunner,并從線程池中抽取一個空閑線程運行Task, 這個每一個CoarseGrainedExecutor Backend能并行運行Task的數量取決于分配給它的cpu個數。
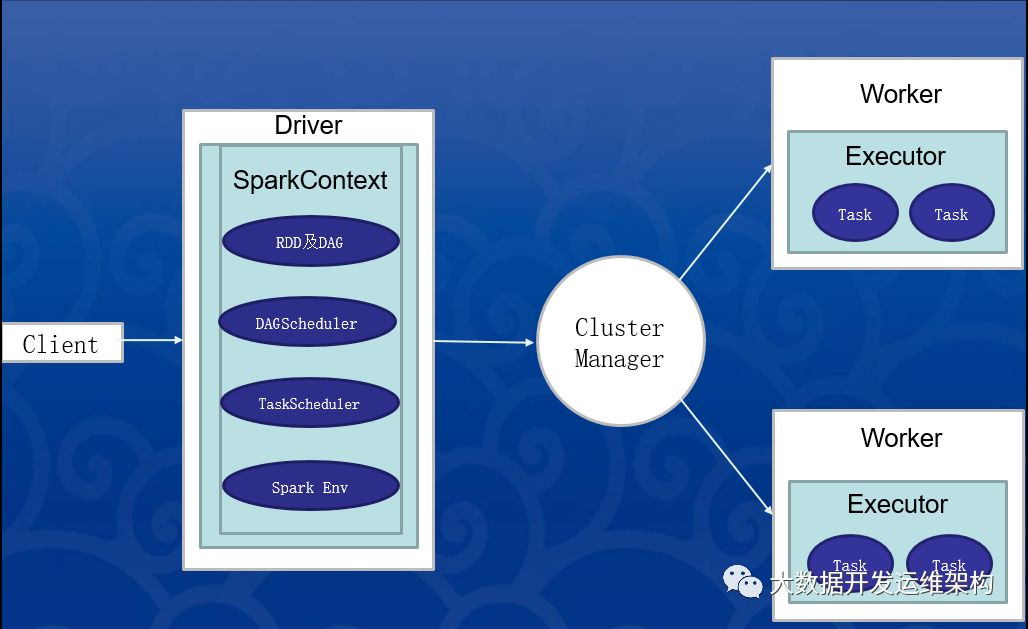
任務提交流程(這里以yarn-cluster模式講解):
1.客戶端一般通過spark-submit方式提交作業到Yarn集群,直接去找的是ResourceManager(RM),然后RM分配一個Worker創建Appmaster,由AppMaster去啟動Driver;
2.在Driver中運行我們提交的main函數,創建SparkContext,根據我們的Spark代碼,并生成RDD的邏輯執行計劃DAG,SparkContext會生成生成一批批的task,然后等待發送的Worker去執行;
3.AppMaster去向RM申請資源,RM會啟動一批Executor,這些Executor會一直存在,等待Task任務到來,執行Task,直到整個任務結束,Executor的數量在整個任務執行過程中是一直不變的;最后RM將資源分配信息發送給Driver端;
4. Driver收到RM的響應后,將任務的jar發送到對應的Executor上去執行,這里執行順序是按照RDD的DAG一批批的去執行對應的Task;在同一Stage每個Task執行相同的代碼,但是處理的數據是不同的(這也是RDD中分布式的特性);
注意:
上面任務提交流程是yarn-cluster模式,這里再強調一次,1.standalone/yarn-client模式:Driver運行在Client;
2.standalone/yarn-cluster模式:Driver是運行在集群的一個Worker上。
相關知識:
Spark的核心組件:包括RDD、Scheduler、Storage、Shuffle四部分:
1.RDD是Spark最核心最精髓的部分,spark將所有數據都抽象成RDD。
2.Scheduler是Spark的調度機制,分為DAGScheduler和TaskScheduler。
3.Storage模塊主要管理緩存后的RDD、shuffle中間結果數據和broadcast數據。
4.Shuffle分為Hash方式和Sort方式,兩種方式的shuffle中間數據都寫本地磁盤。
以上就是Spark2.2.0中Spark系統架構及任務提交流程是怎樣的,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





