溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python爬蟲怎么實現下載網易云音樂”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“Python爬蟲怎么實現下載網易云音樂”文章能幫助大家解決問題。
Selenium(配置方法參照:Selenium配置)
Chrome瀏覽器(其它的也可以,需要進行相應的修改)
解析
以前抓取過網易云網頁的朋友可能都清楚網易云有反爬蟲策略的,post時要對部分信息的參數完成加密函數的模擬。為了方便,入門新手也可以了解,直接采用Selenium來模擬登錄,之后用接口來下載音樂和歌詞。
實驗步驟:
通過歌手id得到當前歌手的熱門歌曲信息,歌名與網址,并且存儲到CSV文件里面;
載入csv文件,通過音樂鏈接,獲取歌曲ID,之后借助相應的接口,下載歌曲和歌詞;
將歌曲和歌詞存儲到本地。
Python實現
這里針對幾個主要的函數來說明…
抓取歌手信息
通過Selenium就不用看對頁面的請求了,能直接從頁面源代碼中提取對應的數據,查看歌手網頁源代碼能夠看到在iframe框架里有我們需要的信息,因此,要先切換到iframe:
browser.switch_to.frame('contentFrame')
接著看下去,在id=”hotsong-list”標簽中能看到需要的歌名以及鏈接,然后每一行對應的是一個tr標簽。因此先取得全部的tr內容,然后遍歷單個tr。
data = browser.find_element_by_id("hotsong-list").find_elements_by_tag_name("tr")
注意:前一個是find_element,后一個是find_elements,后者返回一個列表。
然后就是解析單個tr標簽的內容,得到歌名與鏈接,可以發現兩者在class=”txt”標簽中,而且鏈接是href屬性,名字是title屬性,能直接通過get_attribute()函數獲取。
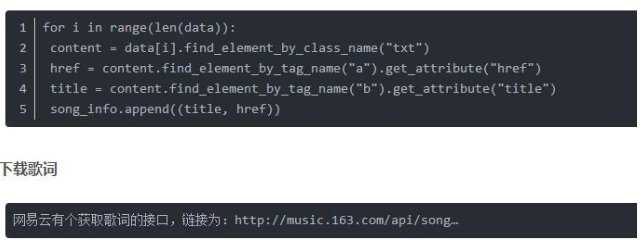
鏈接中的數字就是歌曲的id,因此我們得到歌曲id后,能夠同時從該鏈接下載歌詞,歌詞文件是json格式,因此我們還要用到json包。
并且同時獲取的歌詞中,每行有一個時間軸,還要用正則表達式來去除,完整代碼如下:

鏈接中的數字為歌曲的id,可以直接根據歌曲的id來下載音頻文件。完整代碼如下:
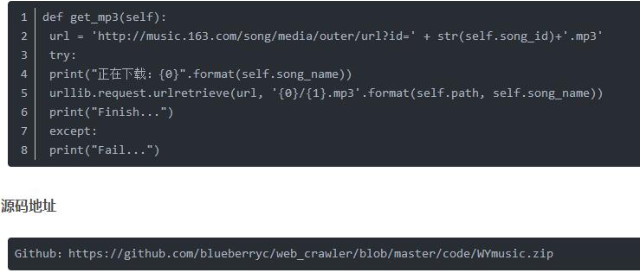
關于“Python爬蟲怎么實現下載網易云音樂”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





