溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關爬蟲中正則表達式怎么用的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
1、正則表達式:學會正則表達式的常用符號
2、re模塊:學會python中re模塊的使用方法
3、Requests和re模塊的組合應用:案例說明
正則表達式:
一般字符:

預定義字符:
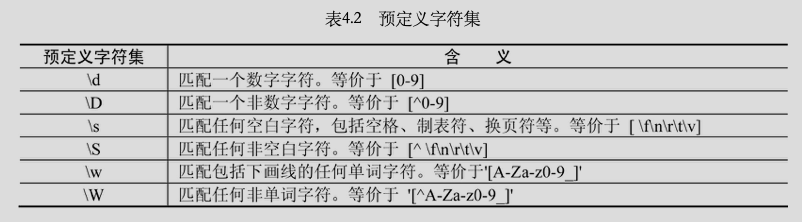
數量詞:
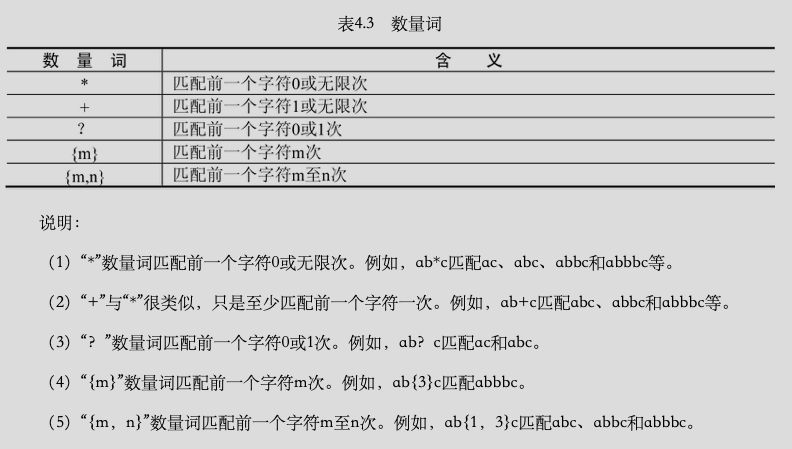
邊界匹配:

(.?)括號內容返回結果,.?匹配任意字符
import re
a = 'xxIxxmexxlovexxsffaxxpythonxx'
infos = re.findall('xx(.*?)xx',a)
print(infos)
輸出結果:I,love, python
re模塊及其方法
search()函數:匹配并提取第一個符合規律的內容,返回一個正則表達式對象
re.match(pattern,string,flags=0)
其中:
(1)pattern為匹配的正則表達式
(2)string為要匹配的字符串
(3)flags為標志位,用于控制正則表達式的匹配方式,如是否區分大小寫,多行匹配等
import re
a='one1two2three3'
infos=re.search('\d+',a)
print(infos)
輸出:<re.Match object; span=(3, 4), match='1'>
import re
a='one1two2three3'
infos=re.search('\d+',a)
print(infos.group())
輸出:1
sub()函數:用于替換字符串中的匹配項
re.sub(pattern,repl,string,count=0,flags=0)
其中:
(1)pattern為匹配的正則表達式
(2)repl為替換的字符串
(3)string為要被查找替換的原始字符串
(4)counts為模式匹配后替換的最大次數,默認0表示替換所有的匹配
(5)flags為標志位,用于控制正則表達式的匹配方式,如是否區分大小寫,多行匹配等
import re
phone='123-456-789'
new_phone=re.sub('\D','',phone)
print(new_phone)
輸出:123456789
findall()函數:匹配所有符合規律的內容,并以列表的形式返回結果。
import re
a='one1two2three3'
infos2=re.findall('\d+',a)
print(infos2)
輸出:['1', '2', '3']

import re
a ='''<div>指數
</div>'''
word = re.findall('<div>(.*?)</div>', a, re.S)
print(word[0].strip())
輸出:指數
感謝各位的閱讀!關于“爬蟲中正則表達式怎么用”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





