溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹MATLAB如何提取復雜文本中的數據,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
其實也不能算是復雜文本,還是有規律的。這個文本裝的是我實驗室設備采集到的數據,如下:
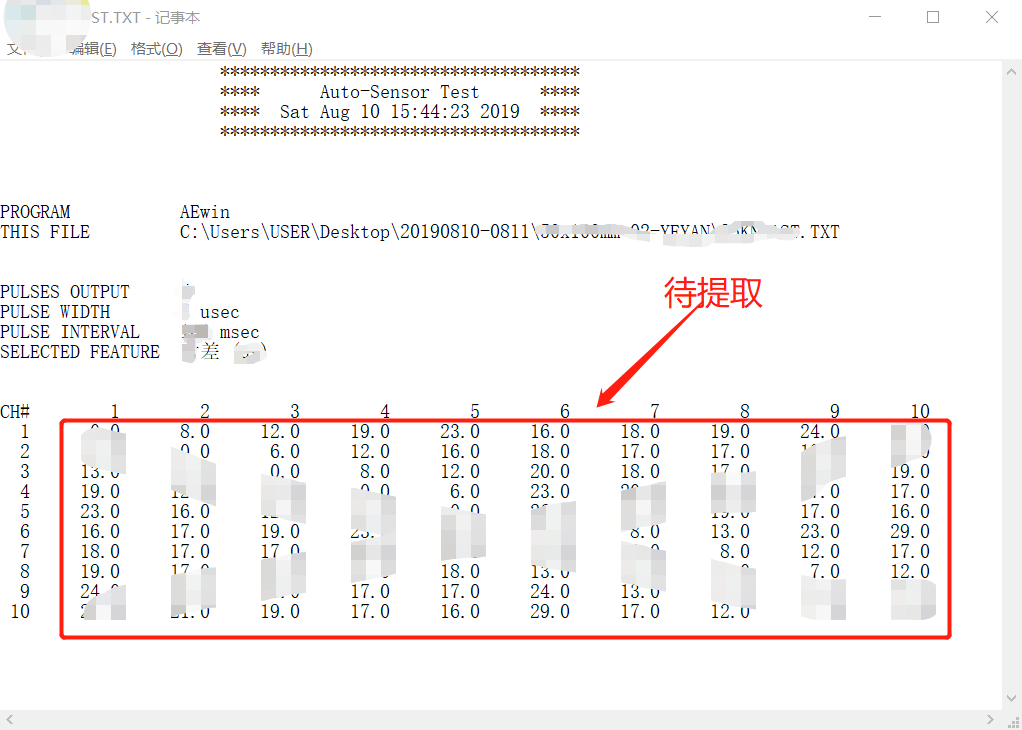
數據被我碼掉了一部分,我需要提取出框住的那部分數據,這是一個矩陣,他上邊的列號和左邊的行號都是傳感器的序號。
讀取數據的簡單思路:
通過觀察可以發現,我們想要獲取的數據都是在CH#開頭的行的后面,而且這個行的后面都是數值!所以這就很簡單了:
我們用一個while循環,把到達文件尾作為結束條件,
每次循環中判斷一下是否已經走過了CH#開頭的行,
如果沒走過CH#開頭的行就繼續,
如果走過了CH#開頭的行就開始讀數。
下面直接上代碼,再做一些簡單的說明
clc
clear
%% 文件打開對話框,選擇文件
[file, path] = uigetfile({'*.TXT'}, '選擇走時文件');
% 如果沒有選擇文件就退出
if file == 0
return
end
% 文件完整路徑
fullPath = [path, file];
%% 打開文件
fid = fopen(fullPath, 'r');
%% 保存結果的矩陣
ElapsTimeData = [];
%% 標志開始模式為'^CH#',開始標志的初值為0
startParten = '^CH#';
startFlag = 0;
%% 循環讀取文件
while(~feof(fid))
% 一次循環讀取一行,并把兩邊的空白去掉
curLine = strip(fgetl(fid));
% 如果開始標志已經被設置為1,而且不是空行,則讀取
if startFlag == 1 && ~isempty(curLine)
cur_data = cellfun(@str2double, regexpi(strip(curLine), '\s+', 'split'));
ElapsTimeData = [ElapsTimeData; cur_data];
end
% 當碰到startParten時,其下一行開始就是走時數據了
if regexpi(curLine, startParten)
startFlag = 1;
end
end
% 刪除第一列,第一列放的是傳感器序號
ElapsTimeData(:, 1) = [];
關于regexpi函數它接受三個參數:
第一個是原字符串,
第二個是我們要匹配的模式,
第三個參數是正則表達式輸出規則。
上面程序中,加粗黑體的那句
regexpi(strip(curLine), '\s+', 'split')
源字符串就是當前行
匹配模式:\s+表示一個或以上的空格(空白)
輸出規則:我采用的是split,表示:返回除匹配字符串之外的所有字符串!
所以,我這里將輸出除空白以外的所有字符,而這個匹配是在匹配到'^CH#'之后才開始的,所以我們便能獲得'^CH#'所在行的后面所有行中的數字了。
如果第三個參數使用match的話,則像下面這樣寫也行,就是匹配模式稍微多了點東西!
regexpi(strip(curLine), '\d+\.\d+', 'match')
另外regexpi返回的是一個細胞數組,每一個匹配到的結果都放在了單個細胞中。所以我這里用的cellfun把每一個細胞中的字符轉化為數值:
cur_data = cellfun(@str2double, regexpi(strip(curLine), '\s+', 'split'));
Note:
上面給的代碼中我刪減了處理錯誤的代碼,比如說:不符合上面規則的文件,或者我們不小心把要提取的部分刪了點數據,等等。
這些可以用 try - catch 結構來處理,我就不多說了,感興趣的可以自己試試看,實際在提取數據時,最好加上這些處理錯誤情況的代碼。
讀取結果:

也碼掉一部分數據
以上是“MATLAB如何提取復雜文本中的數據”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





