溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關在flink中如何進行keyby窗口數據傾斜的優化,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
在大數據處理領域,數據傾斜是一個非常常見的問題,我們就簡單講講在flink中如何處理流式數據傾斜問題。
我們先來看一個可能產生數據傾斜的sql.
select TUMBLE_END(proc_time, INTERVAL '1' MINUTE) as winEnd,plat,count(*) as pv from source_kafka_table
group by TUMBLE(proc_time, INTERVAL '1' MINUTE) ,plat
在這個sql里,我們統計一個網站各個端的每分鐘的pv,從kafka消費過來的數據首先會按照端進行分組,然后執行聚合函數count來進行pv的計算。如果某一個端產生的數據特別大,比如我們的微信小程序端產生數據遠遠大于其他app端的數據,那么把這些數據分組到某一個算子之后,由于這個算子的處理速度跟不上,就會產生數據傾斜。
查看flink的ui,會看到如下的場景。
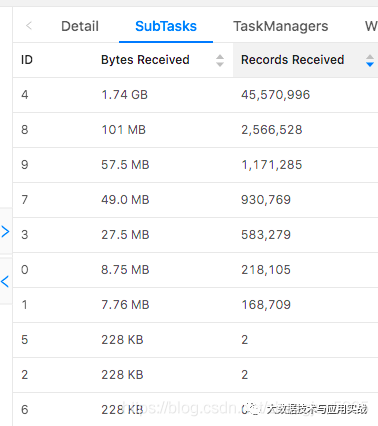
對于這種簡單的數據傾斜,我們可以通過對分組的key加上隨機數,再次打散,分別計算打散后不同的分組的pv數,然后在最外層再包一層,把打散的數據再次聚合,這樣就解決了數據傾斜的問題。
優化后的sql如下:
select winEnd,split_index(plat1,'_',0) as plat2,sum(pv) from (
select TUMBLE_END(proc_time, INTERVAL '1' MINUTE) as winEnd,plat1,count(*) as pv from (
-- 最內層,將分組的key,也就是plat加上一個隨機數打散
select plat || '_' || cast(cast(RAND()*100 as int) as string) as plat1 ,proc_time from source_kafka_table
) group by TUMBLE(proc_time, INTERVAL '1' MINUTE), plat1
) group by winEnd,split_index(plat1,'_',0)
在這個sql的最內層,將分組的key,也就是plat加上一個隨機數打散,然后求打散后的各個分組(也就是sql中的plat1)的pv值,然后最外層,將各個打散的pv求和。
注意:最內層的sql,給分組的key添加的隨機數,范圍不能太大,也不能太小,太大的話,分的組太多,增加checkpoint的壓力,太小的話,起不到打散的作用。在我的測試中,一天大概十幾億的數據量,5個并行度,隨機數的范圍在100范圍內,就可以正常處理了。
修改后我們看到各個子任務的數據基本均勻了。
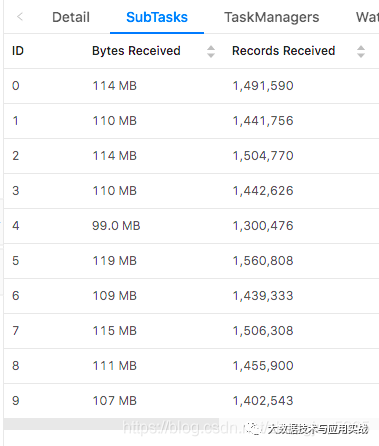
看完上述內容,你們對在flink中如何進行keyby窗口數據傾斜的優化有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





