溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“基于Libra的卷積神經網絡怎么實現”,在日常操作中,相信很多人在基于Libra的卷積神經網絡怎么實現問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”基于Libra的卷積神經網絡怎么實現”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
我使用了Kaggle數據集來預測信用卡欺詐。數據已經經過主成分分析,因此與原始數據相比,它現在被簡化為更小維的數據。
在解決這個問題時,需要遵循一種系統的方法。一般來說,你將遵循第一段中提到的順序。但有了Libra,你就不用擔心了。
此數據中的大多數交易在時間上是非欺詐性的(99.83%),而欺詐性交易在數據集中發生的時間(0.17%)。這意味著數據是高度不平衡的。讓我們看看Libra對數據的預處理和結果。
pip install -U libra
from libra import client
一切都是圍繞client構建的。你可以對它調用不同的查詢,所有的內容都將存儲在對象的models字段下。
我們在client對象中傳遞文件的位置,并將其命名為newClient。現在要訪問各種查詢,請參閱文檔。
我用的是決策樹。例如,預測房屋價值中位數,或估計住戶數量。否則,該代碼應與數據集中的列相對應。Libra會自動檢測到目標列,但為了確保它選擇了正確的列,我已經傳遞了目標列的名稱。
newClient = client('creditcard.csv')
newClient.decision_tree_query('Class')
只需兩行代碼,我們就得到了大約0.99的分數,這是我們能得到的最好成績。如果你檢查其他人的成功,你會發現只有少數人獲得了0.99的準確率,他們花了數小時來預處理數據并為其編寫代碼。
在這種情況下,Libra為你節省了很多時間,給你最好的結果。Libra使用智能預處理,這樣你就不需要自己去預處理數據了。
newClient.analyze()為所有分類問題創建混淆矩陣和ROC曲線。它還計算召回率,精確度,f1和f2分數。
newClient.analyze()
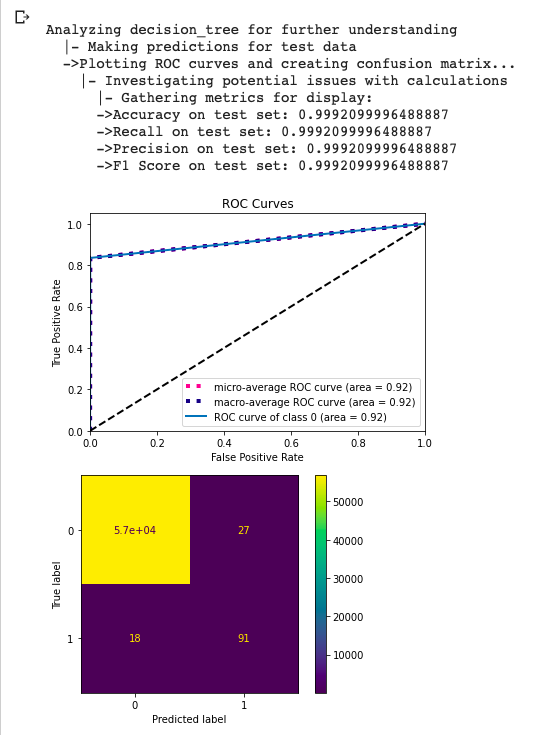
newClient.info()返回所有鍵,表示為數據集生成的每種數據類別。
newClient.info()

newClient.model() 返回該模型的字典。它包括從準確度,精確度,召回率,F1分數到所有的預處理技術。對于那些已經了解這些概念并能夠編寫代碼的人來說,這會更有幫助。非技術用戶不必為此擔心。
newClient.model()

newClient.model()返回字典,如果要訪問模型,則可以直接使用newClient.model()['model']
newClient.model()['model']

在colab Notebook使用下面的代碼下載石頭剪刀布數據集。我本可以直接向你展示使用Libra創建CNN的代碼,但是我想創建一個例子,你可以自己在colab Notebook中嘗試,以便更好地理解。你不需要擔心下面的代碼。
!wget --no-check-certificate \ https://storage.googleapis.com/laurencemoroney-blog.appspot.com/rps.zip \ -O /tmp/rps.zip !wget --no-check-certificate \ https://storage.googleapis.com/laurencemoroney-blog.appspot.com/rps-test-set.zip \ -O /tmp/rps-test-set.zip
使用下面的代碼提取下載的文件。
import os
import zipfile
local_zip = '/tmp/rps.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/')
zip_ref.close()
local_zip = '/tmp/rps-test-set.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/')
zip_ref.close()我們用下面的代碼創建文件夾,并將提取的圖像放入其中。
rock_dir = os.path.join('/tmp/rps/rock')
paper_dir = os.path.join('/tmp/rps/paper')
scissors_dir = os.path.join('/tmp/rps/scissors')
print('total training rock images:', len(os.listdir(rock_dir)))
print('total training paper images:', len(os.listdir(paper_dir)))
print('total training scissors images:', len(os.listdir(scissors_dir)))
rock_files = os.listdir(rock_dir)
print(rock_files[:10])
paper_files = os.listdir(paper_dir)
print(paper_files[:10])
scissors_files = os.listdir(scissors_dir)
print(scissors_files[:10])下圖顯示了有關數據集的信息

使用下面的代碼,你可以創建CNN。數據將通過縮放、剪切、翻轉和重新縮放自動增加。然后選擇最佳的圖像大小。你還將注意到每個類中的圖像數量以及與之關聯的類的數量。最后,還要觀察訓練精度和測試精度。
你還可以在convolutional_query內部傳遞read_mode超參數,在其中你可以指定讀取模式。允許有三種讀取模式。我將逐一描述它們。默認情況下,**read_mode=distinguisher()**自動檢測數據類型。允許的三種讀取模式是:
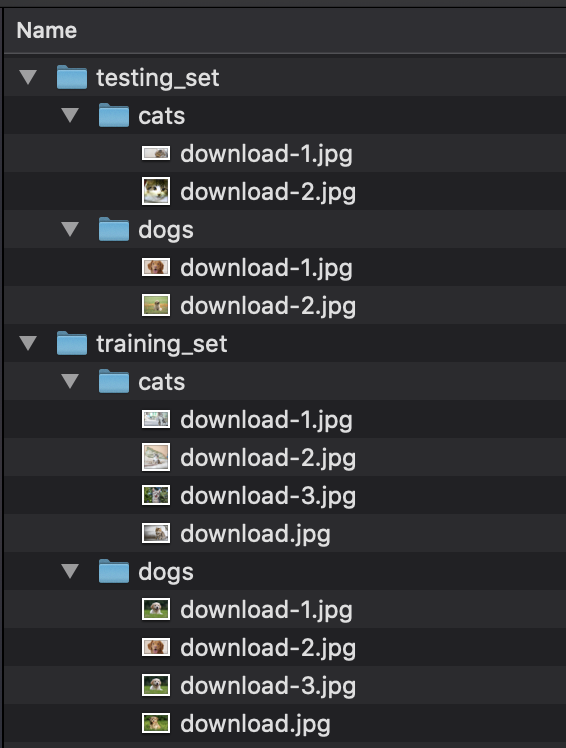
目錄由“training_set”和“testing_set”文件夾組成,這兩個文件夾都包含帶有圖像的分類文件夾。
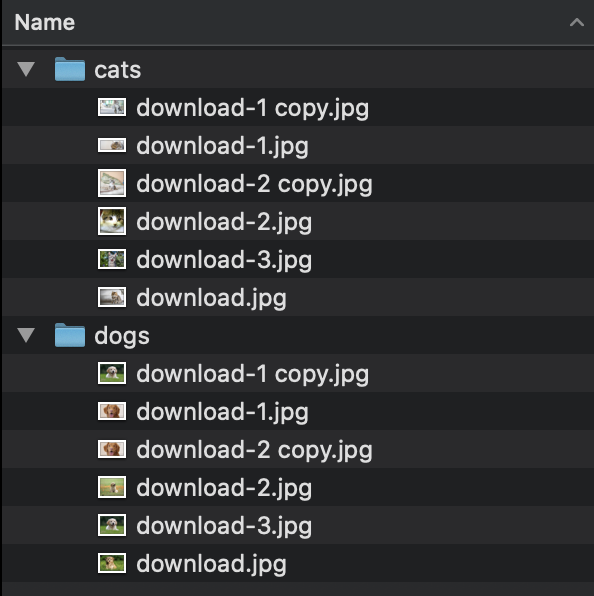
目錄由包含圖像的分類文件夾組成。
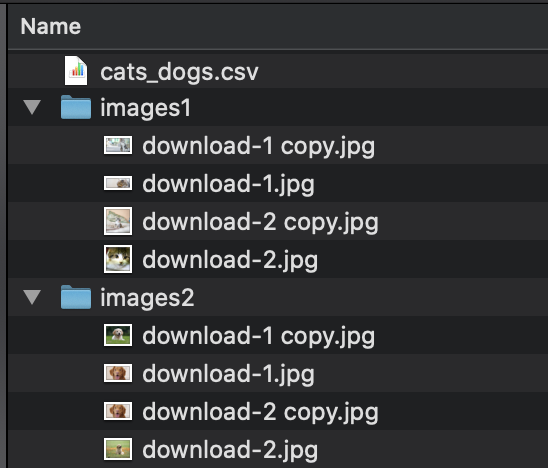
目錄由圖像文件夾和包含圖像列的CSV文件組成。
newClient = client('/tmp/rps')
newClient.convolutional_query("Please classify my images")
我使用垃圾郵件分類數據集來解決這個問題。
鏈接:https://www.kaggle.com/team-ai/spam-text-message-classification
new_client = client('SPAM text message 20170820 - Data.csv')
new_client.text_classification_query('sentiment')
new_client.classify_text('new text to classify')
new_client.classify_text()將對其中輸入的文本進行分類。在上面的輸出中,你可以看到它將我的文本分類為“ham”。
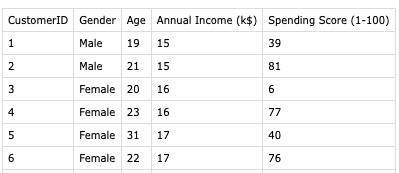
我使用商場客戶劃分數據來解決這個問題:https://www.kaggle.com/vjchoudhary7/customer-segmentation-tutorial-in-python
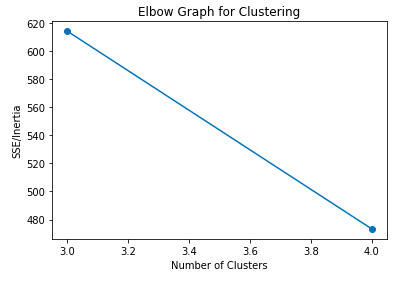
Libra將創建一個K均值聚類模型,并將確定最佳簇中心,優化準確度,以及最佳聚類數。

在本節中,我將使用神經網絡查詢進行分類。為此,我使用了一個私人數據集來預測大腦信號的行為。讓我們檢查一下它在那個數據集上的執行情況。
new_client = client('Mood_classification.csv')
new_client.neural_network_query('Predict the behavior')
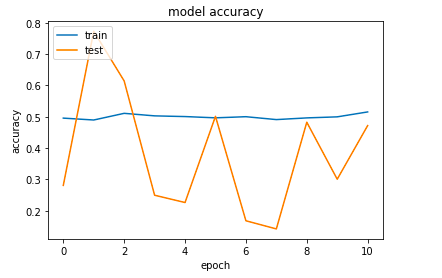
從上面的代碼中,你可以注意到模型使用的初始層數是3。然后,它還測試了不同層數的精度,這些層數根據前一層的性能而變化。
它可以預測找到的最佳層數以及訓練和測試的準確性。看來我需要為我的數據集收集更多的數據。
你可以用new_client.model()[‘model’]訪問模型,并可以使用Keras的summary()函數獲取神經網絡模型的摘要。
new_client.model()['model'].summary()

到此,關于“基于Libra的卷積神經網絡怎么實現”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





