溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關如何用MNIST數據集進行基于深度學習的可變形圖像配準的驗證,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
用MNIST數據集做了一個簡單圖像配準方案的驗證,效果不錯。
Sarath Chandra
https://medium.com/@sarathchandra.knv31/deep-learning-based-2d-deformable-image-registration-with-mnist-2db3b6ee1426
我被Google Summer of Code 2020錄取,進行基于深度學習的圖像配準的研究工作。我的項目鏈接 —— MRI Registration using Deep Learning and Implementation of Thin-Plate Splines
圖像配準是找到將一幅圖像對齊到另一幅圖像的轉換的過程。通常,這個過程的輸入是兩幅圖像:一個參考圖像,也稱為靜態圖像,和一個將與靜態圖像對齊的移動圖像。這里的目標是對移動圖像進行扭曲以匹配到靜態圖像。
給定一個移動圖像和靜態圖像作為輸入,卷積編碼器-解碼器網絡計算兩個圖像之間的像素變形。這個變形場也稱為配準場,給出了運動圖像中新的采樣位置。通過對這些位置的運動圖像進行采樣,得到變換后的圖像。簡單地說,我們只是重新安排移動圖像中的像素,直到它盡可能地與靜態圖像匹配。框架如下圖所示。
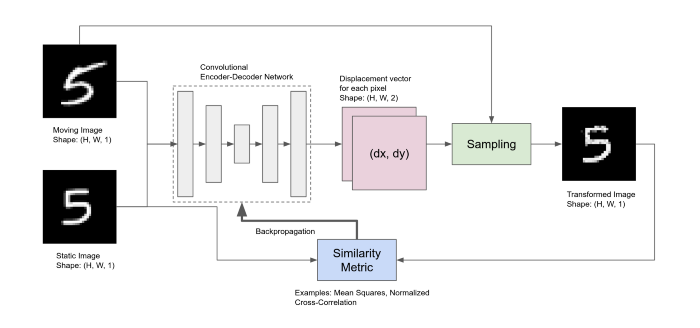
通過對編解碼器網絡進行訓練,輸出一個dense的變形場,該變形場被采樣器用來使運動圖像與靜止圖像相匹配。
采樣點不一定映射到移動圖像中的整數位置。所以當點是分數時需要一些插值技術。此外,為了使整個框架是端到端可訓練的,采樣塊也需要是可微的。可以使用“Spatial transformer networks”。
正如“Spatial transformer networks”中描述的,我使用了雙線性插值,它是可微的,可以寫成純張量流函數。在雙線性插值中,分數位置上的值是四個最近整數位置上的值的加權和。
通過優化變換后的圖像和靜態圖像之間的相似性度量來訓練網絡。一旦訓練完成,網絡可以一次性預測最優配準域,這與傳統算法不同,傳統算法需要對每一對新配準進行數值優化,因此需要更長的時間。
MNIST數據集經過篩選,只保留一類圖像,而靜態圖像是從篩選數據集的測試集中隨機選擇的。網絡使用相似度度量進行訓練,這是衡量兩幅圖像的相似/不相似程度的指標。一些度量的例子包括均方誤差(MSE)和歸一化交叉相關(NCC)。由于交叉相關損失對強度變化具有魯棒性,所以使用了交叉相關損失。它就是兩個歸一化的圖像的點積。數學上是:
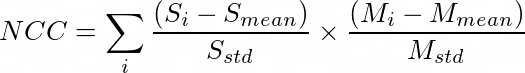
S和M分別代表靜態圖像和運動圖像。下標mean和std分別表示圖像的均值和標準差。對圖像中所有像素求和。該訓練在Tesla K80 GPU上大約需要5分鐘,在CPU (i5-8250U)上大約需要10分鐘。

看完上述內容,你們對如何用MNIST數據集進行基于深度學習的可變形圖像配準的驗證有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





