溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么進行Hive原理實踐,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
Hive基本架構
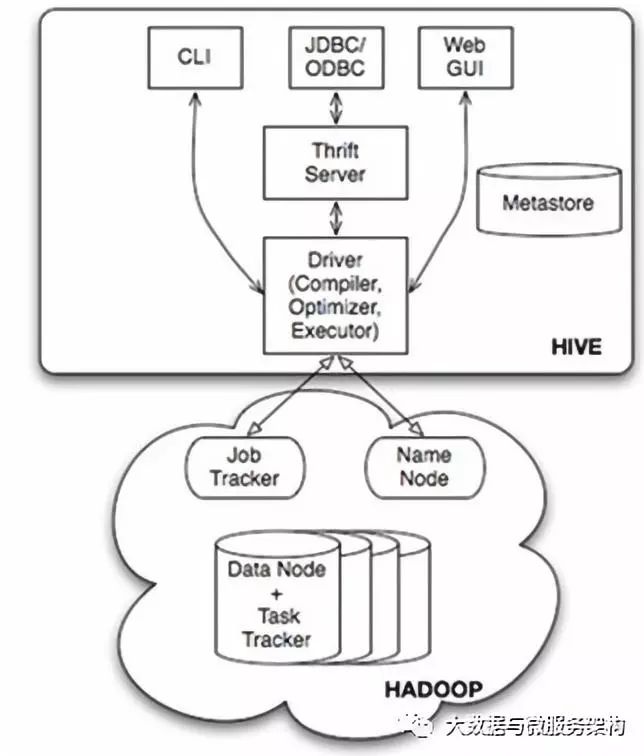
Driver組件:核心組件,整個Hive的核心,該組件包括Complier(編譯器)、Optimizer(優化器)和Executor(執行器),它們的作用是對Hive SQL語句進行解析、編譯優化,生成執行計劃,然后調用底層的MapReduce計算框架。
Metastore組件:元數據服務組件,這個組件存儲Hive的元數據。支持的關系型數據庫有Derby和MySQL。
CLI:命令行接口
Thrift Server:提供JDBC和ODBC接入能力,用戶進行可擴展且跨語言的服務開發。Hive集成了該服務,能讓不同的編程語言調用Hive的接口。
Hive Web Interface(HWI):Hive客戶端提供了一種通過網頁方式訪問Hive所提供的服務。這個接口對應Hive的HWI組件。
Hive通過CLI、JDBC/ODBC 或者HWI接收相關的Hive SQL查詢,并通過Driver組件進行編譯,分析優化,最后變成可執行的MapReduce。
HIVE SQL
hive表:分內部表和外部表
內部表:會把hdfs目錄文件移動到hive對應的目錄。刪除表對應的表接口和文件也會一起刪除。
外部表:不會移動關聯的hdfs文件,刪除表只會刪除表結構。
使用場景:如果數據的所有處理都在hive中進行,那么更傾向于選擇內部表,但如果Hive和其它工具針對相同的數據集做處理,那么外部表更合適。
分區和分桶
分區可以讓數據的部分查詢變更更快,表或者分區可以進一步劃分為桶,桶通常在原始數據中加入一些額外的結構,這些結構可以用于高效查詢。
分桶通常有兩個原因:一是高效查詢,二是高效的進行抽樣。
Hive SQL執行原理:
大致歸三類:select語句、group by 語句、join語句。
流程:輸入分片->Map階段->Combiner(可選)->Shuffle階段(分區、排序、分隔、復制、合并等過程)-> Reduce階段-> 輸出文件。
其他SQL on Hadoop技術:Impala、Drill、HAWQ、Presto、Dremel、Spark SQL。
Hive優化
主要挑戰數據傾斜:group by 引起的傾斜優化、Count distinct 優化、大表join小表(mapjoin)優化、大表join大表優化。
關于怎么進行Hive原理實踐問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





