溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
電商大數據項目-推薦系統實戰(一)環境搭建以及日志,人口,商品分析
https://blog.51cto.com/6989066/2325073
電商大數據項目-推薦系統實戰之推薦算法
https://blog.51cto.com/6989066/2326209
電商大數據項目-推薦系統實戰之實時分析以及離線分析
https://blog.51cto.com/6989066/2326214
(七)推薦系統常用算法
協同過濾算法
協同過濾算法(Collaborative Filtering:CF)是很常用的一種算法,在很多電商網站上都有用到。CF算法包括基于用戶的CF(User-based CF)和基于物品的CF(Item-based CF)。
(八)Apache Mahout和Spark MLLib
① Apache Mahout簡介
Apache Mahout是Apache Software Foundation (ASF)旗下的一個開源項目,提供了一些經典的機器學習的算法,皆在幫助開發人員更加方便快捷地創建智能應用程序。目前已經有了三個公共發型版本,通過ApacheMahout庫,Mahout可以有效地擴展到云中。Mahout包括許多實現,包括聚類、分類、推薦引擎、頻繁子項挖掘。
Apache Mahout的主要目標是建立可伸縮的機器學習算法。這種可伸縮性是針對大規模的數據集而言的。Apache Mahout的算法運行在ApacheHadoop平臺下,他通過Mapreduce模式實現。但是,Apache Mahout并非嚴格要求算法的實現基于Hadoop平臺,單個節點或非Hadoop平臺也可以。Apache Mahout核心庫的非分布式算法也具有良好的性能。
Mahout主要包含以下5部分
?頻繁挖掘模式:挖掘數據中頻繁出現的項集。
?聚類:將諸如文本、文檔之類的數據分成局部相關的組。
?分類:利用已經存在的分類文檔訓練分類器,對未分類的文檔進行分類。
?推薦引擎(協同過濾):獲得用戶的行為并從中發現用戶可能喜歡的事物。
?頻繁子項挖掘:利用一個項集(查詢記錄或購物記錄)去識別經常一起出現的項目。
② Spark MLLib簡介
Spark MLlib(Machine Learnig lib) 是Spark對常用的機器學習算法的實現庫,同時包括相關的測試和數據生成器。Spark的設計初衷就是為了支持一些迭代的Job, 這正好符合很多機器學習算法的特點。
Spark MLlib目前支持4種常見的機器學習問題: 分類、回歸、聚類和協同過濾。Spark MLlib基于RDD,天生就可以與Spark SQL、GraphX、Spark Streaming無縫集成,以RDD為基石,4個子框架可聯手構建大數據計算中心!
下圖是MLlib算法庫的核心內容:
九、基于用戶興趣的商品推薦
(一)基于用戶的CF(User CF)和基于物品的CF(Item CF)
?基于用戶的CF(User CF)
基于用戶的 CF 的基本思想相當簡單,基于用戶對物品的偏好找到相鄰鄰居用戶,然后將鄰居用戶喜歡的推薦給當前用戶。計算上,就是將一個用戶對所有物品的偏好作為一個向量來計算用戶之間的相似度,找到 K 鄰居后,根據鄰居的相似度權重以及他們對物品的偏好,預測當前用戶沒有偏好的未涉及物品,計算得到一個排序的物品列表作為推薦。圖 2 給出了一個例子,對于用戶 A,根據用戶的歷史偏好,這里只計算得到一個鄰居 - 用戶 C,然后將用戶 C 喜歡的物品 D 推薦給用戶 A。
?基于物品的CF(Item CF)
基于物品的 CF 的原理和基于用戶的 CF 類似,只是在計算鄰居時采用物品本身,而不是從用戶的角度,即基于用戶對物品的偏好找到相似的物品,然后根據用戶的歷史偏好,推薦相似的物品給他。從計算的角度看,就是將所有用戶對某個物品的偏好作為一個向量來計算物品之間的相似度,得到物品的相似物品后,根據用戶歷史的偏好預測當前用戶還沒有表示偏好的物品,計算得到一個排序的物品列表作為推薦。圖 3 給出了一個例子,對于物品 A,根據所有用戶的歷史偏好,喜歡物品 A 的用戶都喜歡物品 C,得出物品 A 和物品 C 比較相似,而用戶 C 喜歡物品 A,那么可以推斷出用戶 C 可能也喜歡物品 C。
十、基于ALS協同過濾推薦
一)ALS的基本原理
(二)基于Spark MLLib的ALS
基本的過程是:
a.加載數據到rating RDD中
b.使用rating RDD訓練ALS模型
c.使用ALS模型為用戶進行物品推薦,將結果打印
d.評估模型的均方差
(三)基于Apache Mahout的ALS
1.將rating分為預測集(10%)和訓練集(90%)
bin/mahout splitDataset -i /input/ratingdata.txt -o /output/ALS/dataset
2.使用并行ALS算法,對訓練集來矩陣進行分解,之后會在/output/ALS/out生成兩個矩陣U(用戶特征矩陣)和M(物品特征矩陣),以及評分
bin/mahout parallelALS -i /output/ALS/dataset/trainingSet/ -o /output/ALS/out --numFeatures 20 --numIterations 5 --lambda 0.1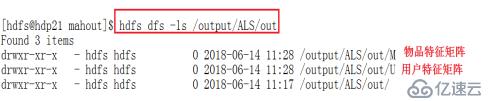
3.通過預測集來對模型進行評價,評價標準是RMSE。RMSE結果會輸出在/output/ALS/rmse/rmse.txt
bin/mahout evaluateFactorization -i /output/ALS/dataset/probeSet/ -o /output/ALS/rmse --userFeatures /output/ALS/out/U --itemFeatures output/ALS/out/M
4.最后進行推薦
bin/mahout recommendfactorized -i /output/ALS/out/userRatings -o /output/ALS/recommendations --userFeatures /output/ALS/out/U --itemFeatures output/ALS/out/M --numRecommendations 6 --maxRating 5
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





