溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
第一步:版本的選擇:
spark-0.x spark-1.x(主流:Spark-1.3 和 Spark-1.6) spark-2.x(最新 Spark-2.4) 下載地址:http://spark.apache.org/downloads.html(官網) 其他鏡像網站:https://mirrors.tuna.tsinghua.edu.cn/apache/spark/ https://www.apache.org/dyn/closer.lua/spark/spark-2.3.0/ https://www.apache.org/dyn/closer.lua/spark/ 注意這里我選擇是:spark-2.3.0-bin-hadoop2.7.tgz。 |
第二步:關于搭建spark集群的環境:
spark底層是使用scala語言編寫的,所有這里需要安裝scala的環境,并且配置scala的環境變量。
scala和spark也都需要jdk,所以我們還需要配置jdk的環境以及環境變量,關于jdk的版本最好是java 8+。
這里我們用spark-2.3
注意:由于安裝比較簡單,此時略過java以及scala的安裝。
轉載:https://www.cnblogs.com/liugh/p/6623530.html(Linux下安裝java)
轉載:https://www.cnblogs.com/freeweb/p/5623795.html(Linux下安裝scala)
第三步:spark集群的規劃:
Server | Master | Worker |
hostname01 | √ |
|
hostname02 | √ | |
hostname03 |
| √ |
第四步:具體的集群安裝:
| ①上傳下載好的spark安裝包到集群的任意一個節點(由于個人品味不一,這里上傳軟件的方式也不同,作者使用的是Xshell) ②解壓,并放置到統一管理的目錄下(注意這個目錄一定要有讀寫的權限):tar zxvf spark-2.3.2-bin-hadoop2.7.tgz -C /application/ ③進入相應的spark的conf目錄:cd $SPARK_HOME/conf: [user01@hostname01 ~]$ mv spark-env.sh.template spark-env.sh [user01@hostname01 conf]$ vim spark-env.sh(加入以下配置) export JAVA_HOME=/application/jdk1.8.0_73 export SPARK_MASTER_HOST=hostname01 export SPARK_MASTER_PORT=7077 ④修改$SPARK_HOME/conf/slaves(在其中加入集群的從節點的主機或者IP,這里我將hostname02、hostname03當做從節點) hostname02 hostname03 注意:這里的配置,不要用任何多余的空格和空行!!! ⑤將spark安裝包copy到集群的其他節點上 scp -r /application/spark-2.3.2-bin-hadoop2.7 hostname02: /application scp -r /application/spark-2.3.2-bin-hadoop2.7 hostname03: /application 注意:由于這里集群的節點不是很多,所以在分發安裝包的時候,可以手動輸入密碼,個人建議還是配置一下ssh面秘鑰登錄。 轉載:https://blog.csdn.net/furzoom/article/details/79139570 ⑥配置spark的環境變量:(注意這里需要所有的集群節點都要配置,當然配置的地方,根據不同要求而定) 我這里配置在/etc/profile : (由于提前做了sudo的權限設置,所以在普通用戶下依然可以修改/etc/profile) export SPARK_HOME=/application/spark-2.3.2-bin-hadoop2.7 PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin #注意這里的bin和sbin都要配置 ⑦最終啟動集群: [user01@hostname01 ~]$ /application/spark-2.3.2-bin-hadoop2.7/sbin/start-all.sh 切記:如果集群有hadoop集群,那么在hadoop的sbin目錄下也有start-all.sh的命令,所以這里只能使用全路徑 |
第五步:測試是否啟動成功
第一種方法:
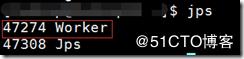
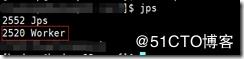
使用jps命令查看進程:master是集群的主節點,worker是集群的從節點:
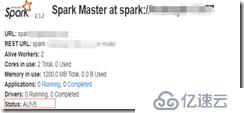
第二種方法:查看web UI界面:
最終出現上述情況任意一個,說明集群搭建成功。這里分享的是分布式集群,HA集群,需要步驟比較復雜
并且需要zookeeper組件。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。