溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Unity中如何優化字符串和文本,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
字符串和文本:
在Unity項目中,處理字符串和文本經常會產生性能問題。在C#中,字符串是不變的。任何對字符串的操作都會重新分配新的字符串,這個代價是非常昂貴的。如果在多重循環中重復地執行字符串連接操作,就會造成性能問題,特別是對長的字符串或者大的數據集操作的時候。
因此,把N個字符串連接起來就會分配N-1個中間的字符串,這樣連續的操作就會對堆內存產生壓力。
當我們需要在多重循環中或者每一幀對字符串進行操作時,記得使用StringBuilder來操作字符串。StringBuilder也還能被重用,以進一步減少內存的分配。
關于字符串的使用,詳細內容也可以參考微軟發布的文檔:
Best Practices for Using Strings in .NET docs.microsoft.com
https://docs.microsoft.com/en-us/dotnet/standard/base-types/best-practices-strings
地域限制和順序比較:
與字符串相關代碼的一個核心問題就是無意中會使用默認的、慢的字符串API。這些API的目的是為了一些商業化的應用,能夠處理出現在文本中的有關不同文化和語法規則的字符。
比如,下面的代碼在一些使用美式英語的地區運行時,會返回true。在歐洲地區運行時,返回false。
提示:Unity腳本都是基于美式英語來運行的。
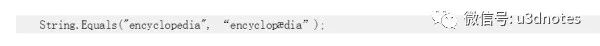
對于大多數的項目,這個完全沒有必要。而且我們簡單對每個字符進行比較,判斷兩個字符串是否相等,這速度大約會比使用上面的方式快10倍。當然,我們也可以調用String.Equals方法,然后設置比較類型StringComparison.Ordinal來實現:

低效率的內置字符串API:
除了上面講的順序比較外,也有一些C#的字符串的API效率比較低。比如:String.Format,String.StartsWith和String.EndsWith。以下是Unity給出的一些測試數據:
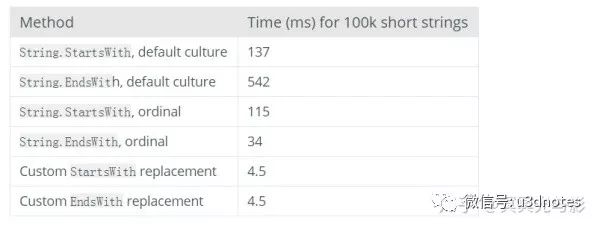
可見,如果是我們自己實現String.StartsWith和String.EndsWith,執行效率會高的多。實現方法也可以參考下圖:

正則表達式:
在字符串匹配和操作字符串方面,正則表達式是非常消耗性能的。而且,C#類庫也實現了正則表達式。所以,即使是調用IsMatch這樣簡單的函數,都會臨時分配很多的內存。我們在開發中,出了初始化會臨時分配內存外,應該不允許在其他地方臨時分配較多內存。
如果一定要用正則表達式的話,注意不要使用靜態的Regex.Match和Regex.Replace方法。這兩個方法會動態的編譯正則表達式,但不會緩存生成的對象。
下面是使用正則表達式的一個例子:

每一次以上的代碼被執行,它都會生成5kb的內存垃圾。為了減少垃圾的生成,我們需要對以上代碼進行重構:

在這個例子中,每一次調用myRegExp.Match只會產生320b的內存垃圾。對于簡單的字符串匹配而言,它對內存的消耗依舊有點多,但與之前的例子相比,這已經是很大的改進了。
因此,如果正則表達式是不變的字符串常量,那么把它們當作第一個參數傳遞給Regex的構造器來預編譯它們會更加有效。這些Regex對象也是可以被重用的。
XML, JSON和其他的長篇文本解析:
在loading時,解析文本通常是一項耗時的操作。有些情況下,解析文本所花的時間會超過loading和實例化Assets的時間。
這原因取決于我們用的文本解析器。C#內置的XML解析器是非常靈活的,但是,它不能對一些特殊的數據布局進行優化。
許多第三方解析器都是基于反射構建的。雖然在開發中使用反射是一個不錯的選擇(因為它能很好的適應數據布局的變化),但用反射是非常慢的。
Unity已經引入了一個帶有內置JSONUtility API(可參考:https://docs.unity3d.com/ScriptReference/JsonUtility.html)的局部解決方案,它為Unity的序列化系統提供了一個接口,用來處理JSON數據。在許多方面它是優于C#的JSON解析器。但是它也有不足之處,在不添加額外代碼的情況下,它不能序列化許多復雜的數據類型,比如字典(在Unity的序列化過程中,請參閱ISerializationCallbackReceiver接口,以方便轉換一些復雜的數據類型)
如果在文本解析中遇到性能問題,可以考慮以下的解決方案:
1.在Build時進行解析
當我們需要解析文本時,最好避免在游戲中進行這一步的操作。我們可以在Build的時候把文本解析成二進制文件。以加快讀取時的速度。
2.數據分割和延遲加載
第二種情況情況是我們需要把能解析成小塊的數據分割開來。一旦分割,數據解析就可以在不同時間進行。在理想的情況下,我們確定哪部分數據是會用到的,然后只加載用到的那部分數據。
3.線程
對于那些不需要用Unity API來操作的數據,可以在另外的線程中來解析它們。這可以提高多核CPU的利用率,是相當有用的。當然,我們在寫代碼時需要注意避免死鎖。
以上是“Unity中如何優化字符串和文本”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





