溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹Elasticsearch 集群健康值紅色終極解決方案是怎樣的,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
Elasticsearch當清理緩存( echo 3 > /proc/sys/vm/drop_caches )的時候,出現
如下集群健康值:red,紅色預警狀態,同時部分分片都成為灰色。 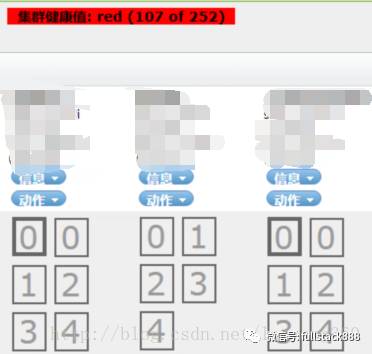
查看Elasticsearch啟動日志會發現如下:
集群服務超時連接的情況。
bserver: timeout notification from cluster service. timeout setting [1m], time since start [1m]
該問題排查耗時很長,問題已經解決。
特將問題排查及解決方案詳盡的整理出來。
head插件會以不同的顏色顯示。
1)、綠色——最健康的狀態,代表所有的主分片和副本分片都可用;
2)、黃色——所有的主分片可用,但是部分副本分片不可用;
3)、紅色——部分主分片不可用。(此時執行查詢部分數據仍然可以查到,遇到這種情況,還是趕快解決比較好。)
參考官網:http://t.cn/RltLEpN(部分中文集群健康狀態博文資料翻譯的不夠精確,以官網為準)
如果集群狀態為紅色, Head插件顯示:集群健康值red 。則說明:至少一個主分片分配失敗。
這將導致一些數據以及索引的某些部分不再可用。
盡管如此, ElasticSearch還是允許我們執行查詢,至于是通知用戶查詢結果可能不完整還是掛起查詢,則由應用構建者來決定。
一句話解釋:未分配的分片。
啟動ES的時候,通過Head插件不停刷新,你會發現集群分片會呈現紫色、灰色、最終綠色的狀態。
如果不能分配分片,例如,您已經為集群中的節點數過分分配了副本分片的數量,則分片將保持UNASSIGNED狀態。
其錯誤碼為:ALLOCATION_FAILED。
你可以通過如下指令,查看集群中不同節點、不同索引的狀態。
GET _cat/shards?h=index,shard,prirep,state,unassigned.reason
head插件查看會:Elasticsearch啟動N長時候后,某一個或幾個分片仍持續為灰色。


方案一:極端情況——這個分片數據已經不可用,直接刪除該分片。
ES中沒有直接刪除分片的接口,除非整個節點數據已不再使用,刪除節點。
curl -XDELETE ‘localhost:9200/index_name/’
方案二:集群中節點數量>=集群中所有索引的最大副本數量 +1。
N> = R + 1
其中:
N——集群中節點的數目;
R——集群中所有索引的最大副本數目。
知識點:當節點加入和離開集群時,主節點會自動重新分配分片,以確保分片的多個副本不會分配給同一個節點。換句話說,主節點不會將主分片分配給與其副本相同的節點,也不會將同一分片的兩個副本分配給同一個節點。
如果沒有足夠的節點相應地分配分片,則分片可能會處于未分配狀態。
由于我的集群就一個節點,即N=1;所以R=0,才能滿足公式。
問題就轉嫁為:
1)添加節點處理,即N增大;
2)刪除副本分片,即R置為0。
R置為0的方式,可以通過如下命令行實現:
root@tyg:/# curl -XPUT "http://localhost:9200/_settings" -d' { "number_of_replicas" : 0 } '{"acknowledged":true}方案三:allocate重新分配分片。
如果方案二仍然未解決,可以考慮重新分配分片。
可能的原因:
1)節點在重新啟動時可能遇到問題。正常情況下,當一個節點恢復與群集的連接時,它會將有關其分片的信息轉發給主節點,然后主節點將這分片從“未分配”轉換為“已分配/已啟動”。
2)當由于某種原因(例如節點的存儲已被損壞)導致該進程失敗時,分片可能保持未分配狀態。
在這種情況下,您必須決定如何繼續:嘗試讓原始節點恢復并重新加入集群(并且不要強制分配主分片);
或者強制使用Reroute API分配分片并重新索引缺少的數據原始數據源或備份。
如果您決定分配未分配的主分片,請確保將“allow_primary”:“true”標志添加到請求中。
ES5.X使用腳本如下:

ES2.X及早期版本,將 allocate_replica改為 allocate,其他不變。
腳本解讀:
步驟1:定位 UNASSIGNED 的節點和分片
curl -s 'localhost:9200/_cat/shards' | fgrep UNASSIGNED
步驟2:通過 allocate_replica 將 UNASSIGNED的分片重新分配。
1)路由
原理很簡單,把每個用戶的數據都索引到一個獨立分片中,在查詢時只查詢那個用戶的分片。這時就需要使用路由。
使用路由優勢:路由是優化集群的一個很強大的機制。
它能讓我們根據應用程序的邏輯來部署文檔, 從而可以用更少的資源構建更快速的查詢。
2)在索引過程中使用路由
我們可以通過路由來控制 ElasticSearch 將文檔發送到哪個分片。
路由參數值無關緊要,可以取任何值。重要的是在將不同文檔放到同一個分片上時, 需要使用相同的值。
3)指定路由查詢
路由允許用戶構建更有效率的查詢,當我們只需要從索引的一個特定子集中獲取數據時, 為什么非要把查詢發送到所有的節點呢?
指定路由查詢舉例:
curl -XGET 'localhost:9200/documents/_search?pretty&q=*:*&routing=A'
4)集群再路由reroute
reroute命令允許顯式地執行包含特定命令的集群重新路由分配。
例如,分片可以從一個節點移動到另一個節點,可以取消分配,或者可以在特定節點上顯式分配未分配的分片。
5)allocate分配原理
分配unassigned的分片到一個節點。
將未分配的分片分配給節點。接受索引和分片的索引名稱和分片號,以及將分片分配給它的節點。。
它還接受allow_primary標志來明確指定允許顯式分配主分片(可能導致數據丟失)。
1)該問題的排查累計超過6個小時,最終找到解決方案。之前幾近沒有思路,想放棄,但咬牙最終解決。
2) 切記,第一手資料很重要!
Elasticsearch出現問題,最高效的解決方案是第一手資料ES英文官網文檔,其次是ES英文論壇、ES github issues,再次是stackoverflow等英文論壇、博客。最后才是:Elasticsearch中文社區、其他相關中文技術博客等。
關于Elasticsearch 集群健康值紅色終極解決方案是怎樣的就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





