溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今年,實時流計算技術開始步入主流,各大廠都在不遺余力地試用新的流計算框架,實時流計算引擎和 API 諸如 Spark Streaming、Kafka Streaming、Beam 和 Flink 持續火爆。阿里巴巴自 2015 年開始改進 Flink,并創建了內部分支 Blink,目前服務于阿里集團內部搜索、推薦、廣告和螞蟻等大量核心實時業務。12 月 20 日,由阿里巴巴承辦的 Flink Forward China 峰會在北京國家會議中心召開,來自阿里、華為、騰訊、美團點評、滴滴、字節跳動等公司的技術專家與參會者分享了各公司基于 Flink 的應用和實踐經驗。在大會的主題演講上,阿里巴巴集團副總裁周靖人宣布,阿里巴巴內部 Flink 版本 Blink 將于 2019 年 1 月正式開源!阿里希望通過 Blink 開源進一步加深與 Flink 社區的聯動,并推動國內更多中小型企業使用 Flink。
會上,我對阿里巴巴計算平臺事業部研究員蔣曉偉(花名量仔)進行了獨家專訪,他與我們分享了關于下一代實時流計算引擎的看法,并針對 Blink 的重要新特性、開源后 Blink 與 Flink 之間的關系、Blink 后續規劃等問題進行了解答。
阿里巴巴與 Flink
隨著人工智能時代的降臨和數據量的爆發,在典型的大數據業務場景下,數據業務最通用的做法是:選用批處理的技術處理全量數據,采用流式計算處理實時增量數據。在許多業務場景之下,用戶的業務邏輯在批處理和流處理之中往往是相同的。但是,用戶用于批處理和流處理的兩套計算引擎是不同的。
因此,用戶通常需要寫兩套代碼。毫無疑問,這帶來了一些額外的負擔和成本。阿里巴巴的商品數據處理就經常需要面對增量和全量兩套不同的業務流程問題,所以阿里巴巴就在想:能不能有一套統一的大數據引擎技術,用戶只需要根據自己的業務邏輯開發一套代碼。這樣在各種不同的場景下,不管是全量數據還是增量數據,亦或者實時處理,一套方案即可全部支持,這就是阿里巴巴選擇 Flink 的背景和初衷。
彼時的 Flink 不管是規模還是穩定性尚未經歷實踐,成熟度有待商榷。阿里巴巴實時計算團隊決定在阿里內部建立一個 Flink 分支 Blink,并對 Flink 進行大量的修改和完善,讓其適應阿里巴巴這種超大規模的業務場景。簡單地說,Blink 就是阿里巴巴開發的基于開源 Flink 的阿里巴巴內部版本。
阿里巴巴基于 Flink 搭建的平臺于 2016 年正式上線,并從阿里巴巴的搜索和推薦這兩大場景開始實現。目前阿里巴巴所有的業務,包括阿里巴巴所有子公司都采用了基于 Flink 搭建的實時計算平臺。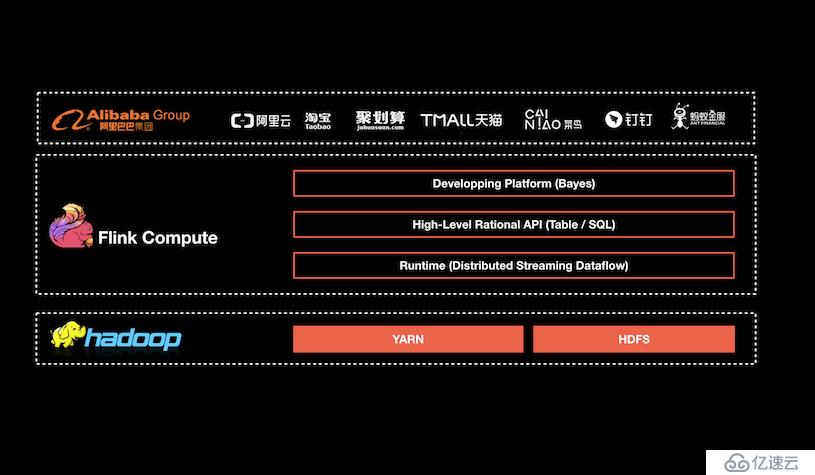
目前,這套基于 Flink 搭建的實時計算平臺不僅服務于阿里巴巴集團內部,而且通過阿里云的云產品 API 向整個開發者生態提供基于 Flink 的云產品支持。
以下內容整理自 AI 前線對蔣曉偉的采訪。
開源的時機
我:為什么選擇現在將 Blink 開源?這其中有哪些考量?什么樣的時機才是開源最合適的時機?
蔣曉偉:在我看來,有幾個因素:第一個因素是,這幾年我們一直試圖把阿里對 Flink 的改進推回社區,但社區有自己的步伐,很多時候可能無法把我們的變更及時推回去。對于社區來說,需要達成共識,才能更好地保證開源項目的質量,但同時就會導致推入的速度慢一些。經過這幾年積累,我們這邊和社區之間的差距已經變得比較大了。Blink 有一些很好的新功能,比如批處理功能,在社區版本是沒有的。在過去這段時間里,我們不斷聽到有人問,Blink 什么時候能開源、是不是能開源這樣的呼聲。我們有兩種方法,一種就是慢慢地推回去再給用戶用。但我們認為這樣等下去對社區不是最好的。我們還是希望盡快把我們的代碼拿出來,盡量讓大家都能用起來。所以最近這半年,我們一直都在準備把代碼整理好去進行開源。
選擇在這個時間點開源有幾個好處:第一個好處是我們所開源的這些代碼在阿里內部經過像雙一十、雙十二這樣巨大流量的檢驗,讓我們對它的質量有更大的信心,這是非常大的好處;第二個好處,Flink Forward 大會是第一次在中國舉辦,在這樣一個場合開源表明了阿里對 Flink 社區堅定的支持,這是一個比較好的場合。主要是基于這些考慮。
選 Blink 還是 Flink?這不會是一個問題
我:開源的 Blink 版本會和阿里巴巴內部使用的 Blink 保持一致嗎?
蔣曉偉:即將開源的是阿里巴巴雙十二的上線版本,還會有一些小的改進。
我:Blink 開源后,兩個開源項目之間的關系會是怎樣的?未來 Flink 和 Blink 也會由不同的團隊各自維護嗎?
蔣曉偉:開源的意思是,我們愿意把 Blink 的代碼貢獻出來,但這兩個項目是一個項目。有一件事情需要澄清一下,我們將公開 Blink 的所有代碼,讓大家都可以看到,但與此同時,我們會跟社區一起努力,通過討論決定 Blink 以什么樣的方式進入 Flink 是最合適的。因為 Flink 是一個社區的項目,我們需要經過社區的同意才能以分支的形式進入 Flink,或者作為變更 Merge 到項目中。我想強調一下,我們作為社區的一員需要跟社區討論才能決定這件事情。
Blink 永遠不會成為另外一個項目,如果后續進入 Apache 一定是成為 Flink 的一部分,我們沒有任何興趣另立旗幟,我們永遠是 Flink 的一部分,也會堅定地支持 Flink。我們非常愿意把 Blink 的代碼貢獻給所有人,所以明年 1 月份我們會先將 Blink 的代碼公開,但這期間我們也會和社區討論,以什么樣的形式進入 Flink 是最合適的、怎么貢獻是社區最希望的方式。
我們希望,在 Blink 開源之后,和社區一起努力,把 Blink 好的地方逐步推回 Flink,成為 Flink 的一部分,希望最終 Flink 和 Blink 變成一個東西,阿里巴巴和整個社區一起來維護。而不是把它分成兩個東西,給用戶選擇的困難,這不是我們想要的。
因此未來用戶也不會面臨已經部署了 Flink、是否要把 Flink 遷移到 Blink 的問題,企業選型時也不需要在 Flink 和 Blink 之間抉擇,Blink 和 Flink 會是同一個項目。Blink 開源只有一個目的,就是希望 Flink 做得更好。
Blink 改進了什么?
我:能不能重點介紹一下即將開源的 Blink 版本有哪些比較重要的新技術特性?與 Flink 最新發布版本相比,阿里的 Blink 做了哪些方面的優化和改進?
蔣曉偉:阿里巴巴實時計算團隊不僅對 Flink 在性能和穩定性上做出了很多改進和優化,同時在核心架構和功能上也進行了大量創新和改進。過去兩年多,有很多更新已經推回給社區了,包括 Flink 新的分布式架構等。
目前我們的 Blink 版本跟社區版本還有幾點差異,第一個是穩定性方面,我們做了一些優化,在某些場景會比社區版本更加穩定,特別是在大規模場景。另外還有一個比較大的不一樣是我們全新的 Flink SQL 技術棧,它在功能上,特別是在批處理的功能上比社區版本強大很多。它支持現在標準 SQL 幾乎所有的語法和語義。另外,在性能上,無論是在流式 SQL 還是批 SQL,我們的版本在性能上都有很大的優勢。特別是在批 SQL 的性能方面,當前 Blink 版本是社區版本性能的 10 倍以上,跟 Spark 相比,在 TPCDS 這樣的場景 Blink 的性能也能達到 3 倍以上。如果用戶對批處理或者對 SQL 有著比較強的需求,我們這個版本會用戶可以得到很多好處。
Blink 在阿里內部的應用
我:請介紹一下 Blink 在阿里內部的使用情況。目前 Blink 在阿里的大數據架構中扮演什么樣的角色?在阿里內部主要用于哪些業務和應用場景?
蔣曉偉:現在阿里的大數據平臺上,所有的實時計算都已經在使用 Blink;同時,除了實時計算以外,在一些流批一體化的場景也會用 Blink 來做批處理;我們在機器學習場景也有一個探索,叫做 Alink,這個項目是對 Flink Machine Learning Library 的改進,其中實現了大量的算法,都是基于 Flink 做實時機器學習的算法,Alink 在很多場景已經被證明在規模上有很大的優勢。同時,我們在圖計算場景也有一些探索。
我:目前阿里內部有多少部門在使用 Blink?
蔣曉偉:前段時間我們剛剛做過統計,阿里的技術部門大約有 70% 都在使用 Blink。Blink 一直是在用戶的反饋之中成長起來的,對于內部用戶反饋的數據傾斜、資源使用率、易用性方面的問題,Blink 都做了針對性的改進。
現在 Blink 用的最多的場景主要還是實時計算方面,阿里還有一些業務現在相對比較新,還沒有進入實時計算的領域,等這些業務進入實時計算領域時也會使用 Blink。
在批處理方面,阿里內部也有一個自研的批處理引擎叫做 MaxCompute,MaxCompute 也會擁抱 Flink 生態,在語法和語義上做和 Flink 兼容的工作。未來,整個阿里的計算體系和平臺都會融入同一個生態。
后續規劃
我:接下來阿里對于 Blink 還有哪些規劃?包括技術改進、落地應用、更新維護、社區等幾個方面。
蔣曉偉:從技術上說,今天我們公布了 Flink 在批處理上的成果,接下來,我們會對技術持續投入,我們希望每幾個月就能看到技術上有一個比較大的亮點。下一波亮點應該是機器學習場景。要把機器學習支持好,有一系列的工作要做,包括引擎的功能、性能和易用性。這些工作我們已經在內部的討論和進行之中,接下來幾個月,大家應該會看到一些成果。我們也在和社區討論一些事情。除了機器學習之外,我們在圖計算方面也有一些探索,包括對增量迭代更好的支持。做完這些之后,可以認為 Flink 作為大數據的計算引擎已經比較完備了。
同時,我們也重點去做 Flink 的生態,包括 Flink 與其他系統之間的關系、易用性等。Flink 要真正做好,不僅需要它本身功能強大,還需要把整個生態做得非常強大。這部分我們甚至會跟一些 ISV 合作,看看是不是能夠在 Flink 之上提供更好的解決方案,進一步降低用戶的使用門檻。
在社區方面,我們希望能夠把把 Blink 完全融入 Flink 社區,一起做 Flink 社區的運營,讓 Flink 真正在中國、乃至全世界大規模地使用起來。
在應用方面,實時流計算其實有很多很有潛力的應用場景,但有一些可能大家不是非常熟悉,我們會對這些場景做一些推廣。以實時機器學習為例,它往往能夠給我們帶來比一般的機器學習更大的效果提升。去年,實時強化學習給我們在搜索上帶來了 20% 以上的提升。除此之外,在安全領域(比如實時的 Fraud Detection)、監控報警方面,還有 IoT 領域,實時流計算都有非常廣泛的應用場景。這些 Flink 現在可能已經做了,但是大家還沒有意識到,Flink 能夠給大家帶來這樣的商業上的好處。
我:Blink 開源之后,后續阿里在這基礎上做的變更和更新會以什么樣的方式推回社區版本?
蔣曉偉:我們理想的方式是,阿里內部的版本是社區的 Flink 版本加上一些定制化的插件,不需要對 Flink 本身做修改,而是對 Flink 做增加。比如跟阿里內部系統交互的部分跟社區是不適用的,就會保持在內部,我們希望這些修改不動 Flink 代碼,而是用插件的方式加在 Flink 上面。最終的方式就是,對于所有公司都有用的修改會在 Flink 代碼本身做修改,使所有使用 Flink 的公司都能從中獲利,而對接阿里內部系統的部分就只在阿里內部使用。
下一代實時流計算引擎之爭
我:先在很多人提到實時流計算引擎,都會拿 Spark 和 Flink 來做對比,您怎么看待下一代實時流計算引擎之爭?未來實時流計算引擎最重要的發展方向是什么?
蔣曉偉:Spark 和 Flink 一開始 share 了同一個夢想,他們都希望能夠用同一個技術把流處理和批處理統一起來,但他們走了完全不一樣的兩條路,前者是用以批處理的技術為根本,并嘗試在批處理之上支持流計算;后者則認為流計算技術是最基本的,在流計算的基礎之上支持批處理。正因為這種架構上的不同,今后二者在能做的事情上會有一些細微的區別。比如在低延遲場景,Spark 基于微批處理的方式需要同步會有額外開銷,因此無法在延遲上做到極致。在大數據處理的低延遲場景,Flink 已經有非常大的優勢。經過我們的探索, Flink 在批處理上也有了比較大的突破,這些突破都會反饋回社區。當然,對于用戶來說,多一個選擇永遠是好的,不同的技術可能帶來不同的優勢,用戶可以根據自己業務場景的需求進行選擇。
未來,在大數據方向,機器學習正在逐漸從批處理、離線學習向實時處理、在線學習發展,而圖計算領域同樣的事情也在發生,比如實時反欺詐通常用圖計算來做,而這些欺詐事件都是實時地、持續不斷地發生,圖計算也在變得實時化。
但是 Flink 除了大數據領域以外,在應用和微服務的場景也有其獨特的優勢。應用和微服務場景對延遲的要求非常苛刻,會達到百毫秒甚至十毫秒級別,這樣的延遲只有 Flink 的架構才能做到。我認為應用和微服務其實是非常大的領域,甚至可能比大數據更大,這是非常激動人心的機會。上面這些都是我們希望能夠拓寬的應用領域。
我:在技術方面,Spark 和 Flink 其實是各有千秋,但在生態和背后支持的公司上面,Flink 是偏弱的,那么后續在生態和企業支持這塊,阿里會如何幫助 Flink?
蔣曉偉:這次阿里舉辦 Flink Forward China 就是想推廣 Flink 生態的重要舉動之一。除了 Flink Forward China 大會,我們還會不定期舉辦各種線下 Meetup,投入大量精力打造中文社區,包括將 Flink 的英文文檔翻譯成中文、打造 Flink 中文論壇等。在垂直領域,我們會去尋找一些合作伙伴,將 Flink 包裝在一些解決方案中提供給用戶使用。
我:關于開源項目的中立性問題。阿里現在在大力地推動 Flink 開源項目的應用和社區的發展,但業界其他公司(尤其是與阿里在其他業務上可能有競爭的公司)在考慮是否采用 Flink 的時候可能還是會對社區的中立性存在一些疑慮,對于這一點,阿里是怎么考慮的?
蔣曉偉:阿里本身會投入非常大的力量推動 Flink 社區的發展和壯大,但我們也非常希望有更多企業、更多人加入社區,和阿里一起推動社區發展,這次阿里承辦 Flink Forward China 峰會就是想借此機會讓更多公司參與進來。光阿里一家是無法把 Flink 生態做起來的。我希望大家能夠看到我們在做的事情,然后消除這樣的疑慮。我們會用自己的行動表明,我們是真的希望把 Flink 的社區做大,在這件事情上,我們并不會有私心。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





