溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Lambda架構說起來也很簡單,就是通過分布式系統的組件搭建,設計出一個具有魯棒性,可擴展,低延時的分布式計算系統。之所以稱之為Lambda架構,就是它最為核心的點就是理由了數據處理過程之中的不可變性與無依賴性。
Lambda架構說起來也很簡單,就是通過分布式系統的組件搭建,設計出一個具有魯棒性,可擴展,低延時的分布式計算系統。之所以稱之為Lambda架構,就是它最為核心的點就是理由了數據處理過程之中的不可變性與無依賴性。
首先我們來看看什么是Lambda架構,Lambda演算在編程語言之中是一個編程范式,它遵循如下幾個特點:
? 數據的不可變性,任何對于數據的操作是沒有副作用。
? 數據的無依賴性,即對函數提供同樣的輸入,那么函數總是返回同樣的結果。
函數是First Class,函數與其他數據類型一樣,處于平等地位,可以賦值給其他變量,也可以作為參數,傳入另一個函數,或者作為別的函數的返回值。

來自Twitter的Nathan Marz,Marz認為進行計算處理的大數據框架的本質邏輯與函數式編程的思路是不謀而合,所以Marz根據自己多年進行分布式數據系統開發的經驗總結提出了Lambda架構。(Marz大神是AFS頂級項目Storm的作者,Storm作為一個優秀的分布式流處理系統)所以接下來我們來看看Marz所提出的Lambda架構是怎么樣:
Lambda架構說起來也很簡單,就是通過分布式系統的組件搭建,設計出一個具有魯棒性,可擴展,低延時的分布式計算系統。之所以稱之為Lambda架構,就是它最為核心的點就是理由了數據處理過程之中的不可變性與無依賴性。下圖展現了一個典型的Lambda架構的分層邏輯:
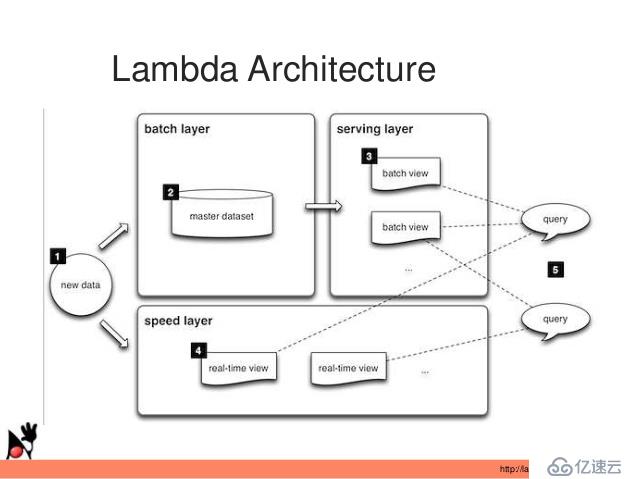
由上圖可以看到,一個典型的Lambda架構的核心分為三個層次:Batch Layer,Speed Layer和Serving Layer。
Batch Layer
Speed Layer
Serving Layer
我們來梳理一下他們是如何分工協助的:首先new data作為整個數據系統的數據源頭,Batch Layer作為數據的批處理層次對原始數據進行加工與處理,并且將處理的數據結果的Batch View輸入到Serving Layer。(這里對應的是全量數據)
Speed Layer對于實時增加的數據進行處理,生成對增量數據計算結果的Realtime Views。(這里對應的是增量數據)
最終用戶查詢是通過Batch View與Realtime View相結合的形式將最終結果呈現出來。
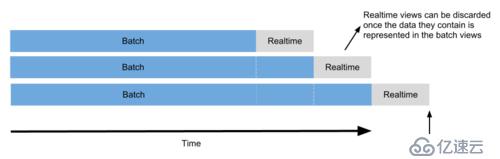
并且隨著時間的推移,Batch View的計算結果會逐漸替代Realtime View,而業務層可以低延遲的訪問由Serving Layer提供的Batch View,也可以通過Realtime View實時反饋業務結果。
我們可以看到在Lambda架構之中,所有的數據都需要滿足滿足不可變性與無依賴性,出現任何數據問題時,(如出錯,丟失等)只需要重新跑一遍算法就可以恢復所需的數據了。
下面筆者利用一個業務場景簡單闡述一下Lambda模式,如下的業務場景只是基于筆者對電商推薦的理解所表述的,對應電商未必實際之中就是采取筆者所闡述的模式:
1:下圖是筆者訪問x寶網首頁所展示的廣告頁面:
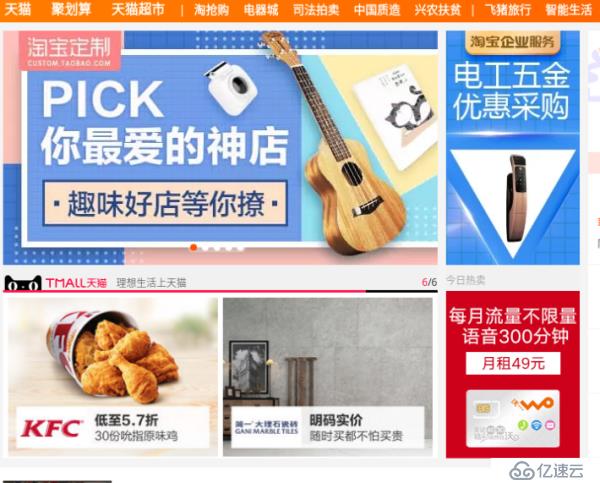
對于這個推薦數據,可以理解為通過Batch Layer對我個人歷史數據進行處理之后得出的Batch View推薦。(例如跑Spark Mllib或是Hadoop Mahout對歷史數據進行分析推薦的結果,跑這類算法通常費時費力,可以通過提前計算的方式存入MySQL等,后續用戶訪問時可以直接調用)
2:接下來筆者在x寶網搜索了MacBook pro和ThinkPad x207,對于實時搜索的數據,可以作為流數據實時的通過Speed Layer進行處理。(例如Storm這樣的流處理器)
3: 筆者切換回到x寶網的首頁,發現多了一個推薦廣告項目:Dell 8代CPU專業級顯卡,曬單還送愛奇藝半年卡。顯然實時流的Realtime View與Batch View共同組成的x寶網的推薦首頁內容,很好的反饋了用戶的實時需求:
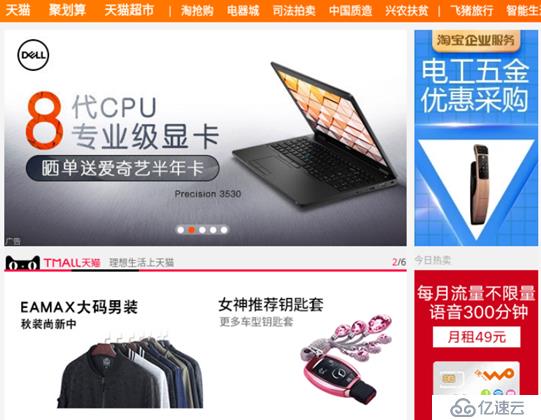
Lambda架構結合了實時處理與批處理的結果,很好的反饋了查詢需求,并且在速度和可靠性之間求取了平衡,具有足夠的擴展性。在Lambda架構之中,所有的查詢都可以定位成一個函數:
而Lambda架構將數據和計算系統進行細分:
但是這種架構同樣存在一些問題:需要運維兩套不同的計算系統,并且合并查詢結果,這一定程序上帶來了復雜性的增加
Lambda架構誕生之后,來自Linkedln的技術主管Jay Kreps提出了一些質疑,并在Lambda架構之上提出自己的改進版本,將其命名為Kappa架構。
Lambda架構最麻煩的問題就在于:新的邏輯需要兩次編碼,并且在兩個系統中運行和調試代碼,需要多運維一個額外的系統。所以Kreps認為Lambda架構試圖在兩個不同編程范式的頂部建立一個抽象層是非常難的。
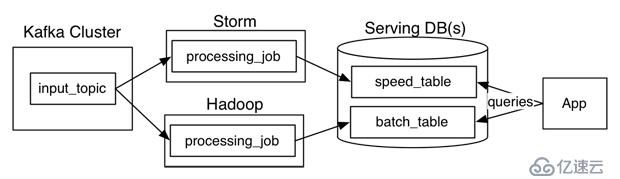
而Kappa架構嘗試通過一個流處理系統來處理上述兩種邏輯,我們來看看Kappa架構是怎么樣去設計的:
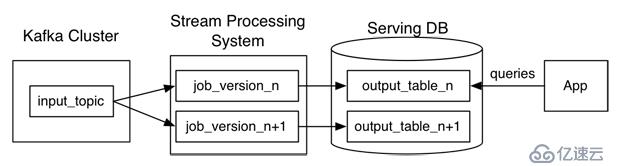
Kappa架構通過流處理系統的并行機制,來提高并行以實現重復處理。但是很多人會覺得流式處理對于歷史數據的高吞吐量會力不從心,這里Kreps給出的解決方案是:僅僅重復處理的完整日志數據。加入需要重復處理30天數據,就利用Kafka保留到30天。
所以這里是開辟另個流式處理來處理新的數據,輸出數據是直接輸出到一個新的輸出表。當這第二個流式處理完成之后,切換到新的表中進行讀取,然后停止舊的流式處理,再刪除舊的輸出表。
同樣的,筆者上文舉的例子,同樣也能通過Kappa架構來實現購物的廣告展示。Kappa架構最為核心的是通過一個范式解決需要共同解決的問題。同時不需要引入額外計算系統進行運維。
到此為止,筆者也大致聊完兩種不同分布式計算系統的架構。筆者認為Lambda架構是一個優秀的解決分布式計算的架構,但需要處理運維不同的大數據系統,并且額外編碼邏輯,對于開發者與運維人員都是一個較大的考驗。而Kappa架構簡化了這個模型,但是對于數據處理總歸很難拿出重型的批處理做一個完整數據計算,所以計算結果的準確性是有所限縮的。(也就是對于業務場景是挑剔的,我想也沒有一種架構是解決問題的銀彈,之間的取舍需要我們開發人員進行完整的評估~~)
而Spark能夠通過一個計算框架同時解決批處理計算與流計算的問題,是很值得開發與運維人員所關注的.......
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





