溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何生成HASH索引防止數據重復插入,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
例如:我們有一張表,其中id是自增的并且和業務沒有任何關系,而這張表如果需要一個唯一值來確認每行數據的唯一性,則可以采用數據摘要算法,來在數據庫的層面解決某些唯一值生成的問題。
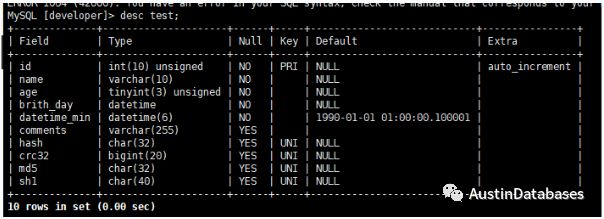
這里可以利用的算法很多,如CRC32 , MD5 ,SHA1 等,他們都能根據輸入的數據,進行計算后,產生一個在一定范圍唯一的值,通過這個唯一值來鑒定此行數據的唯一性。
這里的算法有幾種可以選擇,例如 CRC32 這個算法一般是使用在通訊的數據校驗完整性中產生一個10位的唯一值,MD5 算法是一種信息摘要的算法,它產生一個32位十六進制數,在互聯網中傳輸大型文件,都是要靠MD5來計算驗證碼,保證數據傳輸的完整性和正確性。SHA1 是由美國制定的一套密碼算法,通過它來進行數據密碼算法,SHA1,會產生一個十六位40位的密碼。
我們可以根據我們的需求來進行相關算法的使用,來判定我們一行數據的唯一性。
這里做測試建立了一些唯一索引,使用不同的算法生成唯一值。

們已經有了相關的數據,我們在插入一個相同的數據
接報錯,當然它一定應該報錯的。

可能有人馬上問,這解決了什么問題,我把那堆字段建立一個聯合的唯一索引不就完了,也一樣。
真是單純,我至少可以說出我的方法比你上面好的 4種優點。其實一種就夠了,我的索引比你小。
如果你回答,這也算一個優點,大點會怎樣,我只能又笑了
同時從索引B+樹的存儲方式和應用程序對數據庫每條記錄唯一的要求,這樣做都有有好處的。
OK 這樣的方法不光可以在MYSQL上使用,還可以使用在各種數據庫中,通過這樣的方法可以加速數據的提取,并且快速的在數據庫表中生成一道完整的防御重復記錄插入的方案。當然也有缺點
當你的數據插入量較多,則數據轉換成“特殊值”的方法可能是一個產生插入數據速度的一個瓶頸,如果數據量插入的不是很大的情況下并且對數據的唯一性有嚴格的要求,則使用MD5 則是比較好的方法,而如果僅僅是為了查詢提速,則可以使用CRC32的方法,雖然數據量達到千萬級可能有“撞庫” 的可能,但可以抵消多字段聯合索引帶來的性能問題,又何樂不為。
他的另一個致命缺點呢?這里就不在提及了。
看完上述內容,你們掌握如何生成HASH索引防止數據重復插入的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





