溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關機器學習中怎么評估分類效果,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
給你一個問題,假如老板讓另一個同事去檢查一萬張紙幣中,有多少是真幣,有多少是假幣,然后這個同事給老板匯報了結果:這一萬張紙幣中,有2千張是真幣,有8千張是假幣。現在,老板讓你來評估這個同事的匯報結果,你會怎么做?
你重新把一萬張紙幣再用機器過一遍再做對比,或者把這個同事的2千張真幣與8千張假幣再過一遍,這都是可以的。但是,假如不允許你這樣做呢,比如一萬張紙幣變成了1百萬張,不可能給你時間再全部來一遍,那你怎么做?
抽查啊。
似乎就這一招,那么要怎么抽查才能合理地評估同事匯報的結果呢?
一般的做法是這樣的,先在2千張真幣上抽查:“你說這些都是真幣,哪到底有多少是真的呢?” 這個比例,在數據分析中,叫Precision,精度或精準度。如果100%是真的,那當然是最好的。但即使精準度是100%,也不能說明這個匯報結果就ok了,因為,另外8千張“假幣”中也有可能全是真幣啊。
所以,還要在8千張假幣中抽查:“你說都是假的,哪到底有多少是假的呢?” 這個比例,也能說明問題,假如抽了一百張,結果有90張都是真幣(只有10%真是假幣),那說這8千張都是假幣就顯得很不可信。這個比例,小程覺得它也叫作精準度,就是“你說的假中,到底有多少是假”,值越大越好。
那除了精準度,是不是就夠了呢?
看起來是夠了,因為,精準度反應了“判是非”的能力。以上面的例子來說,比如判斷為真幣的精度是98%,那就意味著只有2%的假幣被誤判為真幣了,所以我把假幣判斷為真幣的可能性是很低的(假設2%在業界是很低的:-)。再比如,假設判斷為假幣的精度是95%,那就意味著只有5%的真幣給誤判成假幣了。在這種情況下,把假的判斷成真的,或把真的判斷成假的,比例都很低。這不就完了嗎?這說明“判是非”的能力很強啊,這個預測系統是可信的啊,它不會把真假誤判啊,你給它一堆紙幣,它就能給你分辨真假,不會出錯啊。
但是,這里有一個前提,這個系統要在判斷后,你才知道是不是判斷對了。如果這個系統對所有紙幣都不判斷,或者者1萬張紙幣中只判斷了1千張,那你還指望它做什么?它是很準啊,但是,它只有判斷出來的才很準,還有很多是沒有判斷出來的!但話說回來,其實只要很準(精度高),就有使用市場的,這個后面再說。
所以,這里還有一個指標,叫Sensitivity靈敏度,也叫Recall召回率。
召回率,反映了“找回”的能力,比如我給系統1千張真幣,它能找出800張真幣,那80%就是召回率。如果它的召回率是10%,那說明只找回了100張,還有900張是怎么回事?這時,有兩個可能,一是判斷不出來,比如這900張我就是判斷不出來,所以就找不回來,另一個可能,就是誤判了,比如900張我都誤判為假幣了。但是,誤判說明什么?誤判說明精度差啊,所以如果精度很高,那就只有一種可能,就是判斷不出來。
所以,精度跟召回率都要看,精度反應了靠不靠譜(說什么是什么),召回率反應了能不能找到數據(覆蓋了多少樣本)。
不管是精度還是召回率,都只是一個數字,而為了得到這個數字,一般都是經過很多樣本的預測考驗才得出來的,所以把這些樣本都反應出來就顯得很必要了,這表明,我的“率”是有由來的。這時候,“混淆矩陣”就出場了。
混淆矩陣,也叫差錯矩陣,名字都是從鬼文翻譯過來的(由此可見,含義才是最重要的,鬼知道翻譯到的是什么)。混淆矩陣是一張表格,一邊是真實值,一邊是預測值,橫豎怎么擺都行,看下面這個圖就明白了:
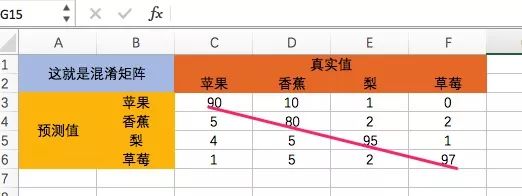
“混淆”表明了分類的能力,以上圖為例,蘋果的召回率(在一堆蘋果中能撈回多少蘋果的能力)是:90/(90+5+4+1)=90%,而香蕉、梨與草莓的召回率分別為80%、95%、97%。小程每個分類剛好用了100個真實值,為了方便心算能力不好的你。由此可見,右對角線上的值就是召回值,也就是判斷準確的值。
再看精度,這里行表示了精度,比如蘋果的精度是:90/(90+10+1+0)=89%,香蕉的精度是:80/(5+80+2+2)=89.9%,梨跟草莓分別是90.4%、92.4%。
然后,召回率跟精度一起來看,
蘋果、 香蕉、 梨、 草莓
90% 80% 95% 97%
89% 89.9% 90.4% 92.4%
草莓的召回率跟精度都是最高的,讓我們恭喜它!
除了召回率跟精度,對于分類器(上面預測蘋果香蕉就是分類器)效果評估,還有兩個指標,一個叫總的準確率,就是拿判斷準確的值(右對角線上的值)相加,再除以總的樣本數量,這里就是(90+80+95+97)/400=90.5%,另一個叫特異度,比如對于蘋果,就是真的不是蘋果的樣本中,判斷不是蘋果的比例。但小程覺得這兩個指標的參考意義不大。
從一張樣本表,抽象出每個分類的召回率跟精度,如果再把抽象一下,就是每個分類的F1Score,它是召回率跟精度的整合:F1Score=2*精度*召回/(精度+召回),上面的例子,蘋果的F1Score=2*90%*89%/(90%+89%)=89.49%。
基本上,也就是用精度、召回率來描述分類器的質量了,最多再加個F1Score。
讓我們再深入一點,問你一個問題,精度高可以用于什么場景?召回率高又可以用于什么場景?
精度高,就是不出錯啰,說是什么就是什么,那可以用于分類,比如給一批樣本過來,樣本里面有ABCD幾個分類,精度高的情況下,就可以指出哪些樣本是A,哪些樣本是B,等等。如果精度高,但召回率低,一樣可以用于分類,只是,有很多A類的樣本沒有找出來(誰讓你判斷不出來),其它分類也一樣。
召回率高,但精度低,那就是分類是不靠譜的,說是A結果可能是B,那就不要分類了,這時,因為召回率高,那可以用于篩選已有的分類,比如說有一批樣本基本是A類,只是里面可能有一些B跟C,那就可以用這個分類器來篩選了,相當于糾錯,因為召回率高,所以基本把A給找回來,其它的扔掉。
召回率高,精度也高,也既可用于分類,也可用于已有分類(真的分好了的)的篩選。
那如果召回率低,精度也低呢?那就是廢的,用人工好了!
關于“機器學習中怎么評估分類效果”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





